 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI and the History of Architecture
Dec 22, 2023Recent generative AI platforms are able to create texts or impressive images from simple text prompts. This makes them powerful tools for summarizing knowledge about architectural history or deriving new creative work in early design tasks like ideation, sketching and modelling. But, how good is the understanding of the generative AI models of the history of architecture? Has it learned to properly distinguish styles, or is it hallucinating information? In this chapter, we investigate this question for generative AI platforms for text and image generation for different architectural styles, to understand the capabilities and boundaries of knowledge of those tools. We also analyze how they are already being used by analyzing a data set of 101 million Midjourney queries to see if and how practitioners are already querying for specific architectural concepts.
ArchiGuesser -- AI Art Architecture Educational Game
Dec 14, 2023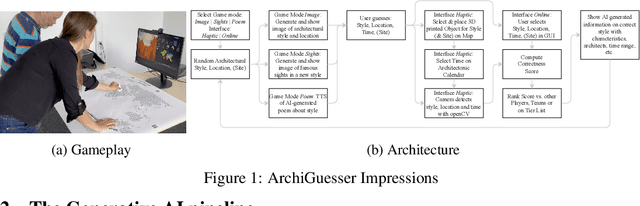
The use of generative AI in education is a controversial topic. Current technology offers the potential to create educational content from text, speech, to images based on simple input prompts. This can enhance productivity by summarizing knowledge and improving communication, quickly adjusting to different types of learners. Moreover, generative AI holds the promise of making the learning itself more fun, by responding to user inputs and dynamically generating high-quality creative material. In this paper we present the multisensory educational game ArchiGuesser that combines various AI technologies from large language models, image generation, to computer vision to serve a single purpose: Teaching students in a playful way the diversity of our architectural history and how generative AI works.
Diffusion Models for Computational Design at the Example of Floor Plans
Jul 05, 2023AI Image generators based on diffusion models are widely discussed recently for their capability to create images from simple text prompts. But, for practical use in civil engineering they need to be able to create specific construction plans for given constraints. Within this paper we explore the capabilities of those diffusion-based AI generators for computational design at the example of floor plans and identify their current limitation. We explain how the diffusion-models work and propose new diffusion models with improved semantic encoding. In several experiments we show that we can improve validity of generated floor plans from 6% to 90% and query performance for different examples. We identify short comings and derive future research challenges of those models and discuss the need to combine diffusion models with building information modelling. With this we provide key insights into the current state and future directions for diffusion models in civil engineering.
What Makes a Good Dataset for Symbol Description Reading?
Apr 17, 2023The usage of mathematical formulas as concise representations of a document's key ideas is common practice. Correctly interpreting these formulas, by identifying mathematical symbols and extracting their descriptions, is an important task in document understanding. This paper makes the following contributions to the mathematical identifier description reading (MIDR) task: (i) introduces the Math Formula Question Answering Dataset (MFQuAD) with $7508$ annotated identifier occurrences; (ii) describes novel variations of the noun phrase ranking approach for the MIDR task; (iii) reports experimental results for the SOTA noun phrase ranking approach and our novel variations of the approach, providing problem insights and a performance baseline; (iv) provides a position on the features that make an effective dataset for the MIDR task.
