 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Mixture-of-Experts for Incremental Graph Learning
Aug 13, 2025Graph incremental learning is a learning paradigm that aims to adapt trained models to continuously incremented graphs and data over time without the need for retraining on the full dataset. However, regular graph machine learning methods suffer from catastrophic forgetting when applied to incremental learning settings, where previously learned knowledge is overridden by new knowledge. Previous approaches have tried to address this by treating the previously trained model as an inseparable unit and using techniques to maintain old behaviors while learning new knowledge. These approaches, however, do not account for the fact that previously acquired knowledge at different timestamps contributes differently to learning new tasks. Some prior patterns can be transferred to help learn new data, while others may deviate from the new data distribution and be detrimental. To address this, we propose a dynamic mixture-of-experts (DyMoE) approach for incremental learning. Specifically, a DyMoE GNN layer adds new expert networks specialized in modeling the incoming data blocks. We design a customized regularization loss that utilizes data sequence information so existing experts can maintain their ability to solve old tasks while helping the new expert learn the new data effectively. As the number of data blocks grows over time, the computational cost of the full mixture-of-experts (MoE) model increases. To address this, we introduce a sparse MoE approach, where only the top-$k$ most relevant experts make predictions, significantly reducing the computation time. Our model achieved 4.92\% relative accuracy increase compared to the best baselines on class incremental learning, showing the model's exceptional power.
Deformable Graph Transformer
Jun 29, 2022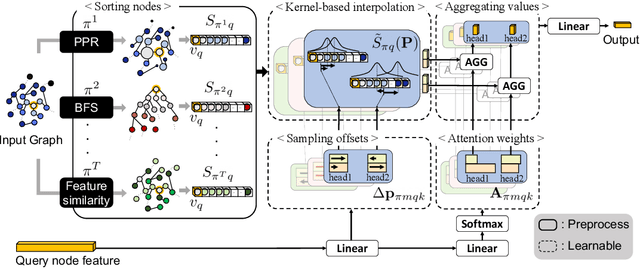
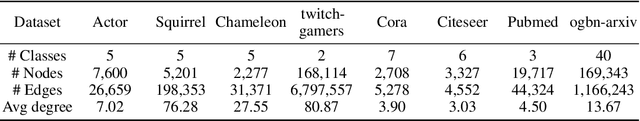
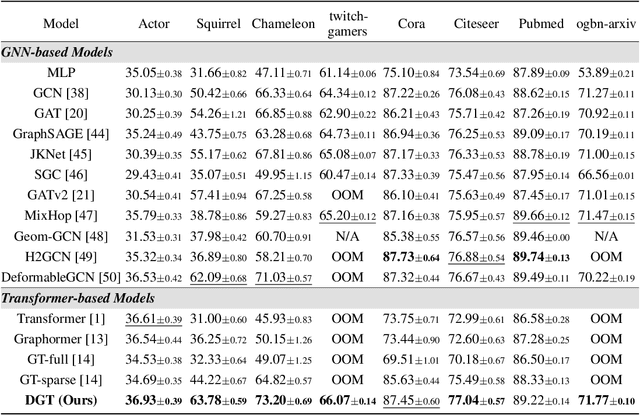
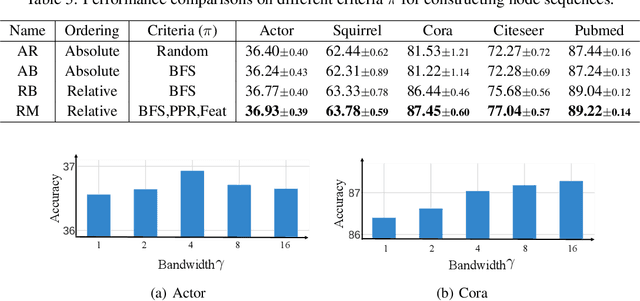
Transformer-based models have been widely used and achieved state-of-the-art performance in various domains such as natural language processing and computer vision. Recent works show that Transformers can also be generalized to graph-structured data. However, the success is limited to small-scale graphs due to technical challenges such as the quadratic complexity in regards to the number of nodes and non-local aggregation that often leads to inferior generalization performance to conventional graph neural networks. In this paper, to address these issues, we propose Deformable Graph Transformer (DGT) that performs sparse attention with dynamically sampled key and value pairs. Specifically, our framework first constructs multiple node sequences with various criteria to consider both structural and semantic proximity. Then, the sparse attention is applied to the node sequences for learning node representations with a reduced computational cost. We also design simple and effective positional encodings to capture structural similarity and distance between nodes. Experiments demonstrate that our novel graph Transformer consistently outperforms existing Transformer-based models and shows competitive performance compared to state-of-the-art models on 8 graph benchmark datasets including large-scale graphs.
