 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-explaining Hierarchical Model for Intraoperative Time Series
Oct 10, 2022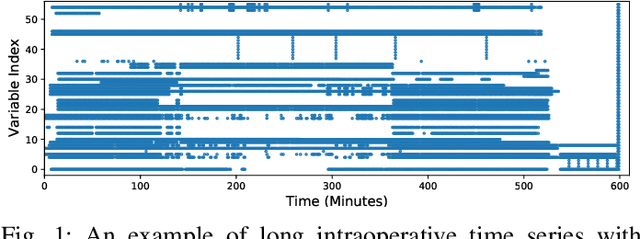
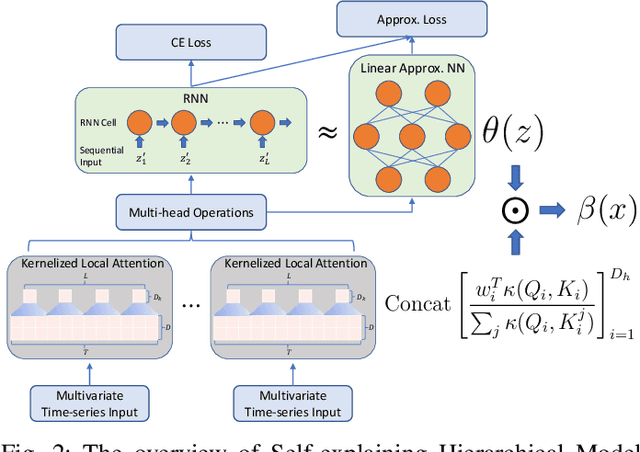
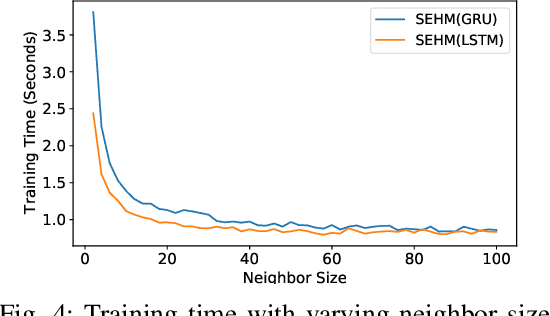
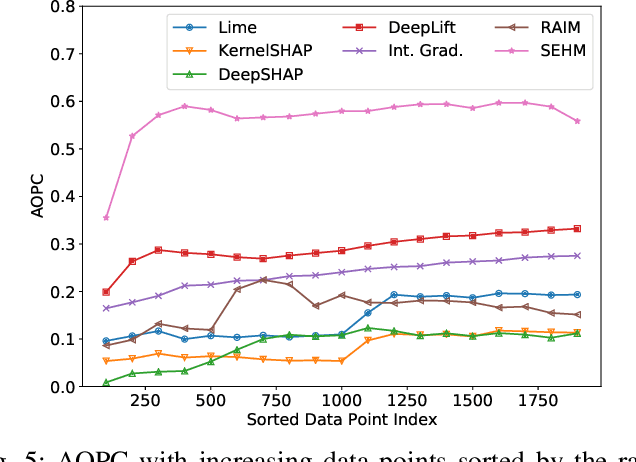
Major postoperative complications are devastating to surgical patients. Some of these complications are potentially preventable via early predictions based on intraoperative data. However, intraoperative data comprise long and fine-grained multivariate time series, prohibiting the effective learning of accurate models. The large gaps associated with clinical events and protocols are usually ignored. Moreover, deep models generally lack transparency. Nevertheless, the interpretability is crucial to assist clinicians in planning for and delivering postoperative care and timely interventions. Towards this end, we propose a hierarchical model combining the strength of both attention and recurrent models for intraoperative time series. We further develop an explanation module for the hierarchical model to interpret the predictions by providing contributions of intraoperative data in a fine-grained manner. Experiments on a large dataset of 111,888 surgeries with multiple outcomes and an external high-resolution ICU dataset show that our model can achieve strong predictive performance (i.e., high accuracy) and offer robust interpretations (i.e., high transparency) for predicted outcomes based on intraoperative time series.
