 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Transformer Networks: Learning Meta-path Graphs to Improve GNNs
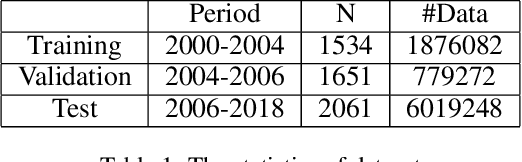
Jun 11, 2021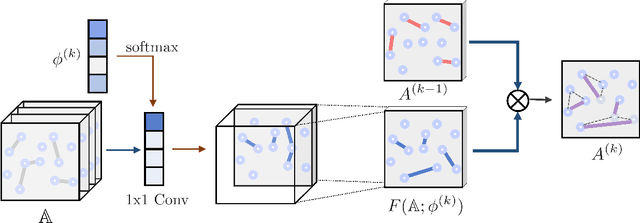

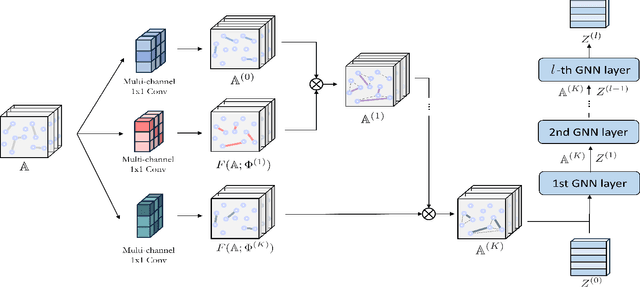
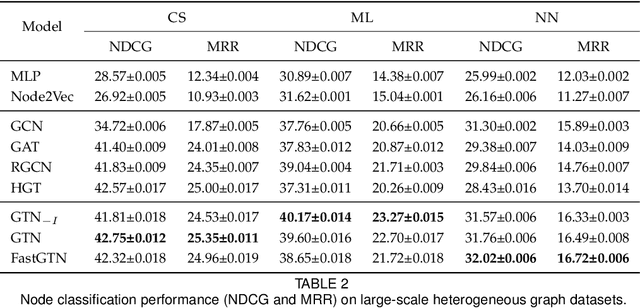
Graph Neural Networks (GNNs) have been widely applied to various fields due to their powerful representations of graph-structured data. Despite the success of GNNs, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. To address this limitations, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which preclude noisy connections and include useful connections (e.g., meta-paths) for tasks, while learning effective node representations on the new graphs in an end-to-end fashion. We further propose enhanced version of GTNs, Fast Graph Transformer Networks (FastGTNs), that improve scalability of graph transformations. Compared to GTNs, FastGTNs are 230x faster and use 100x less memory while allowing the identical graph transformations as GTNs. In addition, we extend graph transformations to the semantic proximity of nodes allowing non-local operations beyond meta-paths. Extensive experiments on both homogeneous graphs and heterogeneous graphs show that GTNs and FastGTNs with non-local operations achieve the state-of-the-art performance for node classification tasks. The code is available: https://github.com/seongjunyun/Graph_Transformer_Networks
MAPS: Multi-agent Reinforcement Learning-based Portfolio Management System
Jul 10, 2020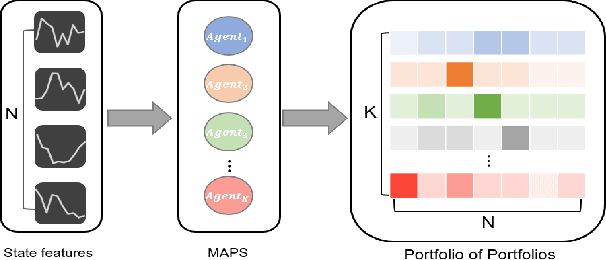
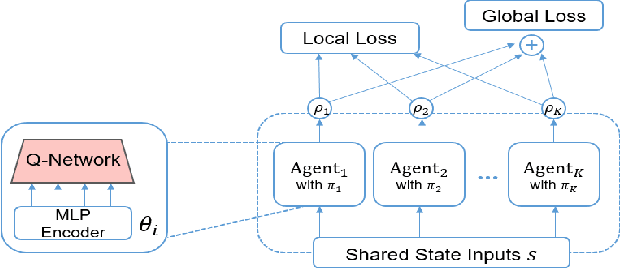

Generating an investment strategy using advanced deep learning methods in stock markets has recently been a topic of interest. Most existing deep learning methods focus on proposing an optimal model or network architecture by maximizing return. However, these models often fail to consider and adapt to the continuously changing market conditions. In this paper, we propose the Multi-Agent reinforcement learning-based Portfolio management System (MAPS). MAPS is a cooperative system in which each agent is an independent "investor" creating its own portfolio. In the training procedure, each agent is guided to act as diversely as possible while maximizing its own return with a carefully designed loss function. As a result, MAPS as a system ends up with a diversified portfolio. Experiment results with 12 years of US market data show that MAPS outperforms most of the baselines in terms of Sharpe ratio. Furthermore, our results show that adding more agents to our system would allow us to get a higher Sharpe ratio by lowering risk with a more diversified portfolio.