Neo-GNNs: Neighborhood Overlap-aware Graph Neural Networks for Link Prediction
Jun 09, 2022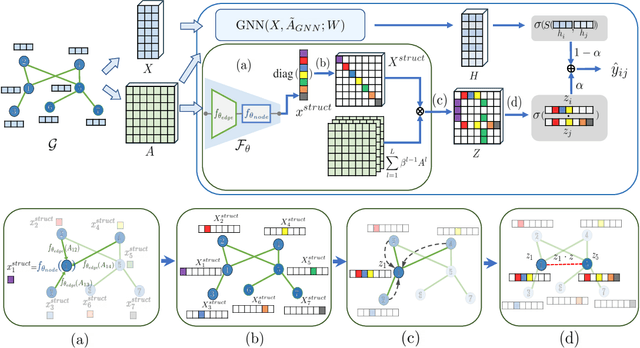
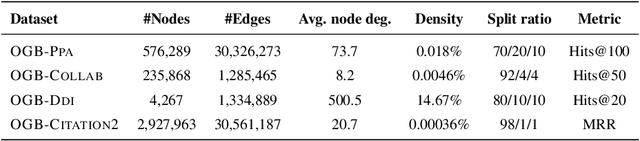
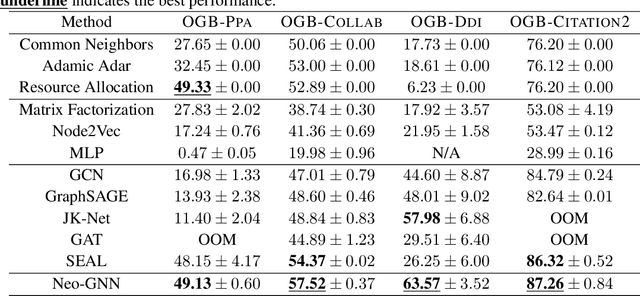
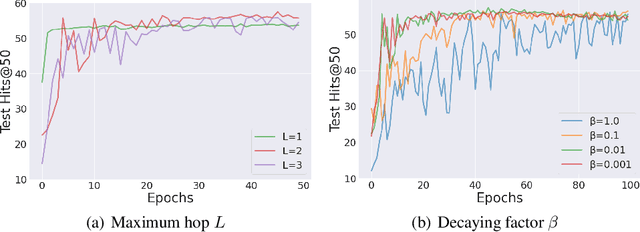
Graph Neural Networks (GNNs) have been widely applied to various fields for learning over graph-structured data. They have shown significant improvements over traditional heuristic methods in various tasks such as node classification and graph classification. However, since GNNs heavily rely on smoothed node features rather than graph structure, they often show poor performance than simple heuristic methods in link prediction where the structural information, e.g., overlapped neighborhoods, degrees, and shortest paths, is crucial. To address this limitation, we propose Neighborhood Overlap-aware Graph Neural Networks (Neo-GNNs) that learn useful structural features from an adjacency matrix and estimate overlapped neighborhoods for link prediction. Our Neo-GNNs generalize neighborhood overlap-based heuristic methods and handle overlapped multi-hop neighborhoods. Our extensive experiments on Open Graph Benchmark datasets (OGB) demonstrate that Neo-GNNs consistently achieve state-of-the-art performance in link prediction. Our code is publicly available at https://github.com/seongjunyun/Neo_GNNs.
Graph Transformer Networks: Learning Meta-path Graphs to Improve GNNs
Jun 11, 2021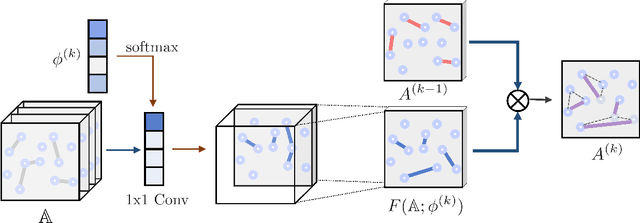

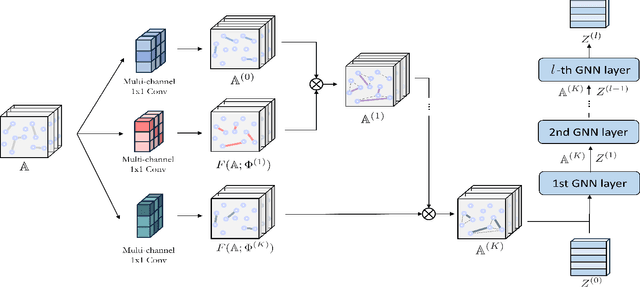
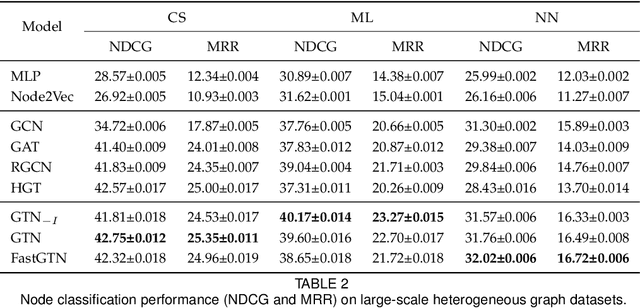
Graph Neural Networks (GNNs) have been widely applied to various fields due to their powerful representations of graph-structured data. Despite the success of GNNs, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. To address this limitations, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which preclude noisy connections and include useful connections (e.g., meta-paths) for tasks, while learning effective node representations on the new graphs in an end-to-end fashion. We further propose enhanced version of GTNs, Fast Graph Transformer Networks (FastGTNs), that improve scalability of graph transformations. Compared to GTNs, FastGTNs are 230x faster and use 100x less memory while allowing the identical graph transformations as GTNs. In addition, we extend graph transformations to the semantic proximity of nodes allowing non-local operations beyond meta-paths. Extensive experiments on both homogeneous graphs and heterogeneous graphs show that GTNs and FastGTNs with non-local operations achieve the state-of-the-art performance for node classification tasks. The code is available: https://github.com/seongjunyun/Graph_Transformer_Networks
