 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMEA Builder: Expert Guided Text Generation for Equipment Maintenance
Nov 07, 2024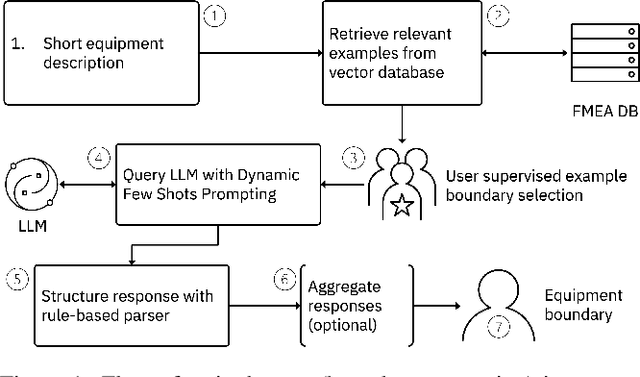
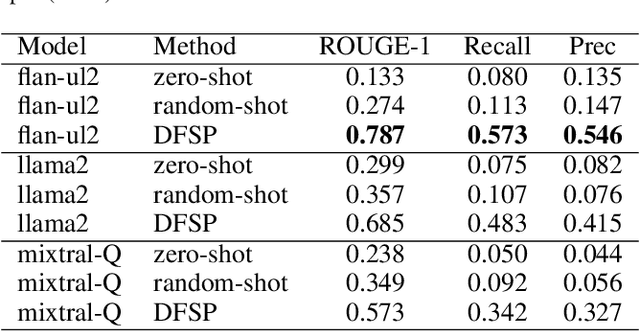
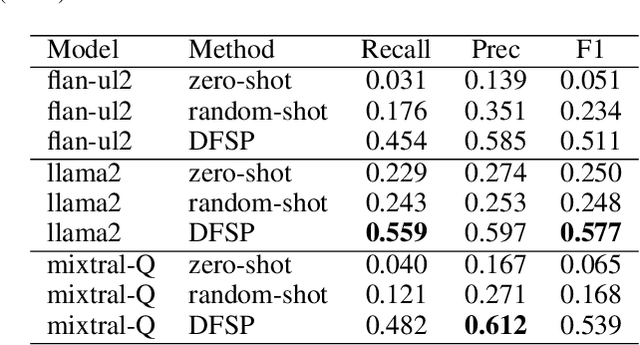

Foundation models show great promise for generative tasks in many domains. Here we discuss the use of foundation models to generate structured documents related to critical assets. A Failure Mode and Effects Analysis (FMEA) captures the composition of an asset or piece of equipment, the ways it may fail and the consequences thereof. Our system uses large language models to enable fast and expert supervised generation of new FMEA documents. Empirical analysis shows that foundation models can correctly generate over half of an FMEA's key content. Results from polling audiences of reliability professionals show a positive outlook on using generative AI to create these documents for critical assets.
What Makes a Good Dataset for Symbol Description Reading?
Apr 17, 2023
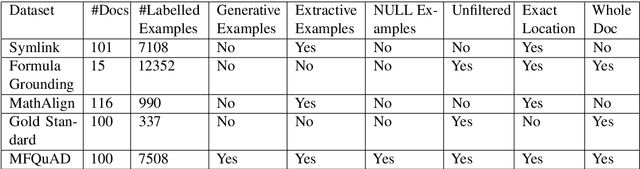


The usage of mathematical formulas as concise representations of a document's key ideas is common practice. Correctly interpreting these formulas, by identifying mathematical symbols and extracting their descriptions, is an important task in document understanding. This paper makes the following contributions to the mathematical identifier description reading (MIDR) task: (i) introduces the Math Formula Question Answering Dataset (MFQuAD) with $7508$ annotated identifier occurrences; (ii) describes novel variations of the noun phrase ranking approach for the MIDR task; (iii) reports experimental results for the SOTA noun phrase ranking approach and our novel variations of the approach, providing problem insights and a performance baseline; (iv) provides a position on the features that make an effective dataset for the MIDR task.