A Modulation Layer to Increase Neural Network Robustness Against Data Quality Issues
Jul 19, 2021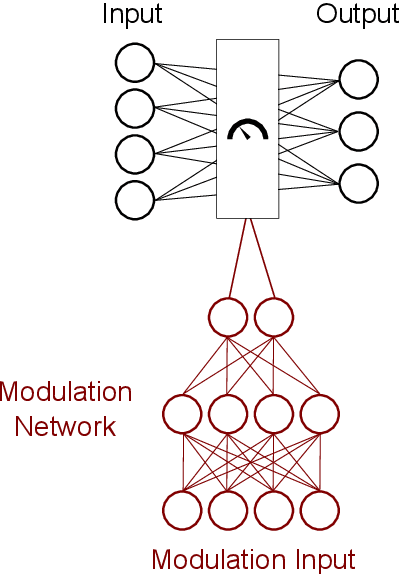
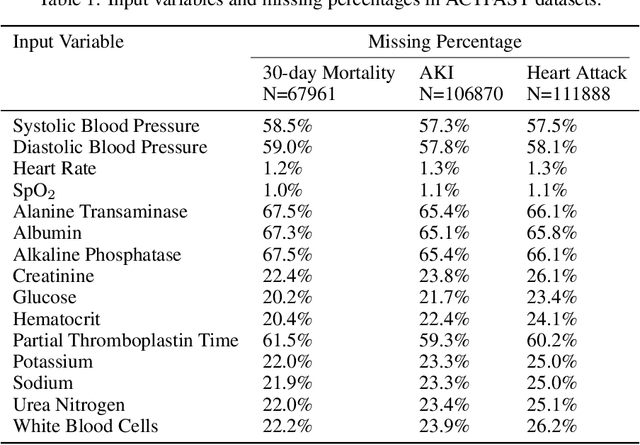
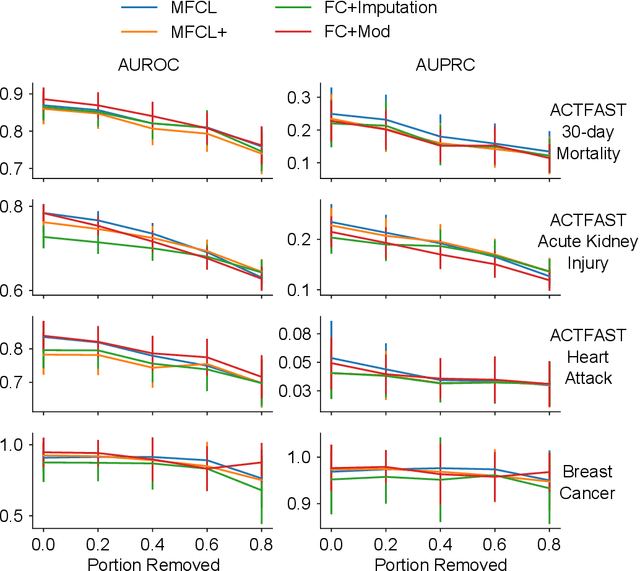

Data quality is a common problem in machine learning, especially in high-stakes settings such as healthcare. Missing data affects accuracy, calibration, and feature attribution in complex patterns. Developers often train models on carefully curated datasets to minimize missing data bias; however, this reduces the usability of such models in production environments, such as real-time healthcare records. Making machine learning models robust to missing data is therefore crucial for practical application. While some classifiers naturally handle missing data, others, such as deep neural networks, are not designed for unknown values. We propose a novel neural network modification to mitigate the impacts of missing data. The approach is inspired by neuromodulation that is performed by biological neural networks. Our proposal replaces the fixed weights of a fully-connected layer with a function of an additional input (reliability score) at each input, mimicking the ability of cortex to up- and down-weight inputs based on the presence of other data. The modulation function is jointly learned with the main task using a multi-layer perceptron. We tested our modulating fully connected layer on multiple classification, regression, and imputation problems, and it either improved performance or generated comparable performance to conventional neural network architectures concatenating reliability to the inputs. Models with modulating layers were more robust against degradation of data quality by introducing additional missingness at evaluation time. These results suggest that explicitly accounting for reduced information quality with a modulating fully connected layer can enable the deployment of artificial intelligence systems in real-time settings.