 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Learned Cost Models with Synthetic SQL Queries
Aug 27, 2025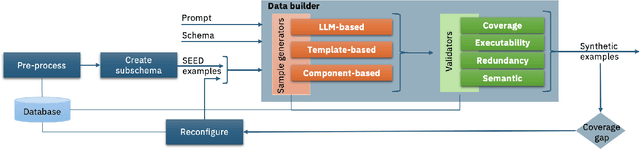

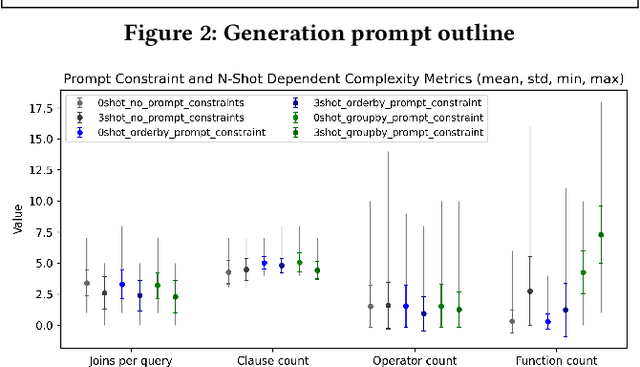
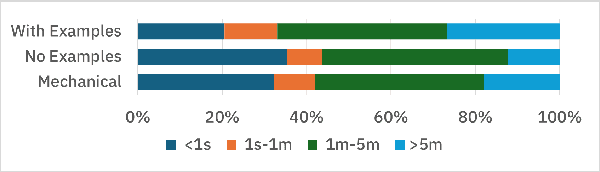
Having access to realistic workloads for a given database instance is extremely important to enable stress and vulnerability testing, as well as to optimize for cost and performance. Recent advances in learned cost models have shown that when enough diverse SQL queries are available, one can effectively and efficiently predict the cost of running a given query against a specific database engine. In this paper, we describe our experience in exploiting modern synthetic data generation techniques, inspired by the generative AI and LLM community, to create high-quality datasets enabling the effective training of such learned cost models. Initial results show that we can improve a learned cost model's predictive accuracy by training it with 45% fewer queries than when using competitive generation approaches.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023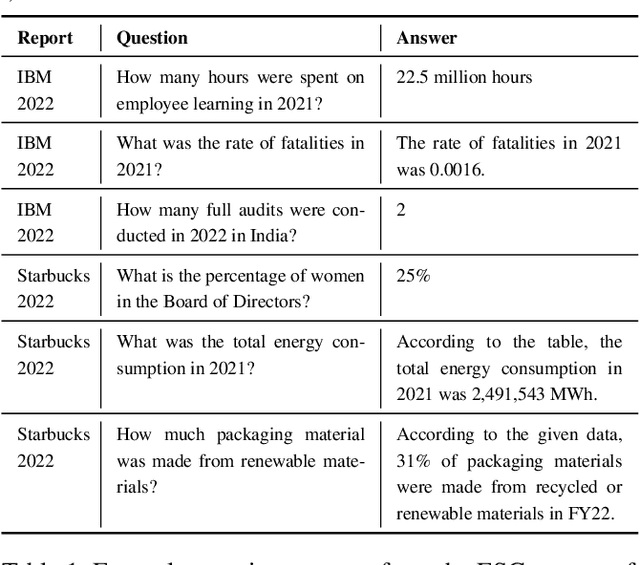
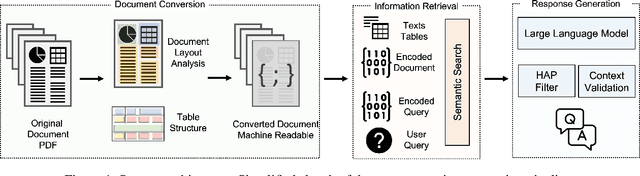
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
Extracting Text Representations for Terms and Phrases in Technical Domains
May 25, 2023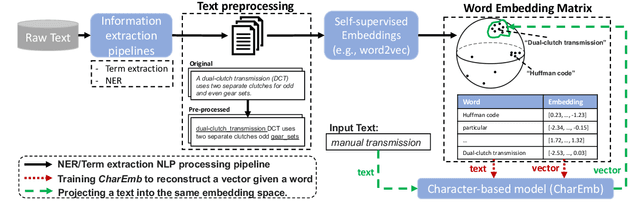
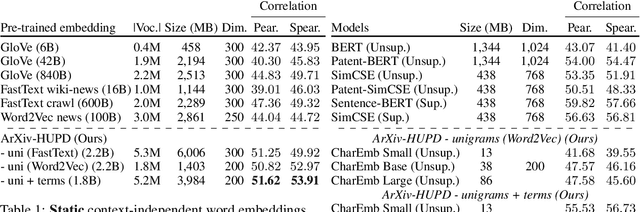
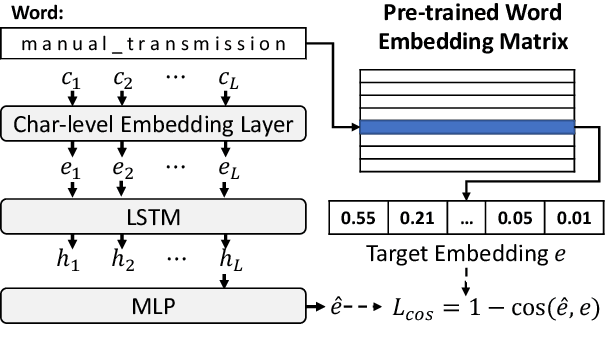

Extracting dense representations for terms and phrases is a task of great importance for knowledge discovery platforms targeting highly-technical fields. Dense representations are used as features for downstream components and have multiple applications ranging from ranking results in search to summarization. Common approaches to create dense representations include training domain-specific embeddings with self-supervised setups or using sentence encoder models trained over similarity