 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-Driven Reasoning for Industrial Maintenance Using Heterogeneous Data
Mar 09, 2026Industrial maintenance platforms contain rich but fragmented evidence, including free-text work orders, heterogeneous operational sensors or indicators, and structured failure knowledge. These sources are often analyzed in isolation, producing alerts or forecasts that do not support conditional decision-making: given this asset history and behavior, what is happening and what action is warranted? We present Condition Insight Agent, a deployed decision-support framework that integrates maintenance language, behavioral abstractions of operational data, and engineering failure semantics to produce evidence-grounded explanations and advisory actions. The system constrains reasoning through deterministic evidence construction and structured failure knowledge, and applies a rule-based verification loop to suppress unsupported conclusions. Case studies from production CMMS deployments show that this verification-first design operates reliably under heterogeneous and incomplete data while preserving human oversight. Our results demonstrate how constrained LLM-based reasoning can function as a governed decision-support layer for industrial maintenance.
Overcoming Representation Bias in Fairness-Aware data Repair using Optimal Transport
Oct 03, 2024



Optimal transport (OT) has an important role in transforming data distributions in a manner which engenders fairness. Typically, the OT operators are learnt from the unfair attribute-labelled data, and then used for their repair. Two significant limitations of this approach are as follows: (i) the OT operators for underrepresented subgroups are poorly learnt (i.e. they are susceptible to representation bias); and (ii) these OT repairs cannot be effected on identically distributed but out-of-sample (i.e.\ archival) data. In this paper, we address both of these problems by adopting a Bayesian nonparametric stopping rule for learning each attribute-labelled component of the data distribution. The induced OT-optimal quantization operators can then be used to repair the archival data. We formulate a novel definition of the fair distributional target, along with quantifiers that allow us to trade fairness against damage in the transformed data. These are used to reveal excellent performance of our representation-bias-tolerant scheme in simulated and benchmark data sets.
Optimal Transport for Fairness: Archival Data Repair using Small Research Data Sets
Mar 20, 2024With the advent of the AI Act and other regulations, there is now an urgent need for algorithms that repair unfairness in training data. In this paper, we define fairness in terms of conditional independence between protected attributes ($S$) and features ($X$), given unprotected attributes ($U$). We address the important setting in which torrents of archival data need to be repaired, using only a small proportion of these data, which are $S|U$-labelled (the research data). We use the latter to design optimal transport (OT)-based repair plans on interpolated supports. This allows {\em off-sample}, labelled, archival data to be repaired, subject to stationarity assumptions. It also significantly reduces the size of the supports of the OT plans, with correspondingly large savings in the cost of their design and of their {\em sequential\/} application to the off-sample data. We provide detailed experimental results with simulated and benchmark real data (the Adult data set). Our performance figures demonstrate effective repair -- in the sense of quenching conditional dependence -- of large quantities of off-sample, labelled (archival) data.
Causal Temporal Graph Convolutional Neural Networks (CTGCN)
Mar 16, 2023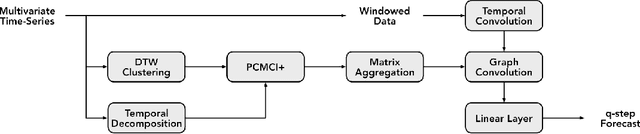
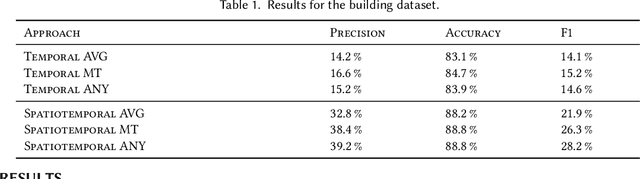
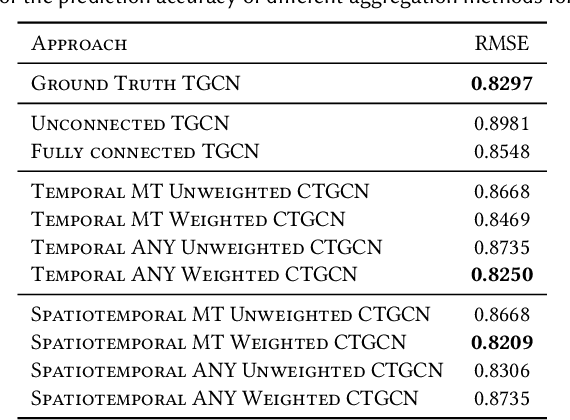
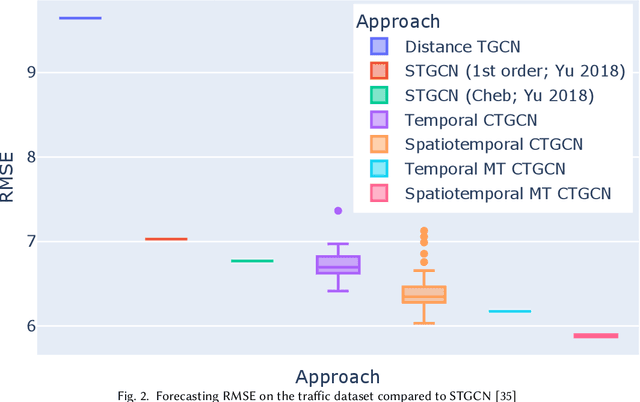
Many large-scale applications can be elegantly represented using graph structures. Their scalability, however, is often limited by the domain knowledge required to apply them. To address this problem, we propose a novel Causal Temporal Graph Convolutional Neural Network (CTGCN). Our CTGCN architecture is based on a causal discovery mechanism, and is capable of discovering the underlying causal processes. The major advantages of our approach stem from its ability to overcome computational scalability problems with a divide and conquer technique, and from the greater explainability of predictions made using a causal model. We evaluate the scalability of our CTGCN on two datasets to demonstrate that our method is applicable to large scale problems, and show that the integration of causality into the TGCN architecture improves prediction performance up to 40% over typical TGCN approach. Our results are obtained without requiring additional domain knowledge, making our approach adaptable to various domains, specifically when little contextual knowledge is available.