 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRound-trip Reinforcement Learning: Self-Consistent Training for Better Chemical LLMs
Oct 01, 2025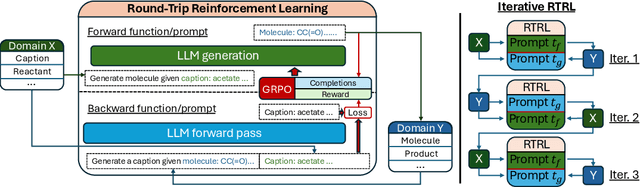
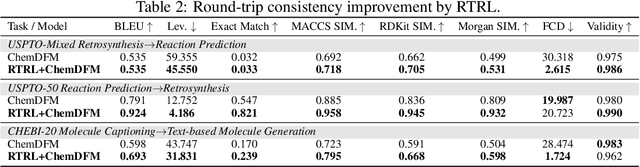
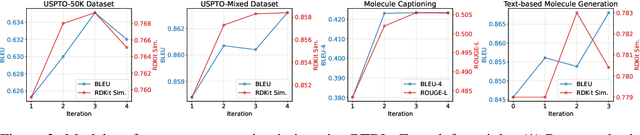
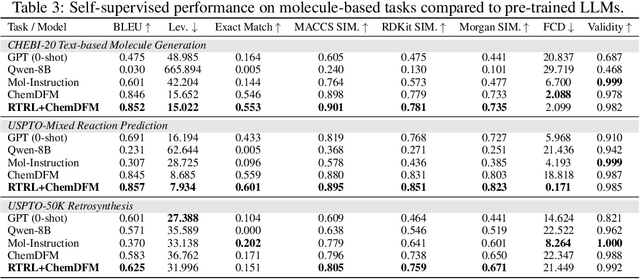
Large Language Models (LLMs) are emerging as versatile foundation models for computational chemistry, handling bidirectional tasks like reaction prediction and retrosynthesis. However, these models often lack round-trip consistency. For instance, a state-of-the-art chemical LLM may successfully caption a molecule, yet be unable to accurately reconstruct the original structure from its own generated text. This inconsistency suggests that models are learning unidirectional memorization rather than flexible mastery. Indeed, recent work has demonstrated a strong correlation between a model's round-trip consistency and its performance on the primary tasks. This strong correlation reframes consistency into a direct target for model improvement. We therefore introduce Round-Trip Reinforcement Learning (RTRL), a novel framework that trains a model to improve its consistency by using the success of a round-trip transformation as a reward signal. We further propose an iterative variant where forward and reverse mappings alternately train each other in a self-improvement loop, a process that is highly data-efficient and notably effective with the massive amount of unlabelled data common in chemistry. Experiments demonstrate that RTRL significantly \textbf{boosts performance and consistency} over strong baselines across supervised, self-supervised, and synthetic data regimes. This work shows that round-trip consistency is not just a desirable property but a trainable objective, offering a new path toward more robust and reliable foundation models.
Dynamic Mixture-of-Experts for Incremental Graph Learning
Aug 13, 2025Graph incremental learning is a learning paradigm that aims to adapt trained models to continuously incremented graphs and data over time without the need for retraining on the full dataset. However, regular graph machine learning methods suffer from catastrophic forgetting when applied to incremental learning settings, where previously learned knowledge is overridden by new knowledge. Previous approaches have tried to address this by treating the previously trained model as an inseparable unit and using techniques to maintain old behaviors while learning new knowledge. These approaches, however, do not account for the fact that previously acquired knowledge at different timestamps contributes differently to learning new tasks. Some prior patterns can be transferred to help learn new data, while others may deviate from the new data distribution and be detrimental. To address this, we propose a dynamic mixture-of-experts (DyMoE) approach for incremental learning. Specifically, a DyMoE GNN layer adds new expert networks specialized in modeling the incoming data blocks. We design a customized regularization loss that utilizes data sequence information so existing experts can maintain their ability to solve old tasks while helping the new expert learn the new data effectively. As the number of data blocks grows over time, the computational cost of the full mixture-of-experts (MoE) model increases. To address this, we introduce a sparse MoE approach, where only the top-$k$ most relevant experts make predictions, significantly reducing the computation time. Our model achieved 4.92\% relative accuracy increase compared to the best baselines on class incremental learning, showing the model's exceptional power.