tasks. In contrast to static embeddings, sentence encoders do not suffer from the out-of-vocabulary (OOV) problem, but impose significant computational costs. In this paper, we propose a fully unsupervised approach to text encoding that consists of training small character-based models with the objective of reconstructing large pre-trained embedding matrices. Models trained with this approach can not only match the quality of sentence encoders in technical domains, but are 5 times smaller and up to 10 times faster, even on high-end GPUs.
Unsupervised Term Extraction for Highly Technical Domains
Oct 24, 2022
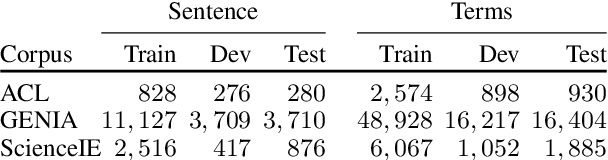
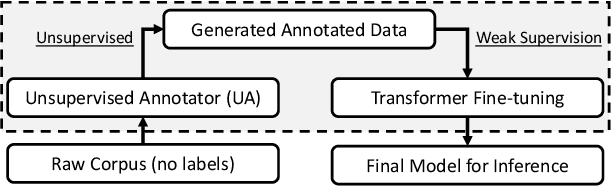

Term extraction is an information extraction task at the root of knowledge discovery platforms. Developing term extractors that are able to generalize across very diverse and potentially highly technical domains is challenging, as annotations for domains requiring in-depth expertise are scarce and expensive to obtain. In this paper, we describe the term extraction subsystem of a commercial knowledge discovery platform that targets highly technical fields such as pharma, medical, and material science. To be able to generalize across domains, we introduce a fully unsupervised annotator (UA). It extracts terms by combining novel morphological signals from sub-word tokenization with term-to-topic and intra-term similarity metrics, computed using general-domain pre-trained sentence-encoders. The annotator is used to implement a weakly-supervised setup, where transformer-models are fine-tuned (or pre-trained) over the training data generated by running the UA over large unlabeled corpora. Our experiments demonstrate that our setup can improve the predictive performance while decreasing the inference latency on both CPUs and GPUs. Our annotators provide a very competitive baseline for all the cases where annotations are not available.
