 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Un)fairness in Post-operative Complication Prediction Models
Paper and Code
Nov 03, 2020
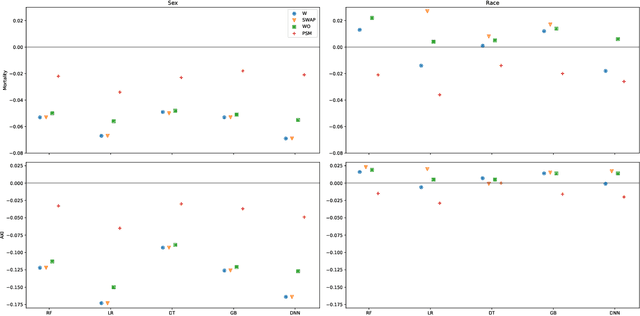
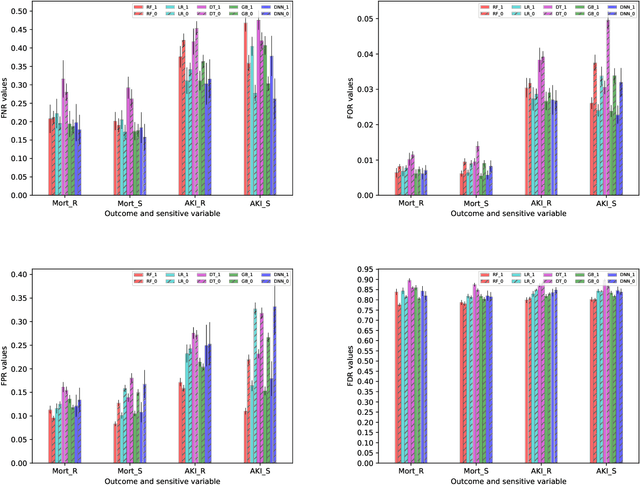

With the current ongoing debate about fairness, explainability and transparency of machine learning models, their application in high-impact clinical decision-making systems must be scrutinized. We consider a real-life example of risk estimation before surgery and investigate the potential for bias or unfairness of a variety of algorithms. Our approach creates transparent documentation of potential bias so that the users can apply the model carefully. We augment a model-card like analysis using propensity scores with a decision-tree based guide for clinicians that would identify predictable shortcomings of the model. In addition to functioning as a guide for users, we propose that it can guide the algorithm development and informatics team to focus on data sources and structures that can address these shortcomings.