Causal Temporal Graph Convolutional Neural Networks (CTGCN)
Mar 16, 2023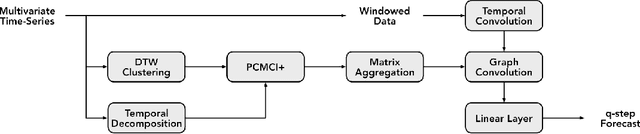
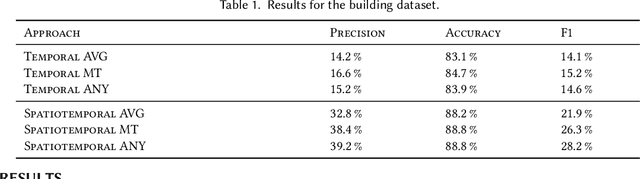
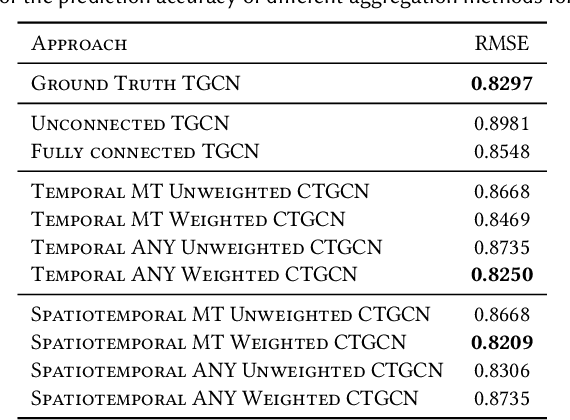
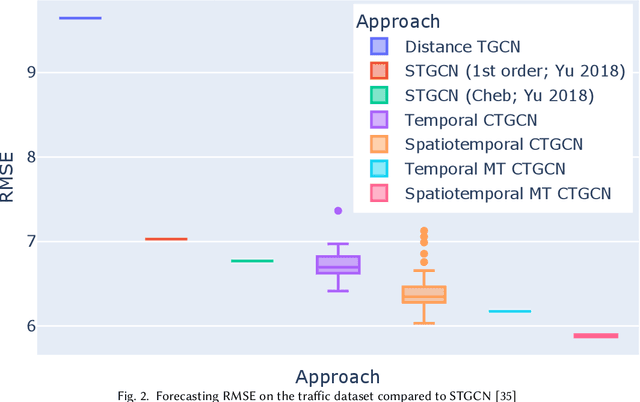
Many large-scale applications can be elegantly represented using graph structures. Their scalability, however, is often limited by the domain knowledge required to apply them. To address this problem, we propose a novel Causal Temporal Graph Convolutional Neural Network (CTGCN). Our CTGCN architecture is based on a causal discovery mechanism, and is capable of discovering the underlying causal processes. The major advantages of our approach stem from its ability to overcome computational scalability problems with a divide and conquer technique, and from the greater explainability of predictions made using a causal model. We evaluate the scalability of our CTGCN on two datasets to demonstrate that our method is applicable to large scale problems, and show that the integration of causality into the TGCN architecture improves prediction performance up to 40% over typical TGCN approach. Our results are obtained without requiring additional domain knowledge, making our approach adaptable to various domains, specifically when little contextual knowledge is available.
AI Art in Architecture
Dec 19, 2022Recent diffusion-based AI art platforms are able to create impressive images from simple text descriptions. This makes them powerful tools for concept design in any discipline that requires creativity in visual design tasks. This is also true for early stages of architectural design with multiple stages of ideation, sketching and modelling. In this paper, we investigate how applicable diffusion-based models already are to these tasks. We research the applicability of the platforms Midjourney, DALL-E 2 and StableDiffusion to a series of common use cases in architectural design to determine which are already solvable or might soon be. We also analyze how they are already being used by analyzing a data set of 40 million Midjourney queries with NLP methods to extract common usage patterns. With this insights we derived a workflow to interior and exterior design that combines the strengths of the individual platforms.
Scaling Knowledge Graphs for Automating AI of Digital Twins
Oct 26, 2022Digital Twins are digital representations of systems in the Internet of Things (IoT) that are often based on AI models that are trained on data from those systems. Semantic models are used increasingly to link these datasets from different stages of the IoT systems life-cycle together and to automatically configure the AI modelling pipelines. This combination of semantic models with AI pipelines running on external datasets raises unique challenges particular if rolled out at scale. Within this paper we will discuss the unique requirements of applying semantic graphs to automate Digital Twins in different practical use cases. We will introduce the benchmark dataset DTBM that reflects these characteristics and look into the scaling challenges of different knowledge graph technologies. Based on these insights we will propose a reference architecture that is in-use in multiple products in IBM and derive lessons learned for scaling knowledge graphs for configuring AI models for Digital Twins.
TSML (Time Series Machine Learnng)
May 27, 2020


Over the past years, the industrial sector has seen many innovations brought about by automation. Inherent in this automation is the installation of sensor networks for status monitoring and data collection. One of the major challenges in these data-rich environments is how to extract and exploit information from these large volume of data to detect anomalies, discover patterns to reduce downtimes and manufacturing errors, reduce energy usage, predict faults/failures, effective maintenance schedules, etc. To address these issues, we developed TSML. Its technology is based on using the pipeline of lightweight filters as building blocks to process huge amount of industrial time series data in parallel.