pNLP-Mixer: an Efficient all-MLP Architecture for Language
Feb 09, 2022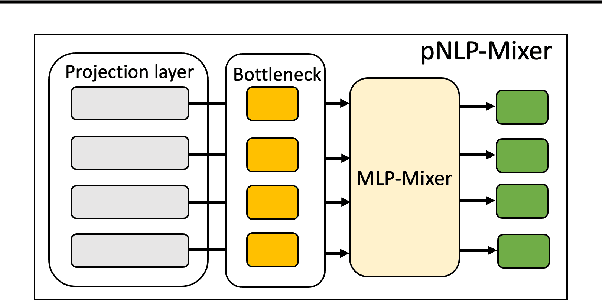
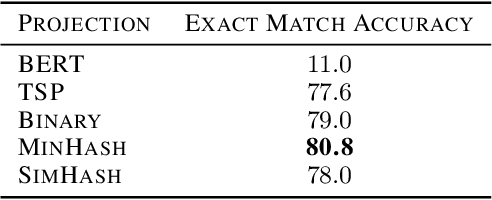
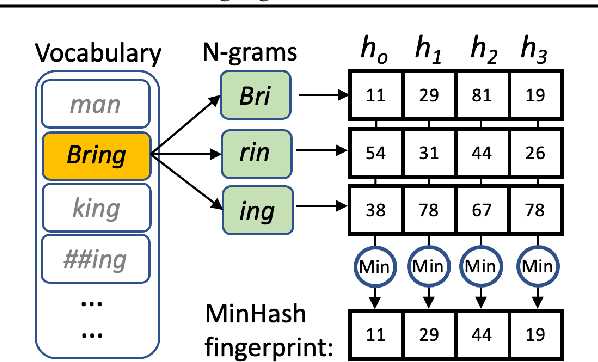
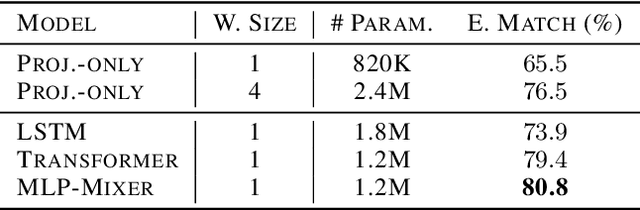
Large pre-trained language models drastically changed the natural language processing(NLP) landscape. Nowadays, they represent the go-to framework to tackle diverse NLP tasks, even with a limited number of annotations. However, using those models in production, either in the cloud or at the edge, remains a challenge due to the memory footprint and/or inference costs. As an alternative, recent work on efficient NLP has shown that small weight-efficient models can reach competitive performance at a fraction of the costs. Here, we introduce pNLP-Mixer, an embbedding-free model based on the MLP-Mixer architecture that achieves high weight-efficiency thanks to a novel linguistically informed projection layer. We evaluate our model on two multi-lingual semantic parsing datasets, MTOP and multiATIS. On MTOP our pNLP-Mixer almost matches the performance of mBERT, which has 38 times more parameters, and outperforms the state-of-the-art of tiny models (pQRNN) with 3 times fewer parameters. On a long-sequence classification task (Hyperpartisan) our pNLP-Mixer without pretraining outperforms RoBERTa, which has 100 times more parameters, demonstrating the potential of this architecture.
