 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSortability of Time Series Data
Jul 18, 2024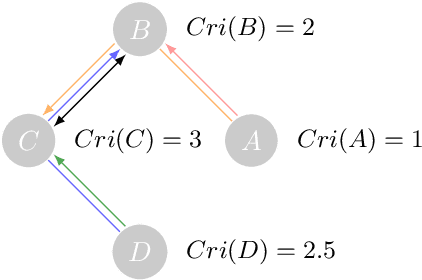
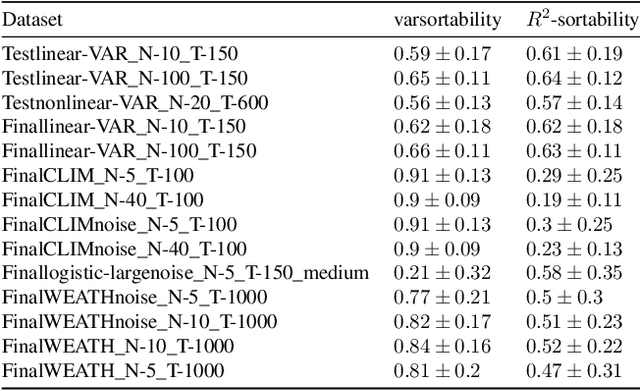
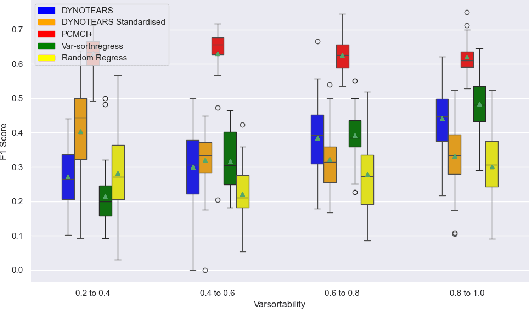
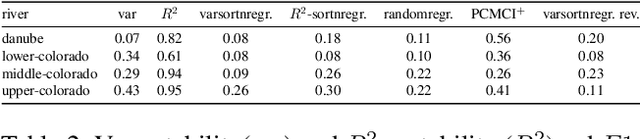
Evaluating the performance of causal discovery algorithms that aim to find causal relationships between time-dependent processes remains a challenging topic. In this paper, we show that certain characteristics of datasets, such as varsortability (Reisach et al. 2021) and $R^2$-sortability (Reisach et al. 2023), also occur in datasets for autocorrelated stationary time series. We illustrate this empirically using four types of data: simulated data based on SVAR models and Erd\H{o}s-R\'enyi graphs, the data used in the 2019 causality-for-climate challenge (Runge et al. 2019), real-world river stream datasets, and real-world data generated by the Causal Chamber of (Gamella et al. 2024). To do this, we adapt var- and $R^2$-sortability to time series data. We also investigate the extent to which the performance of score-based causal discovery methods goes hand in hand with high sortability. Arguably, our most surprising finding is that the investigated real-world datasets exhibit high varsortability and low $R^2$-sortability indicating that scales may carry a significant amount of causal information.
Causal Temporal Graph Convolutional Neural Networks (CTGCN)
Mar 16, 2023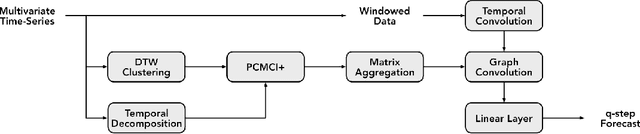
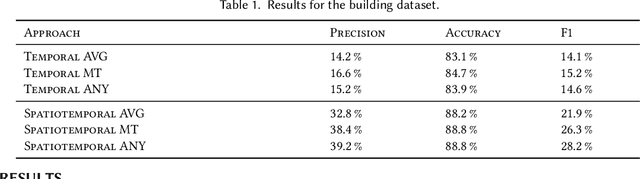
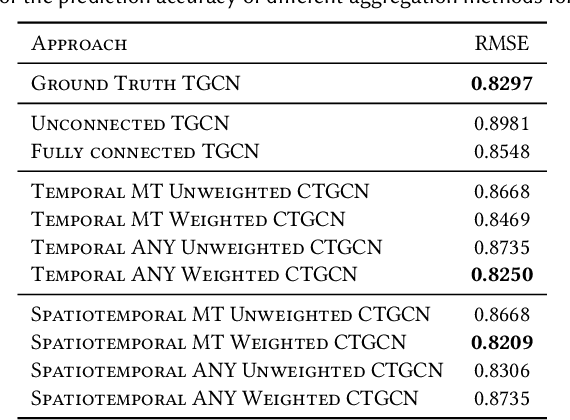
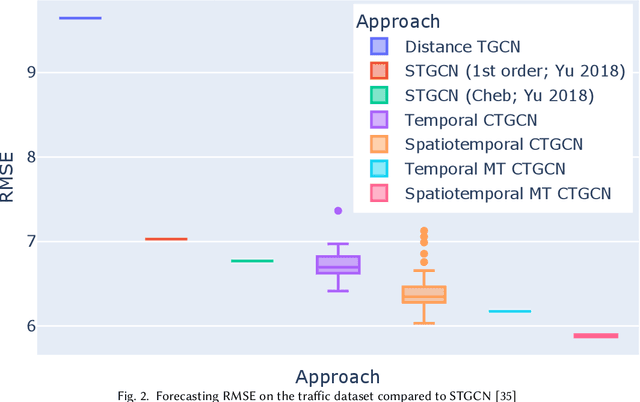
Many large-scale applications can be elegantly represented using graph structures. Their scalability, however, is often limited by the domain knowledge required to apply them. To address this problem, we propose a novel Causal Temporal Graph Convolutional Neural Network (CTGCN). Our CTGCN architecture is based on a causal discovery mechanism, and is capable of discovering the underlying causal processes. The major advantages of our approach stem from its ability to overcome computational scalability problems with a divide and conquer technique, and from the greater explainability of predictions made using a causal model. We evaluate the scalability of our CTGCN on two datasets to demonstrate that our method is applicable to large scale problems, and show that the integration of causality into the TGCN architecture improves prediction performance up to 40% over typical TGCN approach. Our results are obtained without requiring additional domain knowledge, making our approach adaptable to various domains, specifically when little contextual knowledge is available.
Syrupy Mouthfeel and Hints of Chocolate -- Predicting Coffee Review Scores using Text Based Sentiment
Jan 29, 2023



This paper uses textual data contained in certified (q-graded) coffee reviews to predict corresponding scores on a scale from 0-100. By transforming this highly specialized and standardized textual data in a predictor space, we construct regression models which accurately capture the patterns in corresponding coffee bean scores.
Towards Interpretable Summary Evaluation via Allocation of Contextual Embeddings to Reference Text Topics
Oct 25, 2022



Despite extensive recent advances in summary generation models, evaluation of auto-generated summaries still widely relies on single-score systems insufficient for transparent assessment and in-depth qualitative analysis. Towards bridging this gap, we propose the multifaceted interpretable summary evaluation method (MISEM), which is based on allocation of a summary's contextual token embeddings to semantic topics identified in the reference text. We further contribute an interpretability toolbox for automated summary evaluation and interactive visual analysis of summary scoring, topic identification, and token-topic allocation. MISEM achieves a promising .404 Pearson correlation with human judgment on the TAC'08 dataset.