Graph Transformer Networks
Nov 06, 2019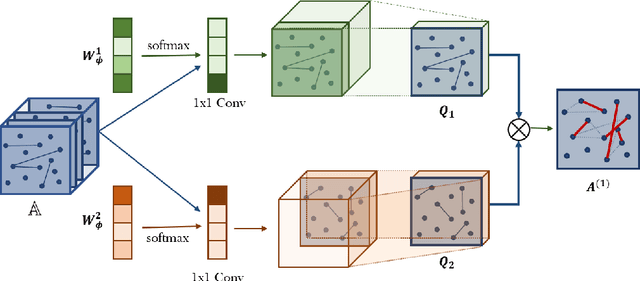

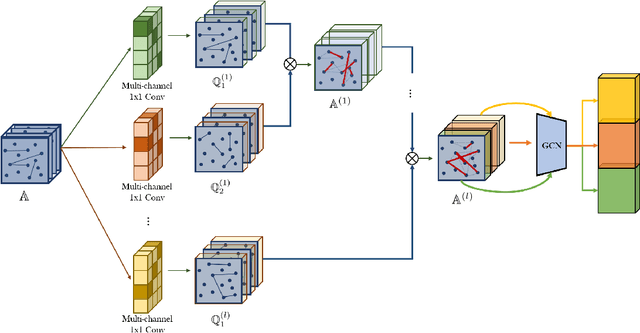

Graph neural networks (GNNs) have been widely used in representation learning on graphs and achieved state-of-the-art performance in tasks such as node classification and link prediction. However, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. In this paper, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which involve identifying useful connections between unconnected nodes on the original graph, while learning effective node representation on the new graphs in an end-to-end fashion. Graph Transformer layer, a core layer of GTNs, learns a soft selection of edge types and composite relations for generating useful multi-hop connections so-called meta-paths. Our experiments show that GTNs learn new graph structures, based on data and tasks without domain knowledge, and yield powerful node representation via convolution on the new graphs. Without domain-specific graph preprocessing, GTNs achieved the best performance in all three benchmark node classification tasks against the state-of-the-art methods that require pre-defined meta-paths from domain knowledge.
HATS: A Hierarchical Graph Attention Network for Stock Movement Prediction
Aug 24, 2019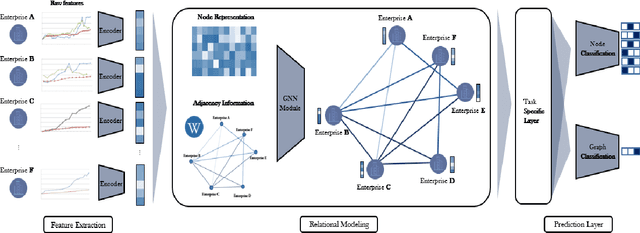
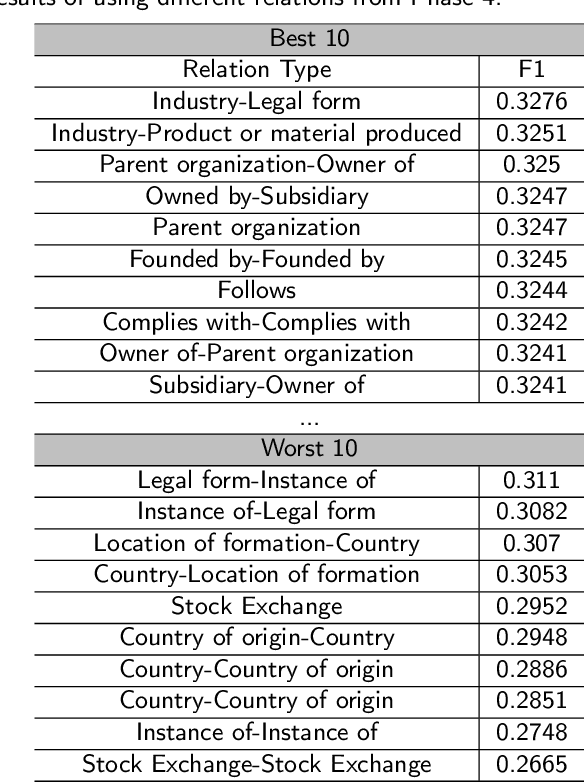
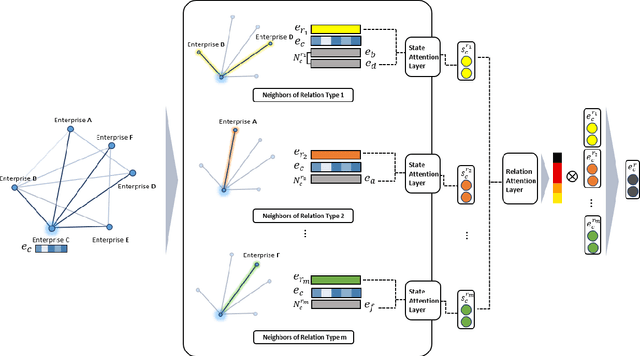
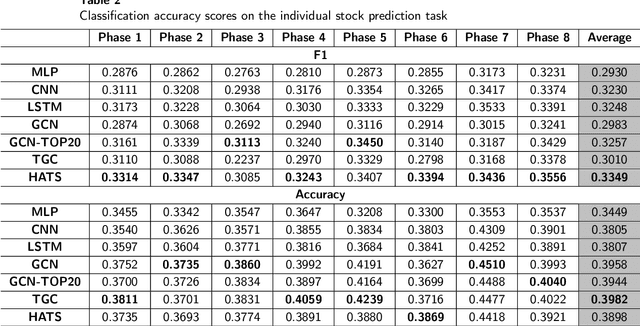
Many researchers both in academia and industry have long been interested in the stock market. Numerous approaches were developed to accurately predict future trends in stock prices. Recently, there has been a growing interest in utilizing graph-structured data in computer science research communities. Methods that use relational data for stock market prediction have been recently proposed, but they are still in their infancy. First, the quality of collected information from different types of relations can vary considerably. No existing work has focused on the effect of using different types of relations on stock market prediction or finding an