A monitoring framework for deployed machine learning models with supply chain examples
Nov 11, 2022



Actively monitoring machine learning models during production operations helps ensure prediction quality and detection and remediation of unexpected or undesired conditions. Monitoring models already deployed in big data environments brings the additional challenges of adding monitoring in parallel to the existing modelling workflow and controlling resource requirements. In this paper, we describe (1) a framework for monitoring machine learning models; and, (2) its implementation for a big data supply chain application. We use our implementation to study drift in model features, predictions, and performance on three real data sets. We compare hypothesis test and information theoretic approaches to drift detection in features and predictions using the Kolmogorov-Smirnov distance and Bhattacharyya coefficient. Results showed that model performance was stable over the evaluation period. Features and predictions showed statistically significant drifts; however, these drifts were not linked to changes in model performance during the time of our study.
Knowledge- and Data-driven Services for Energy Systems using Graph Neural Networks
Mar 12, 2021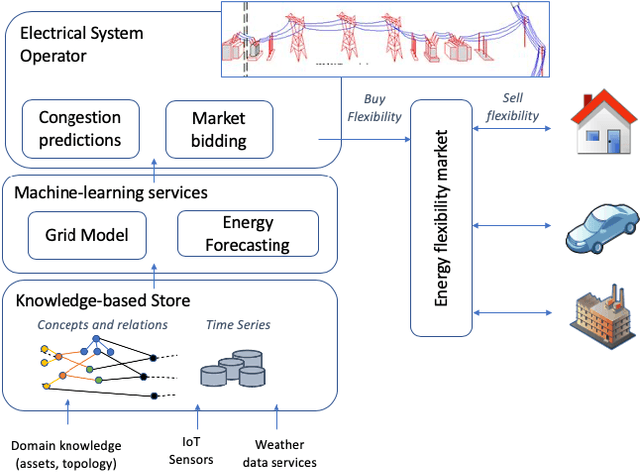
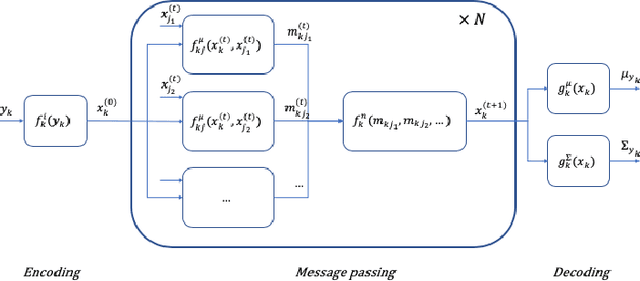
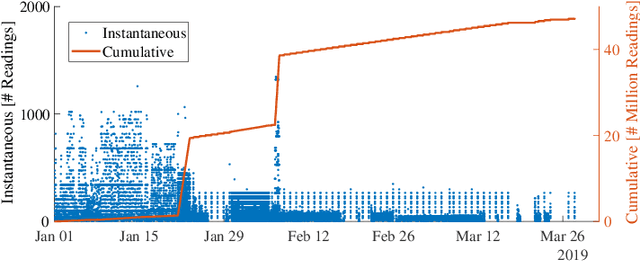
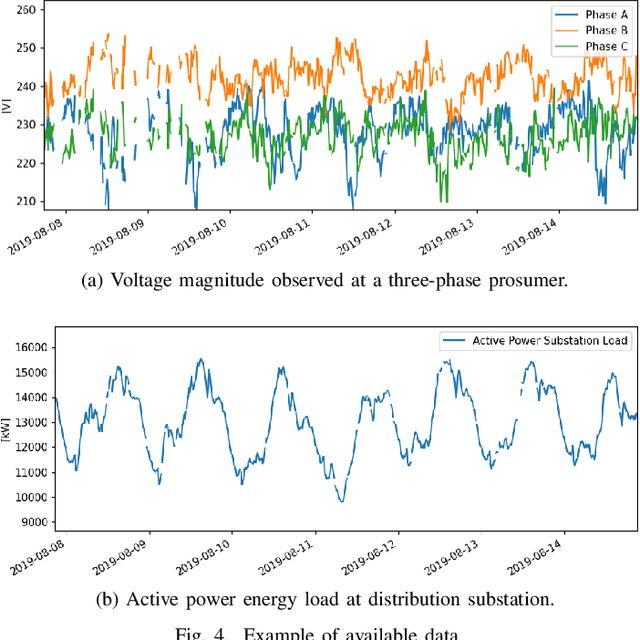
The transition away from carbon-based energy sources poses several challenges for the operation of electricity distribution systems. Increasing shares of distributed energy resources (e.g. renewable energy generators, electric vehicles) and internet-connected sensing and control devices (e.g. smart heating and cooling) require new tools to support accurate, datadriven decision making. Modelling the effect of such growing complexity in the electrical grid is possible in principle using state-of-the-art power-power flow models. In practice, the detailed information needed for these physical simulations may be unknown or prohibitively expensive to obtain. Hence, datadriven approaches to power systems