 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMEA Builder: Expert Guided Text Generation for Equipment Maintenance
Nov 07, 2024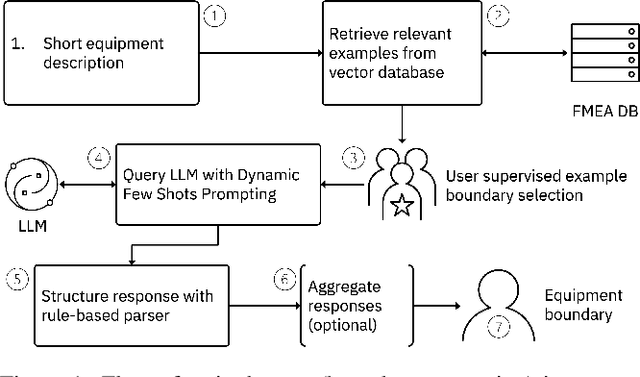
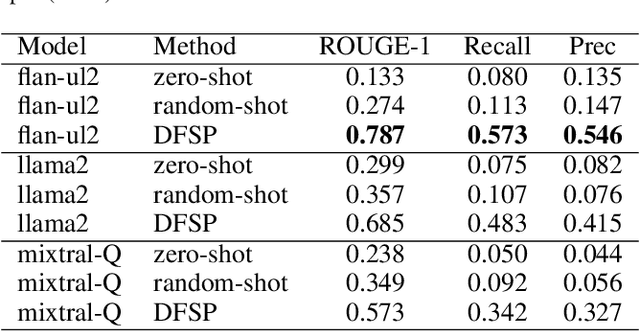
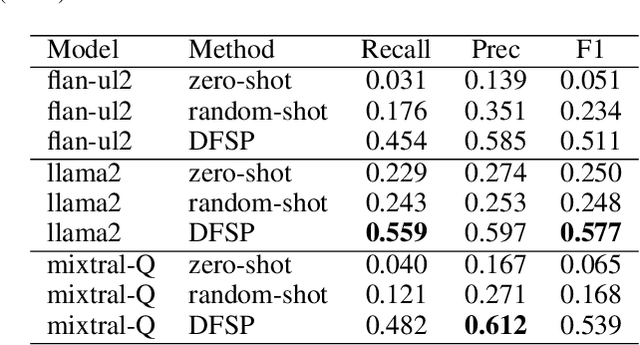

Foundation models show great promise for generative tasks in many domains. Here we discuss the use of foundation models to generate structured documents related to critical assets. A Failure Mode and Effects Analysis (FMEA) captures the composition of an asset or piece of equipment, the ways it may fail and the consequences thereof. Our system uses large language models to enable fast and expert supervised generation of new FMEA documents. Empirical analysis shows that foundation models can correctly generate over half of an FMEA's key content. Results from polling audiences of reliability professionals show a positive outlook on using generative AI to create these documents for critical assets.
What Makes a Good Dataset for Symbol Description Reading?
Apr 17, 2023
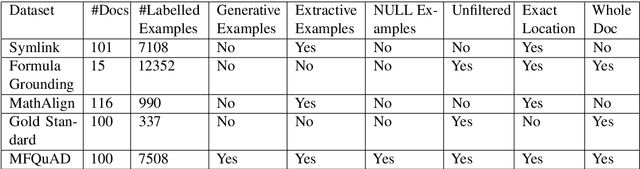


The usage of mathematical formulas as concise representations of a document's key ideas is common practice. Correctly interpreting these formulas, by identifying mathematical symbols and extracting their descriptions, is an important task in document understanding. This paper makes the following contributions to the mathematical identifier description reading (MIDR) task: (i) introduces the Math Formula Question Answering Dataset (MFQuAD) with $7508$ annotated identifier occurrences; (ii) describes novel variations of the noun phrase ranking approach for the MIDR task; (iii) reports experimental results for the SOTA noun phrase ranking approach and our novel variations of the approach, providing problem insights and a performance baseline; (iv) provides a position on the features that make an effective dataset for the MIDR task.