GOFA: A Generative One-For-All Model for Joint Graph Language Modeling
Jul 12, 2024



Foundation models, such as Large Language Models (LLMs) or Large Vision Models (LVMs), have emerged as one of the most powerful tools in the respective fields. However, unlike text and image data, graph data do not have a definitive structure, posing great challenges to developing a Graph Foundation Model (GFM). For example, current attempts at designing general graph models either transform graph data into a language format for LLM-based prediction or still train a GNN model with LLM as an assistant. The former can handle unlimited tasks, while the latter captures graph structure much better -- yet, no existing work can achieve both simultaneously. In this paper, we identify three key desirable properties of a GFM: self-supervised pretraining, fluidity in tasks, and graph awareness. To account for these properties, we extend the conventional language modeling to the graph domain and propose a novel generative graph language model GOFA to solve the problem. The model interleaves randomly initialized GNN layers into a frozen pre-trained LLM so that the semantic and structural modeling abilities are organically combined. GOFA is pre-trained on newly proposed graph-level next-word prediction, question-answering, and structural tasks to obtain the above GFM properties. The pre-trained model is further fine-tuned on downstream tasks to obtain task-solving ability. The fine-tuned model is evaluated on various downstream tasks, demonstrating a strong ability to solve structural and contextual problems in zero-shot scenarios. The code is available at https://github.com/JiaruiFeng/GOFA.
TAGLAS: An atlas of text-attributed graph datasets in the era of large graph and language models
Jun 20, 2024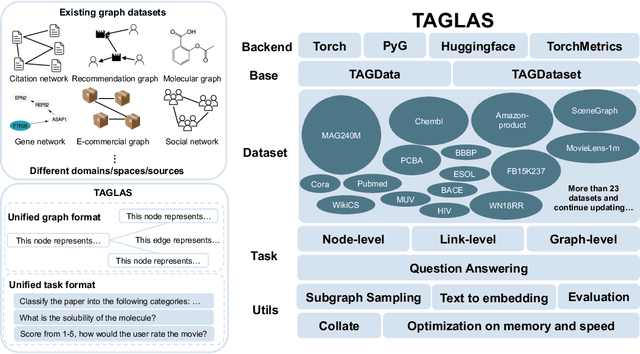
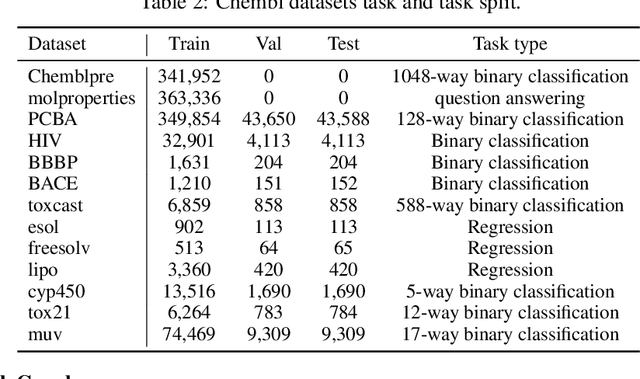
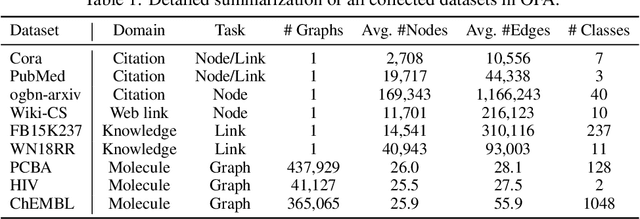
In this report, we present TAGLAS, an atlas of text-attributed graph (TAG) datasets and benchmarks. TAGs are graphs with node and edge features represented in text, which have recently gained wide applicability in training graph-language or graph foundation models. In TAGLAS, we collect and integrate more than 23 TAG datasets with domains ranging from citation graphs to molecule graphs and tasks from node classification to graph question-answering. Unlike previous graph datasets and benchmarks, all datasets in TAGLAS have a unified node and edge text feature format, which allows a graph model to be simultaneously trained and evaluated on multiple datasets from various domains. Further, we provide a standardized, efficient, and simplified way to load all datasets and tasks. We also provide useful utils like text-to-embedding conversion, and graph-to-text conversion, which can facilitate different evaluation scenarios. Finally, we also provide standard and easy-to-use evaluation utils. The project is open-sourced at https://github.com/JiaruiFeng/TAGLAS and is still under construction. Please expect more datasets/features in the future.