Knowledge- and Data-driven Services for Energy Systems using Graph Neural Networks
Mar 12, 2021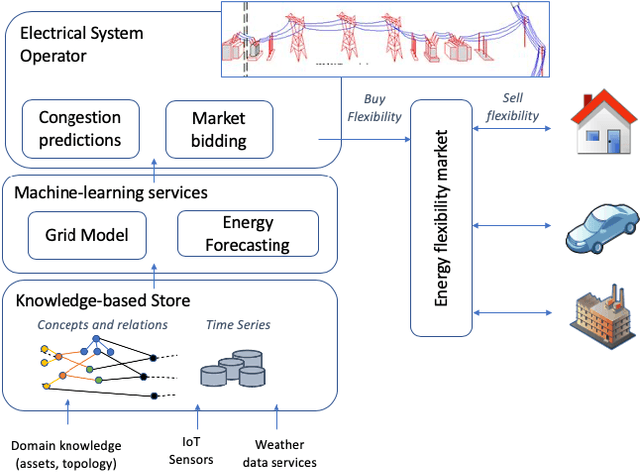
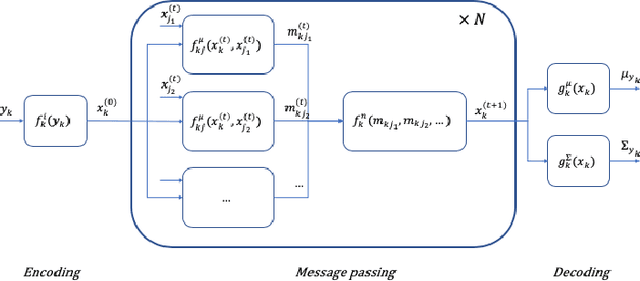
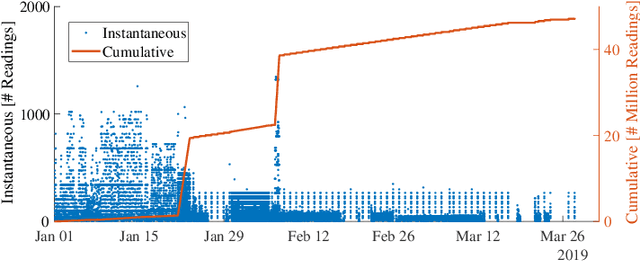
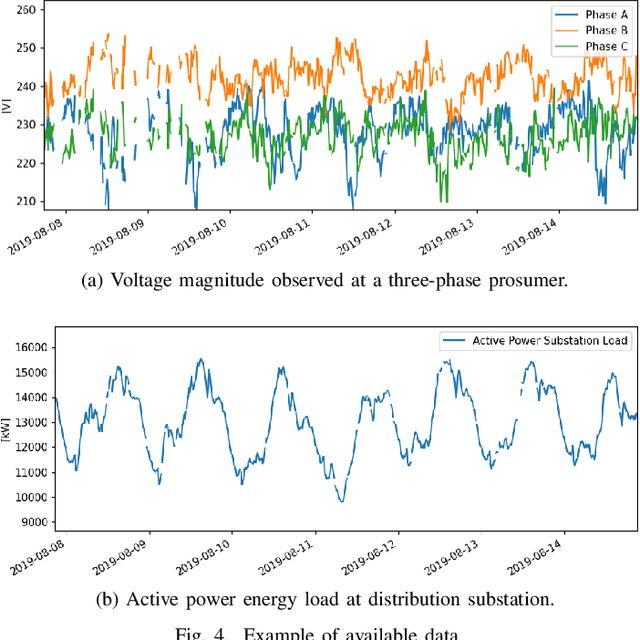
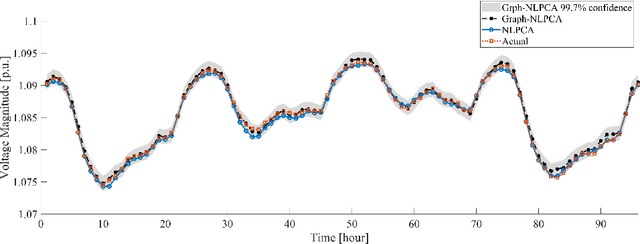
The transition away from carbon-based energy sources poses several challenges for the operation of electricity distribution systems. Increasing shares of distributed energy resources (e.g. renewable energy generators, electric vehicles) and internet-connected sensing and control devices (e.g. smart heating and cooling) require new tools to support accurate, datadriven decision making. Modelling the effect of such growing complexity in the electrical grid is possible in principle using state-of-the-art power-power flow models. In practice, the detailed information needed for these physical simulations may be unknown or prohibitively expensive to obtain. Hence, datadriven approaches to power systems modelling, including feedforward neural networks and auto-encoders, have been studied to leverage the increasing availability of sensor data, but have seen limited practical adoption due to lack of transparency and inefficiencies on large-scale problems. Our work addresses this gap by proposing a data- and knowledge-driven probabilistic graphical model for energy systems based on the framework of graph neural networks (GNNs). The model can explicitly factor in domain knowledge, in the form of grid topology or physics constraints, thus resulting in sparser architectures and much smaller parameters dimensionality when compared with traditional machine-learning models with similar accuracy. Results obtained from a real-world smart-grid demonstration project show how the GNN was used to inform grid congestion predictions and market bidding services for a distribution system operator participating in an energy flexibility market.