Towards Real-time Customer Experience Prediction for Telecommunication Operators
Sep 24, 2015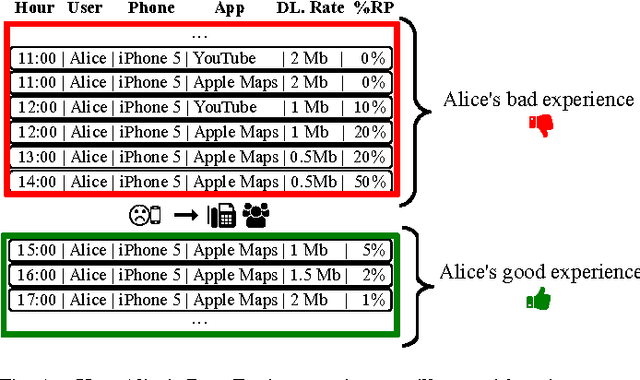
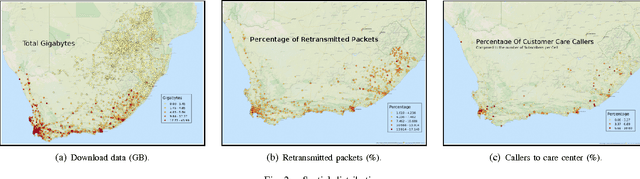
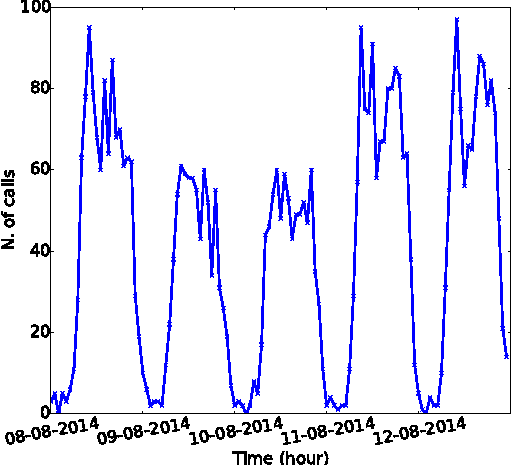
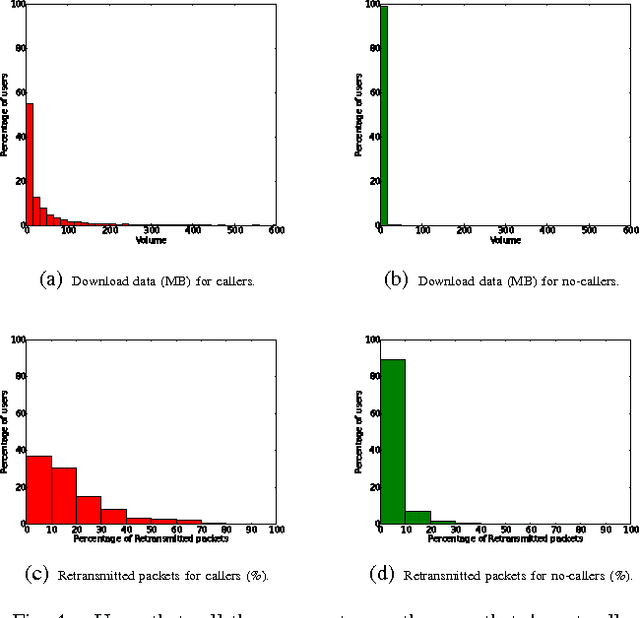
Telecommunications operators (telcos) traditional sources of income, voice and SMS, are shrinking due to customers using over-the-top (OTT) applications such as WhatsApp or Viber. In this challenging environment it is critical for telcos to maintain or grow their market share, by providing users with as good an experience as possible on their network. But the task of extracting customer insights from the vast amounts of data collected by telcos is growing in complexity and scale everey day. How can we measure and predict the quality of a user's experience on a telco network in real-time? That is the problem that we address in this paper. We present an approach to capture, in (near) real-time, the mobile customer experience in order to assess which conditions lead the user to place a call to a telco's customer care center. To this end, we follow a supervised learning approach for prediction and train our 'Restricted Random Forest' model using, as a proxy for bad experience, the observed customer transactions in the telco data feed before the user places a call to a customer care center. We evaluate our approach using a rich dataset provided by a major African telecommunication's company and a novel big data architecture for both the training and scoring of predictive models. Our empirical study shows our solution to be effective at predicting user experience by inferring if a customer will place a call based on his current context. These promising results open new possibilities for improved customer service, which will help telcos to reduce churn rates and improve customer experience, both factors that directly impact their revenue growth.