 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Bias in Machine Learning Based Delirium Prediction
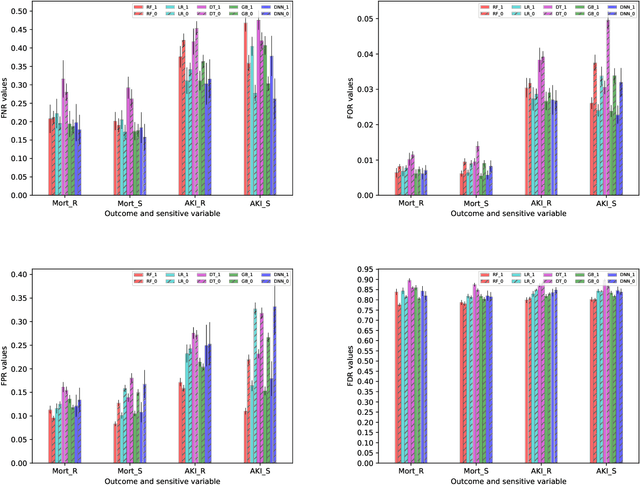
Nov 08, 2022Although prediction models for delirium, a commonly occurring condition during general hospitalization or post-surgery, have not gained huge popularity, their algorithmic bias evaluation is crucial due to the existing association between social determinants of health and delirium risk. In this context, using MIMIC-III and another academic hospital dataset, we present some initial experimental evidence showing how sociodemographic features such as sex and race can impact the model performance across subgroups. With this work, our intent is to initiate a discussion about the intersectionality effects of old age, race and socioeconomic factors on the early-stage detection and prevention of delirium using ML.
A Modulation Layer to Increase Neural Network Robustness Against Data Quality Issues
Jul 19, 2021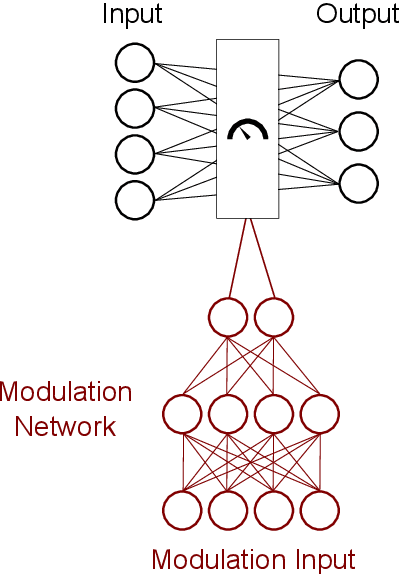
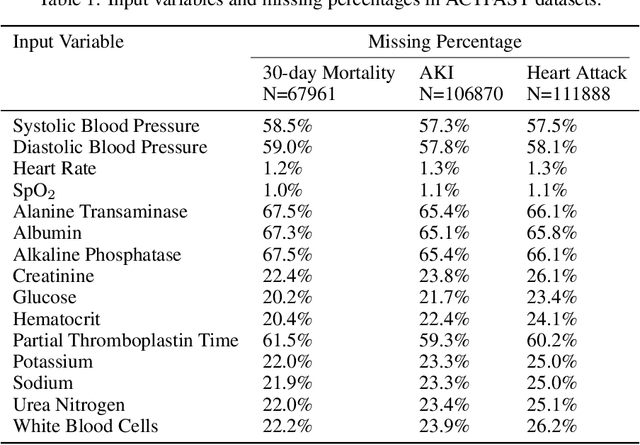
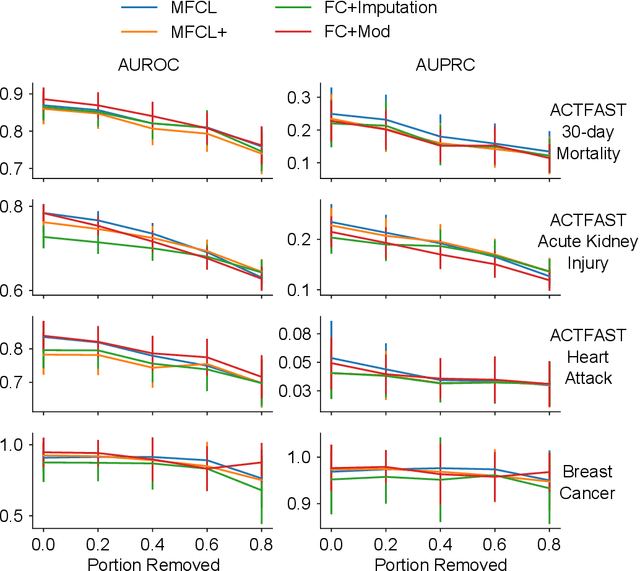

