 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELT-Bench-Verified: Benchmark Quality Issues Underestimate AI Agent Capabilities
Apr 02, 2026Constructing Extract-Load-Transform (ELT) pipelines is a labor-intensive data engineering task and a high-impact target for AI automation. On ELT-Bench, the first benchmark for end-to-end ELT pipeline construction, AI agents initially showed low success rates, suggesting they lacked practical utility. We revisit these results and identify two factors causing a substantial underestimation of agent capabilities. First, re-evaluating ELT-Bench with upgraded large language models reveals that the extraction and loading stage is largely solved, while transformation performance improves significantly. Second, we develop an Auditor-Corrector methodology that combines scalable LLM-driven root-cause analysis with rigorous human validation (inter-annotator agreement Fleiss' kappa = 0.85) to audit benchmark quality. Applying this to ELT-Bench uncovers that most failed transformation tasks contain benchmark-attributable errors -- including rigid evaluation scripts, ambiguous specifications, and incorrect ground truth -- that penalize correct agent outputs. Based on these findings, we construct ELT-Bench-Verified, a revised benchmark with refined evaluation logic and corrected ground truth. Re-evaluating on this version yields significant improvement attributable entirely to benchmark correction. Our results show that both rapid model improvement and benchmark quality issues contributed to underestimating agent capabilities. More broadly, our findings echo observations of pervasive annotation errors in text-to-SQL benchmarks, suggesting quality issues are systemic in data engineering evaluation. Systematic quality auditing should be standard practice for complex agentic tasks. We release ELT-Bench-Verified to provide a more reliable foundation for progress in AI-driven data engineering automation.
Process Supervision for Chain-of-Thought Reasoning via Monte Carlo Net Information Gain
Mar 18, 2026Multi-step reasoning improves the capabilities of large language models (LLMs) but increases the risk of errors propagating through intermediate steps. Process reward models (PRMs) mitigate this by scoring each step individually, enabling fine-grained supervision and improved reliability. Existing methods for training PRMs rely on costly human annotations or computationally intensive automatic labeling. We propose a novel approach to automatically generate step-level labels using Information Theory. Our method estimates how each reasoning step affects the likelihood of the correct answer, providing a signal of step quality. Importantly, it reduces computational complexity to $\mathcal{O}(N)$, improving over the previous $\mathcal{O}(N \log N)$ methods. We demonstrate that these labels enable effective chain-of-thought selection in best-of-$K$ evaluation settings across diverse reasoning benchmarks, including mathematics, Python programming, SQL, and scientific question answering. This work enables scalable and efficient supervision of LLM reasoning, particularly for tasks where error propagation is critical.
Bootstrapping Learned Cost Models with Synthetic SQL Queries
Aug 27, 2025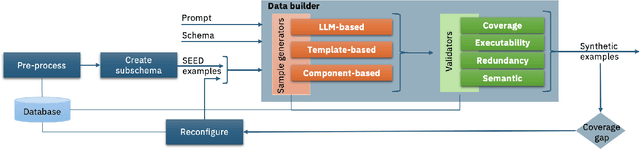

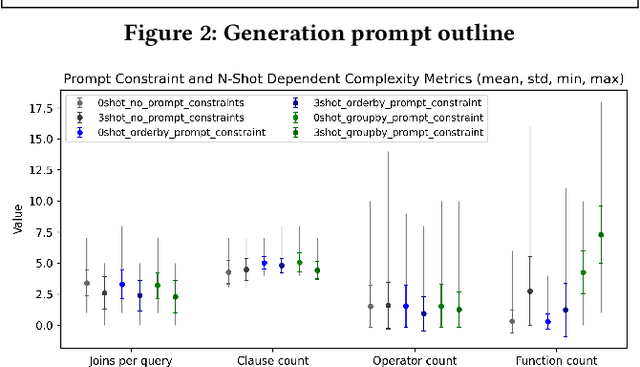
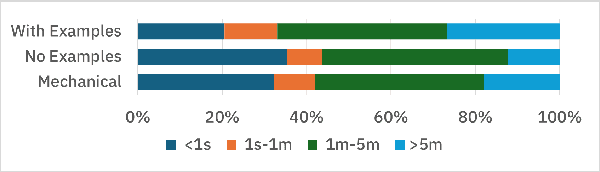
Having access to realistic workloads for a given database instance is extremely important to enable stress and vulnerability testing, as well as to optimize for cost and performance. Recent advances in learned cost models have shown that when enough diverse SQL queries are available, one can effectively and efficiently predict the cost of running a given query against a specific database engine. In this paper, we describe our experience in exploiting modern synthetic data generation techniques, inspired by the generative AI and LLM community, to create high-quality datasets enabling the effective training of such learned cost models. Initial results show that we can improve a learned cost model's predictive accuracy by training it with 45% fewer queries than when using competitive generation approaches.