Scalable Deployment of AI Time-series Models for IoT
Mar 24, 2020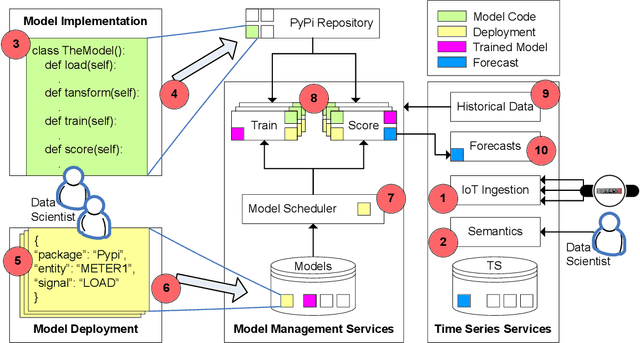

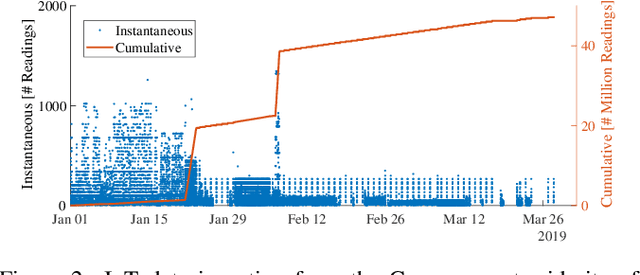
IBM Research Castor, a cloud-native system for managing and deploying large numbers of AI time-series models in IoT applications, is described. Modelling code templates, in Python and R, following a typical machine-learning workflow are supported. A knowledge-based approach to managing model and time-series data allows the use of general semantic concepts for expressing feature engineering tasks. Model templates can be programmatically deployed against specific instances of semantic concepts, thus supporting model reuse and automated replication as the IoT application grows. Deployed models are automatically executed in parallel leveraging a serverless cloud computing framework. The complete history of trained model versions and rolling-horizon predictions is persisted, thus enabling full model lineage and traceability. Results from deployments in real-world smart-grid live forecasting applications are reported. Scalability of executing up to tens of thousands of AI modelling tasks is also evaluated.
Probabilistic Graphs for Sensor Data-driven Modelling of Power Systems at Scale
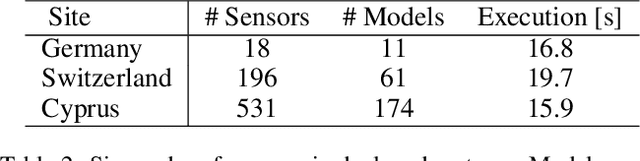
Nov 18, 2018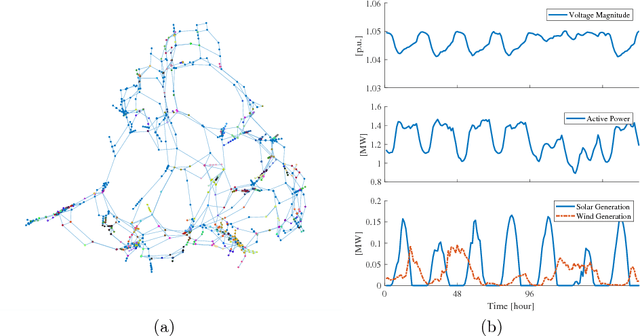

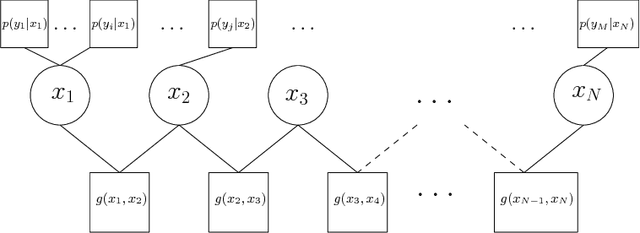
The growing complexity of the power grid, driven by increasing share of distributed energy resources and by massive deployment of intelligent internet-connected devices, requires new modelling tools for planning and operation. Physics-based state estimation models currently used for data filtering, prediction and anomaly detection are hard to maintain and adapt to the ever-changing complex dynamics of the power system. A data-driven approach based on probabilistic graphs is proposed, where custom non-linear, localised models of the joint density of subset of system variables can be combined to model arbitrarily large and complex systems. The graphical model allows to naturally embed domain knowledge in the form of variables dependency structure or local quantitative relationships. A specific instance where neural-network models are used to represent the local joint densities is proposed, although the methodology generalises to other model classes. Accuracy and scalability are evaluated on a large-scale data set representative of the European transmission grid.
