 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your RAG: Dataset Taxonomy and Generation Strategies for Evaluating RAG Systems
Nov 29, 2024
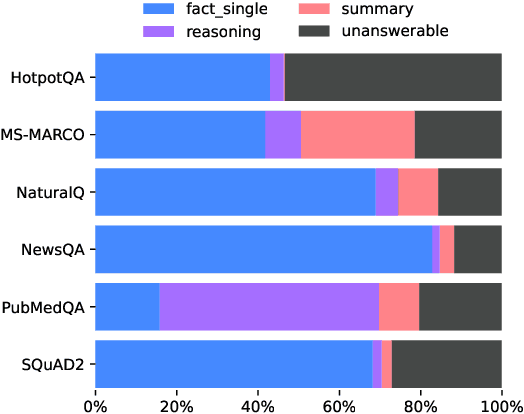
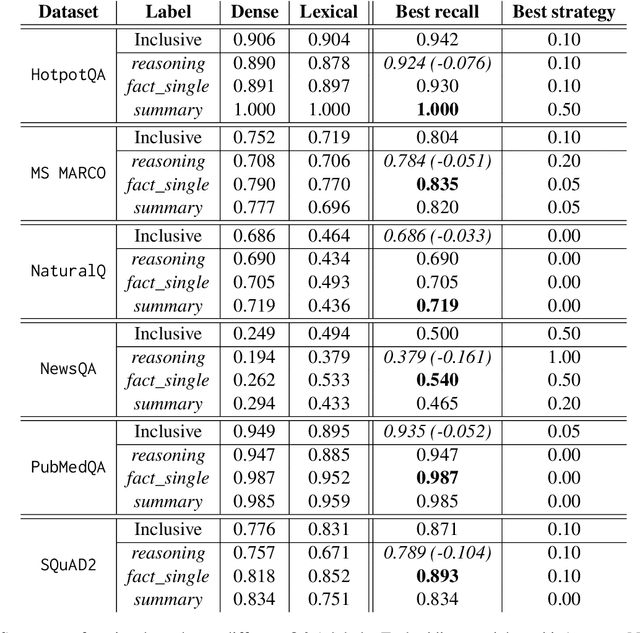
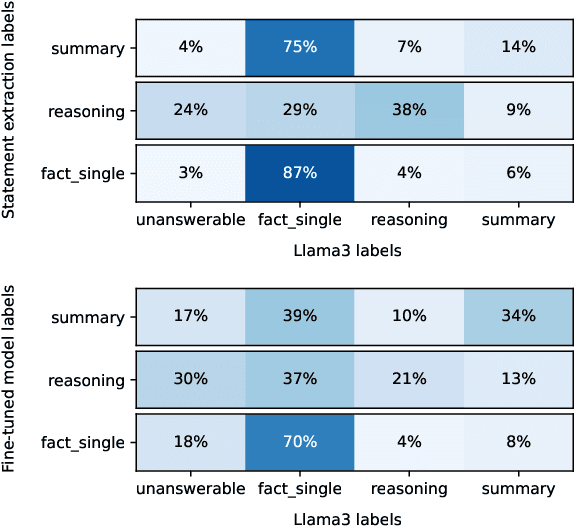
Retrieval Augmented Generation (RAG) systems are a widespread application of Large Language Models (LLMs) in the industry. While many tools exist empowering developers to build their own systems, measuring their performance locally, with datasets reflective of the system's use cases, is a technological challenge. Solutions to this problem range from non-specific and cheap (most public datasets) to specific and costly (generating data from local documents). In this paper, we show that using public question and answer (Q&A) datasets to assess retrieval performance can lead to non-optimal systems design, and that common tools for RAG dataset generation can lead to unbalanced data. We propose solutions to these issues based on the characterization of RAG datasets through labels and through label-targeted data generation. Finally, we show that fine-tuned small LLMs can efficiently generate Q&A datasets. We believe that these observations are invaluable to the know-your-data step of RAG systems development.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023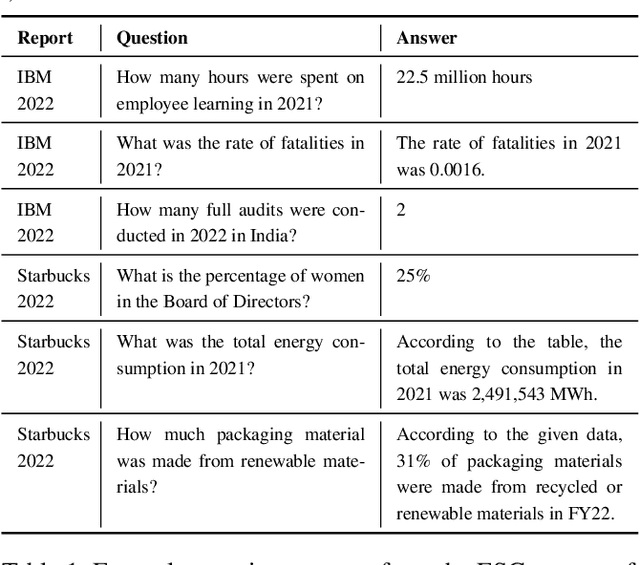