modelling, including feedforward neural networks and auto-encoders, have been studied to leverage the increasing availability of sensor data, but have seen limited practical adoption due to lack of transparency and inefficiencies on large-scale problems. Our work addresses this gap by proposing a data- and knowledge-driven probabilistic graphical model for energy systems based on the framework of graph neural networks (GNNs). The model can explicitly factor in domain knowledge, in the form of grid topology or physics constraints, thus resulting in sparser architectures and much smaller parameters dimensionality when compared with traditional machine-learning models with similar accuracy. Results obtained from a real-world smart-grid demonstration project show how the GNN was used to inform grid congestion predictions and market bidding services for a distribution system operator participating in an energy flexibility market.
Scalable Deployment of AI Time-series Models for IoT
Mar 24, 2020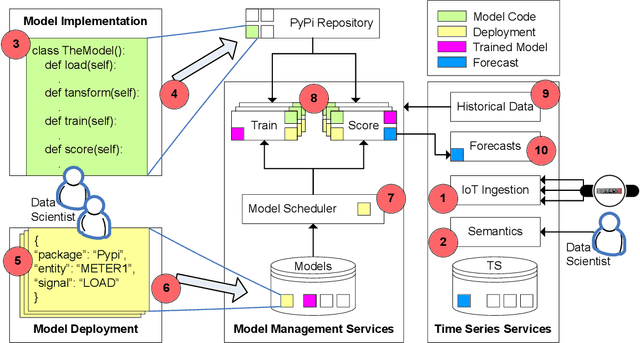

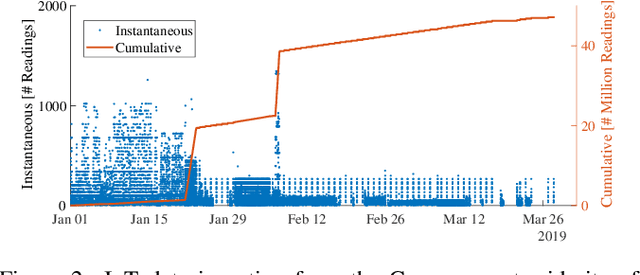
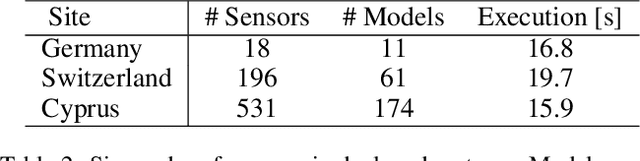
IBM Research Castor, a cloud-native system for managing and deploying large numbers of AI time-series models in IoT applications, is described. Modelling code templates, in Python and R, following a typical machine-learning workflow are supported. A knowledge-based approach to managing model and time-series data allows the use of general semantic concepts for expressing feature engineering tasks. Model templates can be programmatically deployed against specific instances of semantic concepts, thus supporting model reuse and automated replication as the IoT application grows. Deployed models are automatically executed in parallel leveraging a serverless cloud computing framework. The complete history of trained model versions and rolling-horizon predictions is persisted, thus enabling full model lineage and traceability. Results from deployments in real-world smart-grid live forecasting applications are reported. Scalability of executing up to tens of thousands of AI modelling tasks is also evaluated.