 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Crowdsourcing with Accuracy and Cost Guarantees
Jul 05, 2022



We consider the problem of cost-optimal utilization of a crowdsourcing platform for binary, unsupervised classification of a collection of items, given a prescribed error threshold. Workers on the crowdsourcing platform are assumed to be divided into multiple classes, based on their skill, experience, and/or past performance. We model each worker class via an unknown confusion matrix, and a (known) price to be paid per label prediction. For this setting, we propose algorithms for acquiring label predictions from workers, and for inferring the true labels of items. We prove that if the number of (unlabeled) items available is large enough, our algorithms satisfy the prescribed error thresholds, incurring a cost that is near-optimal. Finally, we validate our algorithms, and some heuristics inspired by them, through an extensive case study.
On Feature Interactions Identified by Shapley Values of Binary Classification Games
Jan 12, 2020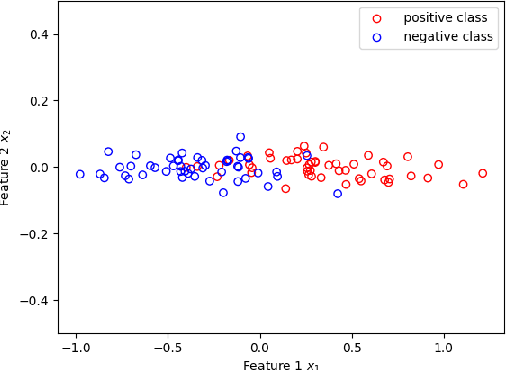


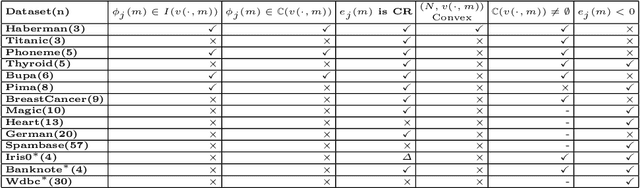
For feature selection and related problems, we introduce the notion of classification game, a cooperative game, with features as players and hinge loss based characteristic function and relate a feature's contribution to Shapley value based error apportioning (SVEA) of total training error. Our major contribution is ($\star$) to show that for any dataset the threshold 0 on SVEA value identifies feature subset whose joint interactions for label prediction is significant or those features that span a subspace where the data is predominantly lying. In addition, our scheme ($\star$) identifies the features on which Bayes classifier doesn't depend but any surrogate loss function based finite sample classifier does; this contributes to the excess $0$-$1$ risk of such a classifier, ($\star$) estimates unknown true hinge risk of a feature, and ($\star$) relate the stability property of an allocation and negative valued SVEA by designing the analogue of core of classification game. Due to Shapley value's computationally expensive nature, we build on a known Monte Carlo based approximation algorithm that computes characteristic function (Linear Programs) only when needed. We address the potential sample bias problem in feature selection by providing interval estimates for SVEA values obtained from multiple sub-samples. We illustrate all the above aspects on various synthetic and real datasets and show that our scheme achieves better results than existing recursive feature elimination technique and ReliefF in most cases. Our theoretically grounded classification game in terms of well defined characteristic function offers interpretability and explainability of our framework, including identification of important features.
Cost Sensitive Learning in the Presence of Symmetric Label Noise
Jan 16, 2019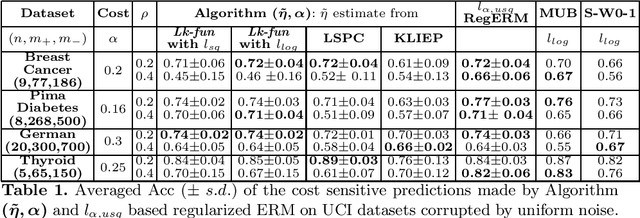



In binary classification framework, we are interested in making cost sensitive label predictions in the presence of uniform/symmetric label noise. We first observe that $0$-$1$ Bayes classifiers are not (uniform) noise robust in cost sensitive setting. To circumvent this impossibility result, we present two schemes; unlike the existing methods, our schemes do not require noise rate. The first one uses $\alpha$-weighted $\gamma$-uneven margin squared loss function, $l_{\alpha, usq}$, which can handle cost sensitivity arising due to domain requirement (using user given $\alpha$) or class imbalance (by tuning $\gamma$) or both. However, we observe that $l_{\alpha, usq}$ Bayes classifiers are also not cost sensitive and noise robust. We show that regularized ERM of this loss function over the class of linear classifiers yields a cost sensitive uniform noise robust classifier as a solution of a system of linear equations. We also provide a performance bound for this classifier. The second scheme that we propose is a re-sampling based scheme that exploits the special structure of the uniform noise models and uses in-class probability estimates. Our computational experiments on some UCI datasets with class imbalance show that classifiers of our two schemes are on par with the existing methods and in fact better in some cases w.r.t. Accuracy and Arithmetic Mean, without using/tuning noise rate. We also consider other cost sensitive performance measures viz., F measure and Weighted Cost for evaluation.