effective way to selectively aggregate information on different relation types. Furthermore, existing works have focused on only individual stock prediction which is similar to the node classification task. To address this, we propose a hierarchical attention network for stock prediction (HATS) which uses relational data for stock market prediction. Our HATS method selectively aggregates information on different relation types and adds the information to the representations of each company. Specifically, node representations are initialized with features extracted from a feature extraction module. HATS is used as a relational modeling module with initialized node representations. Then, node representations with the added information are fed into a task-specific layer. Our method is used for predicting not only individual stock prices but also market index movements, which is similar to the graph classification task. The experimental results show that performance can change depending on the relational data used. HATS which can automatically select information outperformed all the existing methods.
SAIN: Self-Attentive Integration Network for Recommendation
May 27, 2019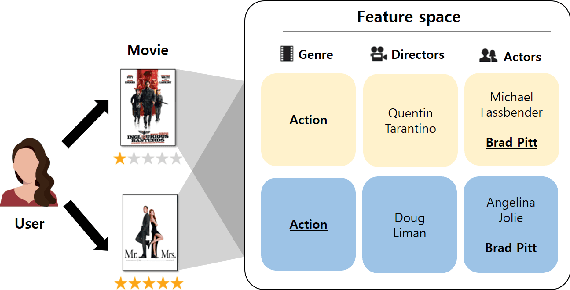
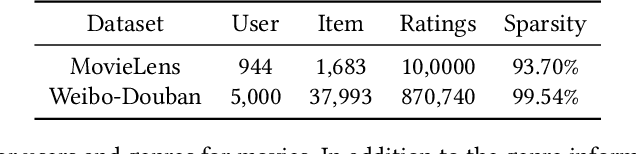
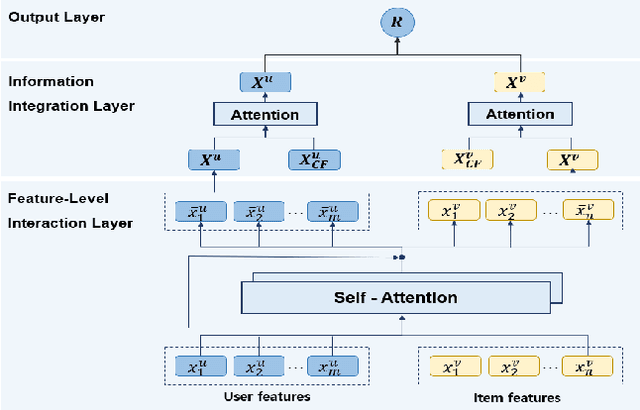

With the growing importance of personalized recommendation, numerous recommendation models have been proposed recently. Among them, Matrix Factorization (MF) based models are the most widely used in the recommendation field due to their high performance. However, MF based models suffer from cold start problems where user-item interactions are sparse. To deal with this problem, content based recommendation models which use the auxiliary attributes of users and items have been proposed. Since these models use auxiliary attributes, they are effective in cold start settings. However, most of the proposed models are either unable to capture complex feature interactions or not properly designed to combine user-item feedback information with content information. In this paper, we propose Self-Attentive