MAG-GNN: Reinforcement Learning Boosted Graph Neural Network
Oct 29, 2023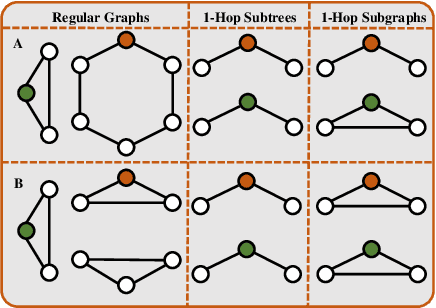
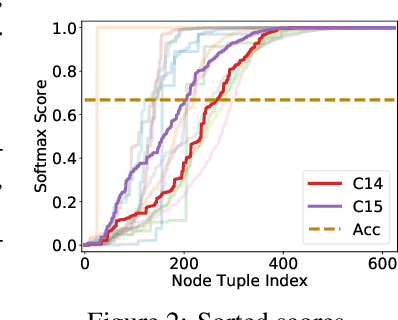
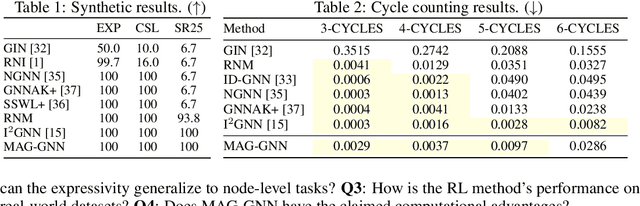
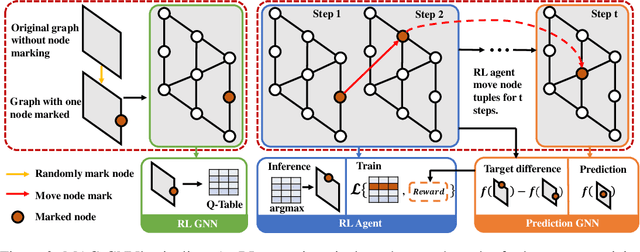
While Graph Neural Networks (GNNs) recently became powerful tools in graph learning tasks, considerable efforts have been spent on improving GNNs' structural encoding ability. A particular line of work proposed subgraph GNNs that use subgraph information to improve GNNs' expressivity and achieved great success. However, such effectivity sacrifices the efficiency of GNNs by enumerating all possible subgraphs. In this paper, we analyze the necessity of complete subgraph enumeration and show that a model can achieve a comparable level of expressivity by considering a small subset of the subgraphs. We then formulate the identification of the optimal subset as a combinatorial optimization problem and propose Magnetic Graph Neural Network (MAG-GNN), a reinforcement learning (RL) boosted GNN, to solve the problem. Starting with a candidate subgraph set, MAG-GNN employs an RL agent to iteratively update the subgraphs to locate the most expressive set for prediction. This reduces the exponential complexity of subgraph enumeration to the constant complexity of a subgraph search algorithm while keeping good expressivity. We conduct extensive experiments on many datasets, showing that MAG-GNN achieves competitive performance to state-of-the-art methods and even outperforms many subgraph GNNs. We also demonstrate that MAG-GNN effectively reduces the running time of subgraph GNNs.