Data quality is a common problem in machine learning, especially in high-stakes settings such as healthcare. Missing data affects accuracy, calibration, and feature attribution in complex patterns. Developers often train models on carefully curated datasets to minimize missing data bias; however, this reduces the usability of such models in production environments, such as real-time healthcare records. Making machine learning models robust to missing data is therefore crucial for practical application. While some classifiers naturally handle missing data, others, such as deep neural networks, are not designed for unknown values. We propose a novel neural network modification to mitigate the impacts of missing data. The approach is inspired by neuromodulation that is performed by biological neural networks. Our proposal replaces the fixed weights of a fully-connected layer with a function of an additional input (reliability score) at each input, mimicking the ability of cortex to up- and down-weight inputs based on the presence of other data. The modulation function is jointly learned with the main task using a multi-layer perceptron. We tested our modulating fully connected layer on multiple classification, regression, and imputation problems, and it either improved performance or generated comparable performance to conventional neural network architectures concatenating reliability to the inputs. Models with modulating layers were more robust against degradation of data quality by introducing additional missingness at evaluation time. These results suggest that explicitly accounting for reduced information quality with a modulating fully connected layer can enable the deployment of artificial intelligence systems in real-time settings.
(Un)fairness in Post-operative Complication Prediction Models
Nov 03, 2020
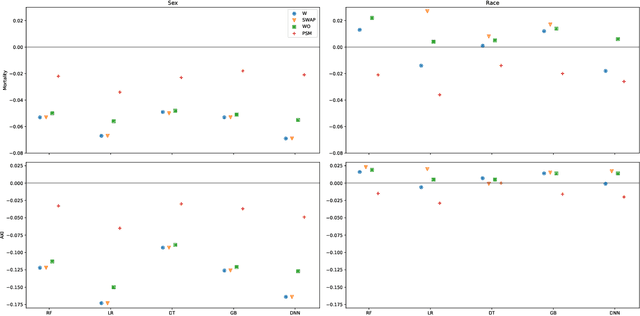

With the current ongoing debate about fairness, explainability and transparency of machine learning models, their application in high-impact clinical decision-making systems must be scrutinized. We consider a real-life example of risk estimation before surgery and investigate the potential for bias or unfairness of a variety of algorithms. Our approach creates transparent documentation of potential bias so that the users can apply the model carefully. We augment a model-card like analysis using propensity scores with a decision-tree based guide for clinicians that would identify predictable shortcomings of the model. In addition to functioning as a guide for users, we propose that it can guide the algorithm development and informatics team to focus on data sources and structures that can address these shortcomings.
GANs for learning from very high class conditional noisy labels
Oct 19, 2020



We use Generative Adversarial Networks (GANs) to design a class conditional label noise (CCN) robust scheme for binary classification. It first generates a set of correctly labelled data points from noisy labelled data and 0.1% or 1% clean labels such that the generated and true (clean) labelled data distributions are close; generated labelled data is used to learn a good classifier. The mode collapse problem while generating correct feature-label pairs and the problem of skewed feature-label dimension ratio ($\sim$ 784:1) are avoided by using Wasserstein GAN and a simple data representation change. Another WGAN with information-theoretic flavour on top of the new representation is also proposed. The major advantage of both schemes is their significant improvement over the existing ones in presence of very high CCN rates, without either estimating or cross-validating over the noise rates. We proved that KL divergence between clean and noisy distribution increases w.r.t. noise rates in symmetric label noise model; can be extended to high CCN rates. This implies that our schemes perform well due to the adversarial nature of GANs. Further, use of generative approach (learning clean joint distribution) while handling noise enables our schemes to perform better than discriminative approaches like GLC, LDMI and GCE; even when the classes are highly imbalanced. Using Friedman F test and Nemenyi posthoc test, we showed that on high dimensional binary class synthetic, MNIST and Fashion MNIST datasets, our schemes outperform the existing methods and demonstrate consistent performance across noise rates.
On Feature Interactions Identified by Shapley Values of Binary Classification Games
Jan 12, 2020