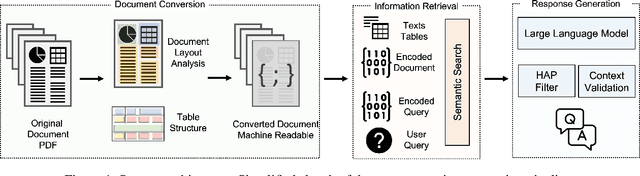
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
On the explainability of hospitalization prediction on a large COVID-19 patient dataset
Oct 28, 2021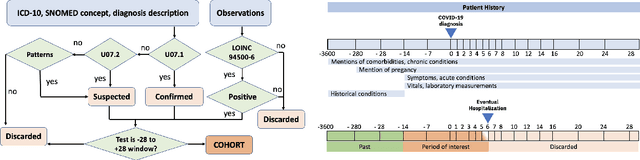
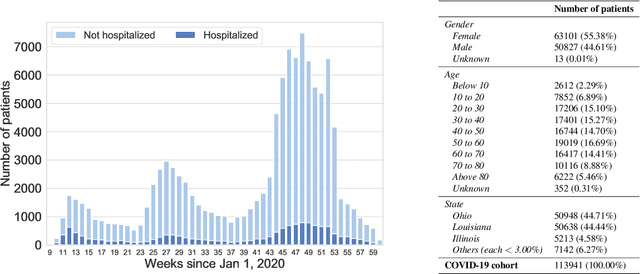
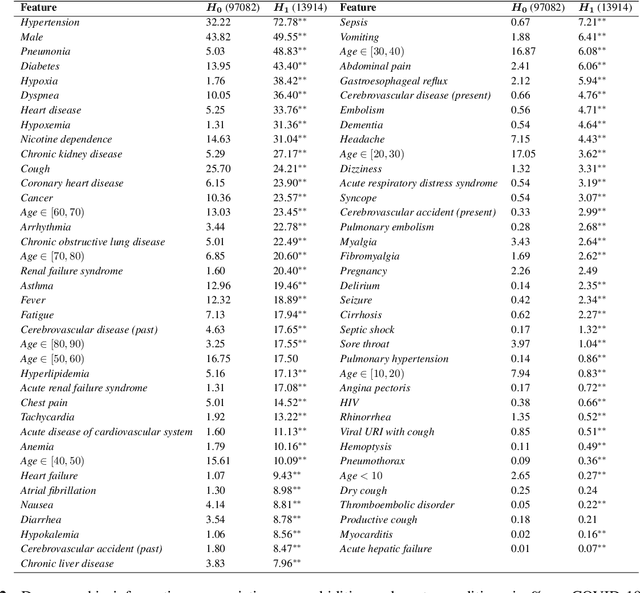
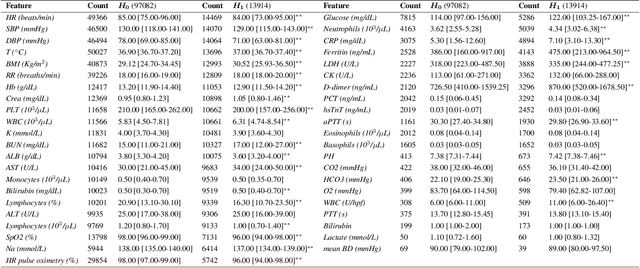
We develop various AI models to predict hospitalization on a large (over 110$k$) cohort of COVID-19 positive-tested US patients, sourced from March 2020 to February 2021. Models range from Random Forest to Neural Network (NN) and Time Convolutional NN, where combination of the data modalities (tabular and time dependent) are performed at different stages (early vs. model fusion). Despite high data unbalance, the models reach average precision 0.96-0.98 (0.75-0.85), recall 0.96-0.98 (0.74-0.85), and $F_1$-score 0.97-0.98 (0.79-0.83) on the non-hospitalized (or hospitalized) class. Performances do not significantly drop even when selected lists of features are removed to study model adaptability to different scenarios. However, a systematic study of the SHAP feature importance values for the developed models in the different scenarios shows a large variability across models and use cases. This calls for even more complete studies on several explainability methods before their adoption in high-stakes scenarios.