One for All: Towards Training One Graph Model for All Classification Tasks
Sep 29, 2023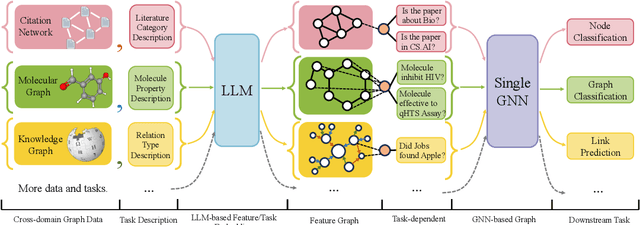
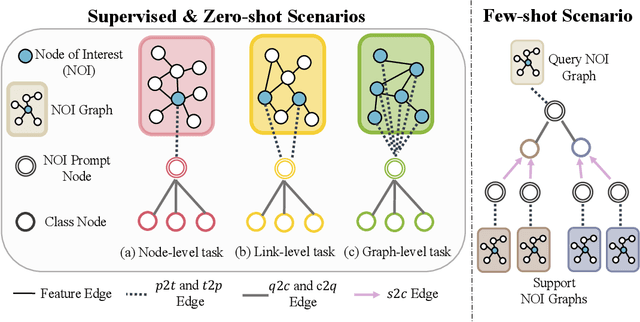

Designing a single model that addresses multiple tasks has been a long-standing objective in artificial intelligence. Recently, large language models have demonstrated exceptional capability in integrating and solving different tasks within the language domain. However, a unified model for various tasks on graphs remains underexplored, primarily due to the challenges unique to the graph learning domain. First, graph data from different areas carry distinct attributes and follow different distributions. Such discrepancy makes it hard to represent graphs in a single representation space. Second, tasks on graphs diversify into node, link, and graph tasks, requiring distinct embedding strategies. Finally, an appropriate graph prompting paradigm for in-context learning is unclear. Striving to handle all the aforementioned challenges, we propose One for All (OFA), the first general framework that can use a single graph model to address the above challenges. Specifically, OFA proposes text-attributed graphs to unify different graph data by describing nodes and edges with natural language and uses language models to encode the diverse and possibly cross-domain text attributes to feature vectors in the same embedding space. Furthermore, OFA introduces the concept of nodes-of-interest to standardize different tasks with a single task representation. For in-context learning on graphs, OFA introduces a novel graph prompting paradigm that appends prompting substructures to the input graph, which enables it to address varied tasks without fine-tuning. We train the OFA model using graph data from multiple domains (including citation networks, molecular graphs, knowledge graphs, etc.) simultaneously and evaluate its ability in supervised, few-shot, and zero-shot learning scenarios. OFA performs well across different tasks, making it the first general-purpose graph classification model across domains.
Graph Contrastive Learning Meets Graph Meta Learning: A Unified Method for Few-shot Node Tasks
Sep 19, 2023



Graph Neural Networks (GNNs) have become popular in Graph Representation Learning (GRL). One fundamental application is few-shot node classification. Most existing methods follow the meta learning paradigm, showing the ability of fast generalization to few-shot tasks. However, recent works indicate that graph contrastive learning combined with fine-tuning can significantly outperform meta learning methods. Despite the empirical success, there is limited understanding of the reasons behind it. In our study, we first identify two crucial advantages of contrastive learning compared to meta learning, including (1) the comprehensive utilization of graph nodes and (2) the power of graph augmentations. To integrate the strength of both contrastive learning and meta learning on the few-shot node classification tasks, we introduce a new paradigm: Contrastive Few-Shot Node Classification (COLA). Specifically, COLA employs graph augmentations to identify semantically similar nodes, which enables the construction of meta-tasks without the need for label information. Therefore, COLA can utilize all nodes to construct meta-tasks, further reducing the risk of overfitting. Through extensive experiments, we validate the essentiality of each component in our design and demonstrate that COLA achieves new state-of-the-art on all tasks.