Learning Correlation Space for Time Series
May 15, 2018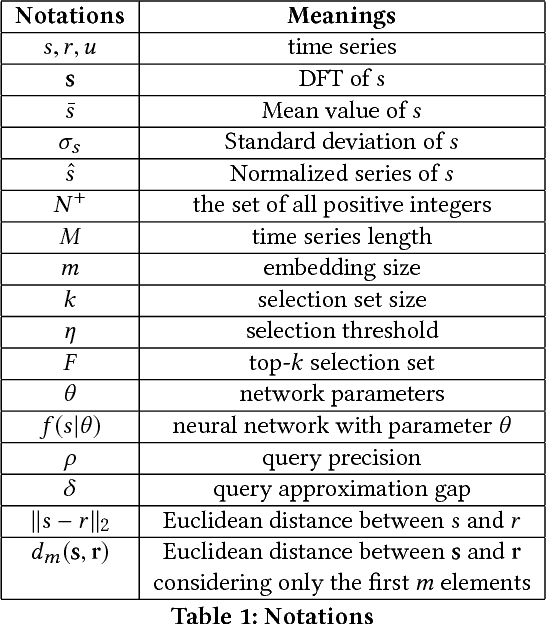
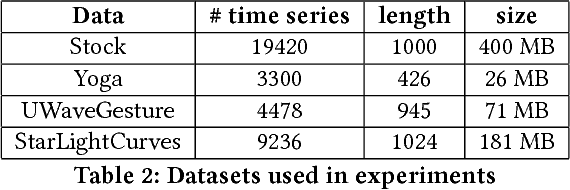
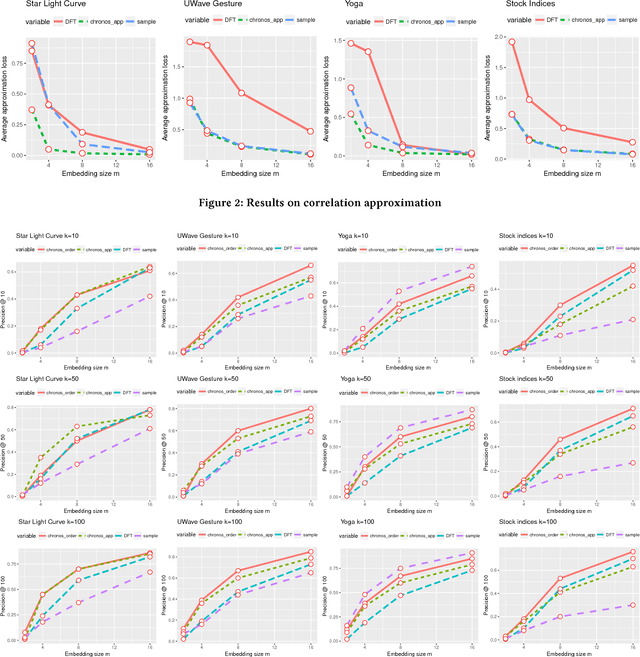
We propose an approximation algorithm for efficient correlation search in time series data. In our method, we use Fourier transform and neural network to embed time series into a low-dimensional Euclidean space. The given space is learned such that time series correlation can be effectively approximated from Euclidean distance between corresponding embedded vectors. Therefore, search for correlated time series can be done using an index in the embedding space for efficient nearest neighbor search. Our theoretical analysis illustrates that our method's accuracy can be guaranteed under certain regularity conditions. We further conduct experiments on real-world datasets and the results show that our method indeed outperforms the baseline solution. In particular, for approximation of correlation, our method reduces the approximation loss by a half in most test cases compared to the baseline solution. For top-$k$ highest correlation search, our method improves the precision from 5\% to 20\% while the query time is similar to the baseline approach query time.
