 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your RAG: Dataset Taxonomy and Generation Strategies for Evaluating RAG Systems
Paper and Code

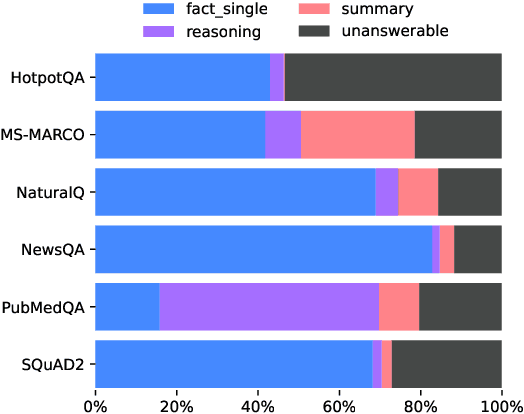
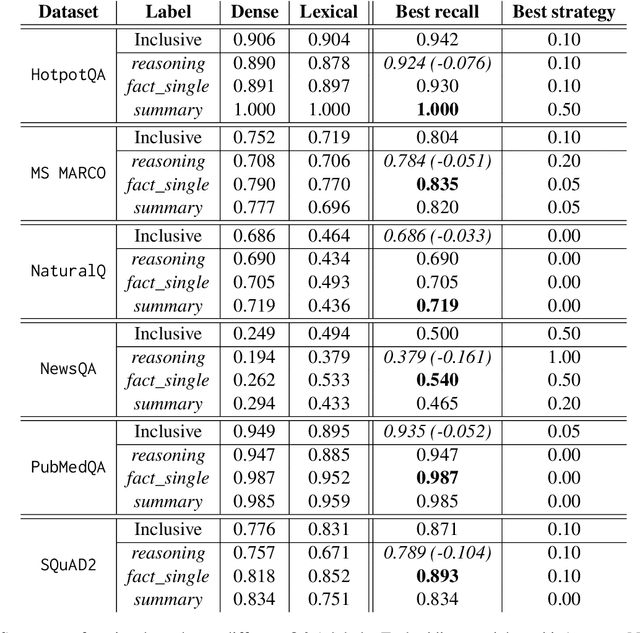
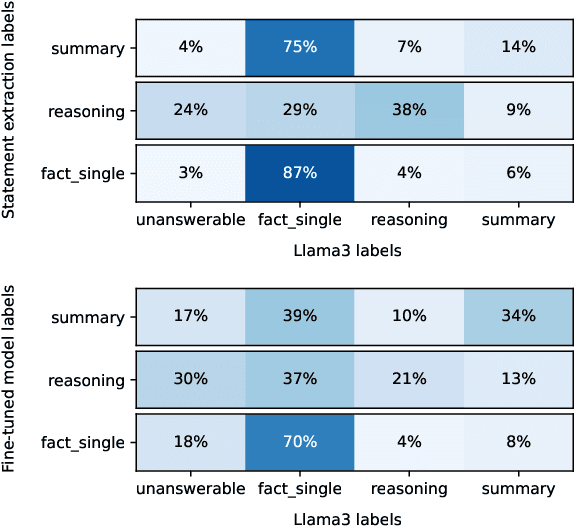
Retrieval Augmented Generation (RAG) systems are a widespread application of Large Language Models (LLMs) in the industry. While many tools exist empowering developers to build their own systems, measuring their performance locally, with datasets reflective of the system's use cases, is a technological challenge. Solutions to this problem range from non-specific and cheap (most public datasets) to specific and costly (generating data from local documents). In this paper, we show that using public question and answer (Q&A) datasets to assess retrieval performance can lead to non-optimal systems design, and that common tools for RAG dataset generation can lead to unbalanced data. We propose solutions to these issues based on the characterization of RAG datasets through labels and through label-targeted data generation. Finally, we show that fine-tuned small LLMs can efficiently generate Q&A datasets. We believe that these observations are invaluable to the know-your-data step of RAG systems development.