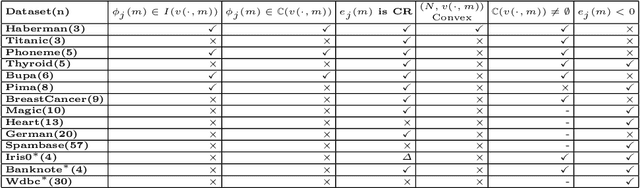
For feature selection and related problems, we introduce the notion of classification game, a cooperative game, with features as players and hinge loss based characteristic function and relate a feature's contribution to Shapley value based error apportioning (SVEA) of total training error. Our major contribution is ($\star$) to show that for any dataset the threshold 0 on SVEA value identifies feature subset whose joint interactions for label prediction is significant or those features that span a subspace where the data is predominantly lying. In addition, our scheme ($\star$) identifies the features on which Bayes classifier doesn't depend but any surrogate loss function based finite sample classifier does; this contributes to the excess $0$-$1$ risk of such a classifier, ($\star$) estimates unknown true hinge risk of a feature, and ($\star$) relate the stability property of an allocation and negative valued SVEA by designing the analogue of core of classification game. Due to Shapley value's computationally expensive nature, we build on a known Monte Carlo based approximation algorithm that computes characteristic function (Linear Programs) only when needed. We address the potential sample bias problem in feature selection by providing interval estimates for SVEA values obtained from multiple sub-samples. We illustrate all the above aspects on various synthetic and real datasets and show that our scheme achieves better results than existing recursive feature elimination technique and ReliefF in most cases. Our theoretically grounded classification game in terms of well defined characteristic function offers interpretability and explainability of our framework, including identification of important features.
Attribute noise robust binary classification
Nov 18, 2019



We consider the problem of learning linear classifiers when both features and labels are binary. In addition, the features are noisy, i.e., they could be flipped with an unknown probability. In Sy-De attribute noise model, where all features could be noisy together with same probability, we show that $0$-$1$ loss ($l_{0-1}$) need not be robust but a popular surrogate, squared loss ($l_{sq}$) is. In Asy-In attribute noise model, we prove that $l_{0-1}$ is robust for any distribution over 2 dimensional feature space. However, due to computational intractability of $l_{0-1}$, we resort to $l_{sq}$ and observe that it need not be Asy-In noise robust. Our empirical results support Sy-De robustness of squared loss for low to moderate noise rates.
Cost Sensitive Learning in the Presence of Symmetric Label Noise
Jan 16, 2019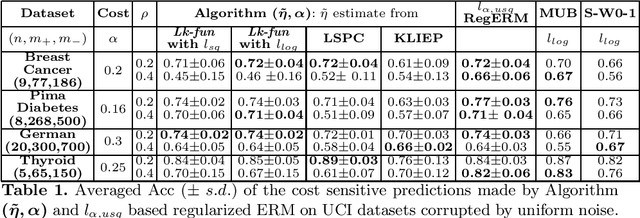



In binary classification framework, we are interested in making cost sensitive label predictions in the presence of uniform/symmetric label noise. We first observe that $0$-$1$ Bayes classifiers are not (uniform) noise robust in cost sensitive setting. To circumvent this impossibility result, we present two schemes; unlike the existing methods, our schemes do not require noise rate. The first one uses $\alpha$-weighted $\gamma$-uneven margin squared loss function, $l_{\alpha, usq}$, which can handle cost sensitivity arising due to domain requirement (using user given $\alpha$) or class imbalance (by tuning $\gamma$) or both. However, we observe that $l_{\alpha, usq}$ Bayes classifiers are also not cost sensitive and noise robust. We show that regularized ERM of this loss function over the class of linear classifiers yields a cost sensitive uniform noise robust classifier as a solution of a system of linear equations. We also provide a performance bound for this classifier. The second scheme that we propose is a re-sampling based scheme that exploits the special structure of the uniform noise models and uses in-class probability estimates. Our computational experiments on some UCI datasets with class imbalance show that classifiers of our two schemes are on par with the existing methods and in fact better in some cases w.r.t. Accuracy and Arithmetic Mean, without using/tuning noise rate. We also consider other cost sensitive performance measures viz., F measure and Weighted Cost for evaluation.