Towards Arbitrarily Expressive GNNs in $O(n^2)$ Space by Rethinking Folklore Weisfeiler-Lehman
Jun 05, 2023Message passing neural networks (MPNNs) have emerged as the most popular framework of graph neural networks (GNNs) in recent years. However, their expressive power is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Some works are inspired by $k$-WL/FWL (Folklore WL) and design the corresponding neural versions. Despite the high expressive power, there are serious limitations in this line of research. In particular, (1) $k$-WL/FWL requires at least $O(n^k)$ space complexity, which is impractical for large graphs even when $k=3$; (2) The design space of $k$-WL/FWL is rigid, with the only adjustable hyper-parameter being $k$. To tackle the first limitation, we propose an extension, $(k, t)$-FWL. We theoretically prove that even if we fix the space complexity to $O(n^2)$ in $(k, t)$-FWL, we can construct an expressiveness hierarchy up to solving the graph isomorphism problem. To tackle the second problem, we propose $k$-FWL+, which considers any equivariant set as neighbors instead of all nodes, thereby greatly expanding the design space of $k$-FWL. Combining these two modifications results in a flexible and powerful framework $(k, t)$-FWL+. We demonstrate $(k, t)$-FWL+ can implement most existing models with matching expressiveness. We then introduce an instance of $(k,t)$-FWL+ called Neighborhood$^2$-FWL (N$^2$-FWL), which is practically and theoretically sound. We prove that N$^2$-FWL is no less powerful than 3-WL, can encode many substructures while only requiring $O(n^2)$ space. Finally, we design its neural version named N$^2$-GNN and evaluate its performance on various tasks. N$^2$-GNN achieves superior performance on almost all tasks, with record-breaking results on ZINC-Subset (0.059) and ZINC-Full (0.013), outperforming previous state-of-the-art results by 10.6% and 40.9%, respectively.
Time Associated Meta Learning for Clinical Prediction
Mar 05, 2023Rich Electronic Health Records (EHR), have created opportunities to improve clinical processes using machine learning methods. Prediction of the same patient events at different time horizons can have very different applications and interpretations; however, limited number of events in each potential time window hurts the effectiveness of conventional machine learning algorithms. We propose a novel time associated meta learning (TAML) method to make effective predictions at multiple future time points. We view time-associated disease prediction as classification tasks at multiple time points. Such closely-related classification tasks are an excellent candidate for model-based meta learning. To address the sparsity problem after task splitting, TAML employs a temporal information sharing strategy to augment the number of positive samples and include the prediction of related phenotypes or events in the meta-training phase. We demonstrate the effectiveness of TAML on multiple clinical datasets, where it consistently outperforms a range of strong baselines. We also develop a MetaEHR package for implementing both time-associated and time-independent few-shot prediction on EHR data.
A Multi-View Joint Learning Framework for Embedding Clinical Codes and Text Using Graph Neural Networks
Jan 27, 2023Learning to represent free text is a core task in many clinical machine learning (ML) applications, as clinical text contains observations and plans not otherwise available for inference. State-of-the-art methods use large language models developed with immense computational resources and training data; however, applying these models is challenging because of the highly varying syntax and vocabulary in clinical free text. Structured information such as International Classification of Disease (ICD) codes often succinctly abstracts the most important facts of a clinical encounter and yields good performance, but is often not as available as clinical text in real-world scenarios. We propose a \textbf{multi-view learning framework} that jointly learns from codes and text to combine the availability and forward-looking nature of text and better performance of ICD codes. The learned text embeddings can be used as inputs to predictive algorithms independent of the ICD codes during inference. Our approach uses a Graph Neural Network (GNN) to process ICD codes, and Bi-LSTM to process text. We apply Deep Canonical Correlation Analysis (DCCA) to enforce the two views to learn a similar representation of each patient. In experiments using planned surgical procedure text, our model outperforms BERT models fine-tuned to clinical data, and in experiments using diverse text in MIMIC-III, our model is competitive to a fine-tuned BERT at a tiny fraction of its computational effort.