Power Systems Data Fusion based on Belief Propagation
May 24, 2017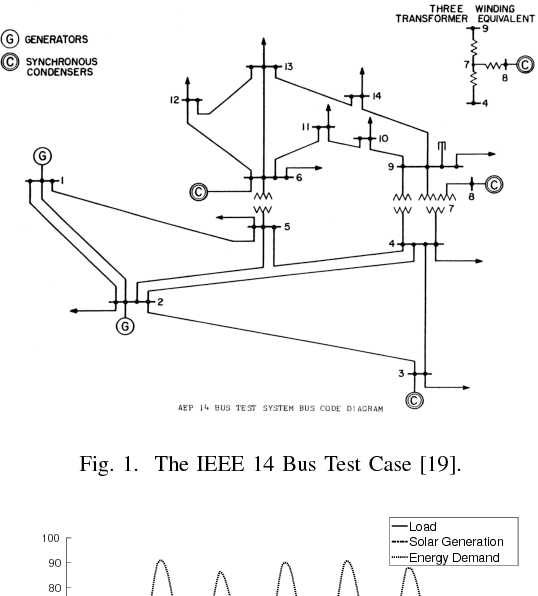
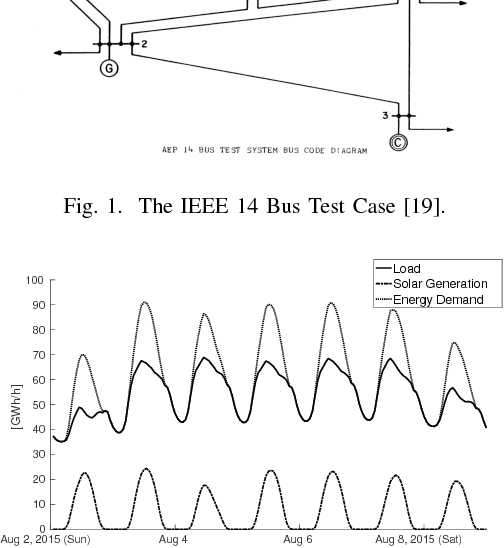
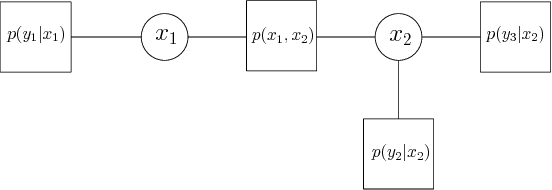
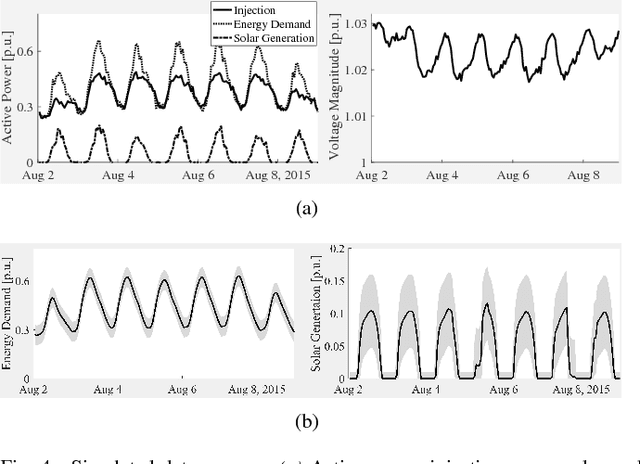
The increasing complexity of the power grid, due to higher penetration of distributed resources and the growing availability of interconnected, distributed metering devices re- quires novel tools for providing a unified and consistent view of the system. A computational framework for power systems data fusion, based on probabilistic graphical models, capable of combining heterogeneous data sources with classical state estimation nodes and other customised computational nodes, is proposed. The framework allows flexible extension of the notion of grid state beyond the view of flows and injection in bus-branch models, and an efficient, naturally distributed inference algorithm can be derived. An application of the data fusion model to the quantification of distributed solar energy is proposed through numerical examples based on semi-synthetic simulations of the standard IEEE 14-bus test case.