Graph Transformer Networks
Nov 06, 2019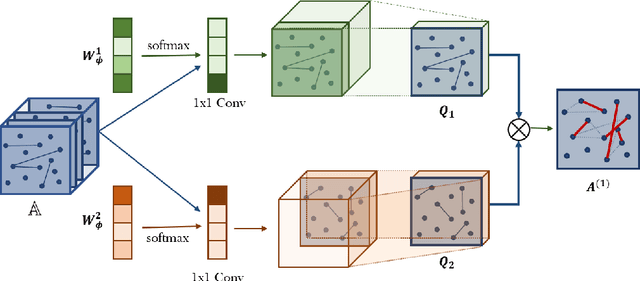

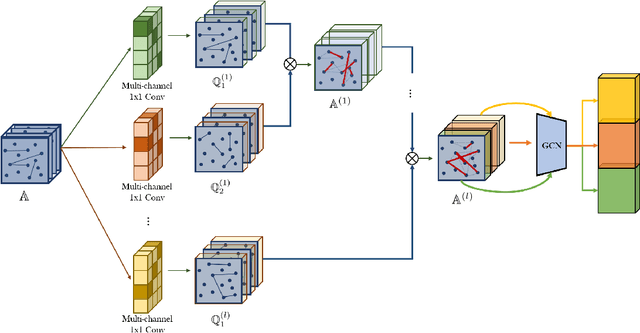

Graph neural networks (GNNs) have been widely used in representation learning on graphs and achieved state-of-the-art performance in tasks such as node classification and link prediction. However, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. In this paper, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which involve identifying useful connections between unconnected nodes on the original graph, while learning effective node representation on the new graphs in an end-to-end fashion. Graph Transformer layer, a core layer of GTNs, learns a soft selection of edge types and composite relations for generating useful multi-hop connections so-called meta-paths. Our experiments show that GTNs learn new graph structures, based on data and tasks without domain knowledge, and yield powerful node representation via convolution on the new graphs. Without domain-specific graph preprocessing, GTNs achieved the best performance in all three benchmark node classification tasks against the state-of-the-art methods that require pre-defined meta-paths from domain knowledge.
Ranking Paragraphs for Improving Answer Recall in Open-Domain Question Answering
Oct 01, 2018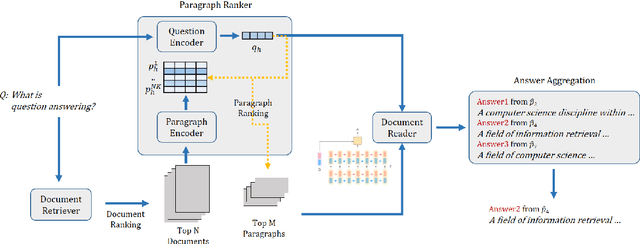
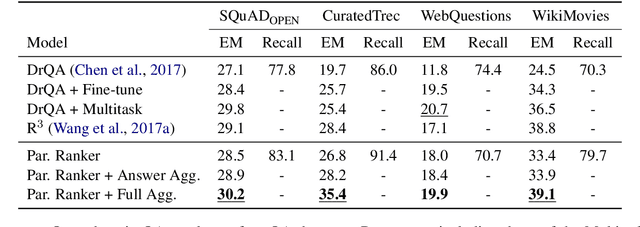

Recently, open-domain question answering (QA) has been combined with machine comprehension models to find answers in a large knowledge source. As open-domain QA requires retrieving relevant documents from text corpora to answer questions, its performance largely depends on the performance of document retrievers. However, since traditional information retrieval systems are not effective in obtaining documents with a high probability of containing answers, they lower the performance of QA systems. Simply extracting more documents increases the number of irrelevant documents, which also degrades the performance of QA systems. In this paper, we introduce Paragraph Ranker which ranks paragraphs of retrieved documents for a higher answer recall with less noise. We show that ranking paragraphs and aggregating answers using Paragraph Ranker improves performance of open-domain QA pipeline on the four open-domain QA datasets by 7.8% on average.