Integration Network (SAIN) which is a model that effectively combines user-item feedback information and auxiliary information for recommendation task. In SAIN, a self-attention mechanism is used in the feature-level interaction layer to effectively consider interactions between multiple features, while the information integration layer adaptively combines content and feedback information. The experimental results on two public datasets show that our model outperforms the state-of-the-art models by 2.13%
Predicting Multiple Demographic Attributes with Task Specific Embedding Transformation and Attention Network
Mar 25, 2019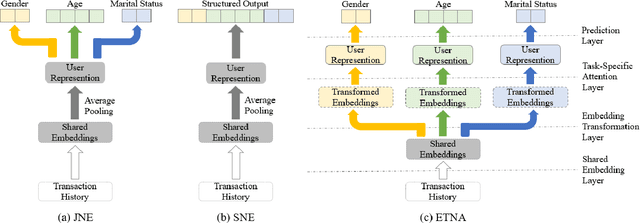
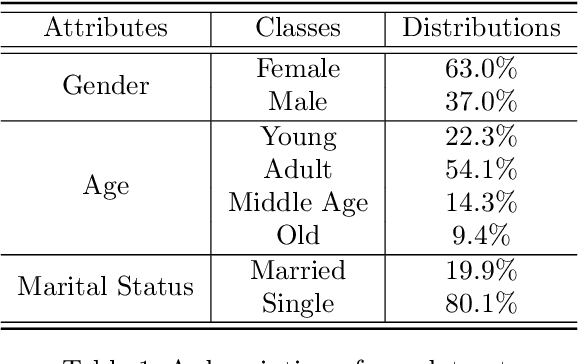
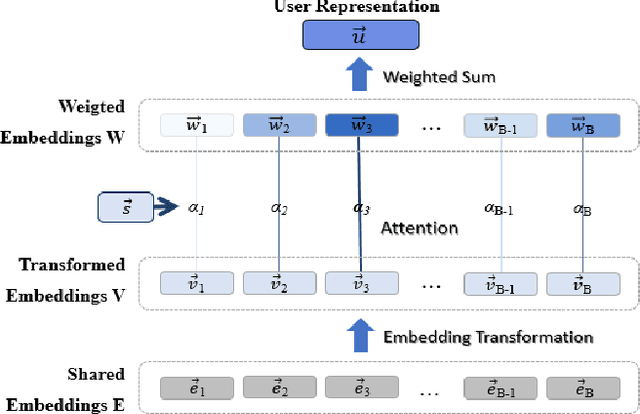

Most companies utilize demographic information to develop their strategy in a market. However, such information is not available to most retail companies. Several studies have been conducted to predict the demographic attributes of users from their transaction histories, but they have some limitations. First, they focused on parameter sharing to predict all attributes but capturing task-specific features is also important in multi-task learning. Second, they assumed that all transactions are equally important in predicting demographic attributes. However, some transactions are more useful than others for predicting a certain attribute. Furthermore, decision making process of models cannot be interpreted as they work in a black-box manner. To address the limitations, we propose an Embedding Transformation Network with Attention (ETNA) model which shares representations at the bottom of the model structure and transforms them to task-specific representations using a simple linear transformation method. In addition, we can obtain more informative transactions for predicting certain attributes using the attention mechanism. The experimental results show that our model outperforms the previous models on all tasks. In our qualitative analysis, we show the visualization of attention weights, which provides business managers with some useful insights.