MaxCorrMGNN: A Multi-Graph Neural Network Framework for Generalized Multimodal Fusion of Medical Data for Outcome Prediction
Jul 13, 2023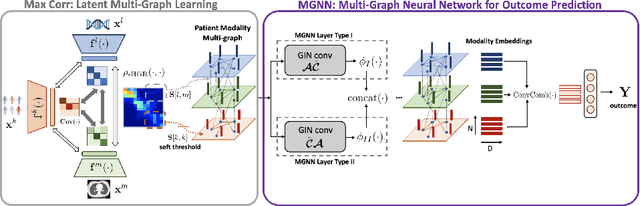
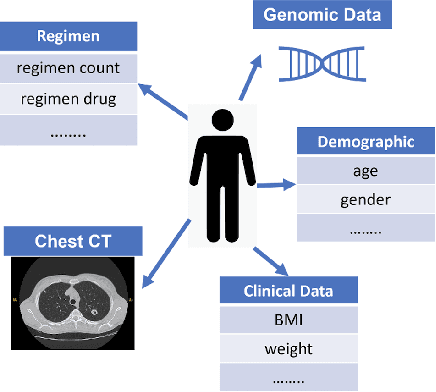
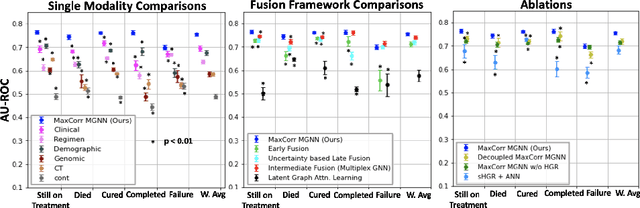
With the emergence of multimodal electronic health records, the evidence for an outcome may be captured across multiple modalities ranging from clinical to imaging and genomic data. Predicting outcomes effectively requires fusion frameworks capable of modeling fine-grained and multi-faceted complex interactions between modality features within and across patients. We develop an innovative fusion approach called MaxCorr MGNN that models non-linear modality correlations within and across patients through Hirschfeld-Gebelein-Renyi maximal correlation (MaxCorr) embeddings, resulting in a multi-layered graph that preserves the identities of the modalities and patients. We then design, for the first time, a generalized multi-layered graph neural network (MGNN) for task-informed reasoning in multi-layered graphs, that learns the parameters defining patient-modality graph connectivity and message passing in an end-to-end fashion. We evaluate our model an outcome prediction task on a Tuberculosis (TB) dataset consistently outperforming several state-of-the-art neural, graph-based and traditional fusion techniques.
Fusing Modalities by Multiplexed Graph Neural Networks for Outcome Prediction in Tuberculosis
Oct 25, 2022In a complex disease such as tuberculosis, the evidence for the disease and its evolution may be present in multiple modalities such as clinical, genomic, or imaging data. Effective patient-tailored outcome prediction and therapeutic guidance will require fusing evidence from these modalities. Such multimodal fusion is difficult since the evidence for the disease may not be uniform across all modalities, not all modality features may be relevant, or not all modalities may be present for all patients. All these nuances make simple methods of early, late, or intermediate fusion of features inadequate for outcome prediction. In this paper, we present a novel fusion framework using multiplexed graphs and derive a new graph neural network for learning from such graphs. Specifically, the framework allows modalities to be represented through their targeted encodings, and models their relationship explicitly via multiplexed graphs derived from salient features in a combined latent space. We present results that show that our proposed method outperforms state-of-the-art methods of fusing modalities for multi-outcome prediction on a large Tuberculosis (TB) dataset.
Towards Interpretable Summary Evaluation via Allocation of Contextual Embeddings to Reference Text Topics
Oct 25, 2022



Despite extensive recent advances in summary generation models, evaluation of auto-generated summaries still widely relies on single-score systems insufficient for transparent assessment and in-depth qualitative analysis. Towards bridging this gap, we propose the multifaceted interpretable summary evaluation method (MISEM), which is based on allocation of a summary's contextual token embeddings to semantic topics identified in the reference text. We further contribute an interpretability toolbox for automated summary evaluation and interactive visual analysis of summary scoring, topic identification, and token-topic allocation. MISEM achieves a promising .404 Pearson correlation with human judgment on the TAC'08 dataset.
On the explainability of hospitalization prediction on a large COVID-19 patient dataset
Oct 28, 2021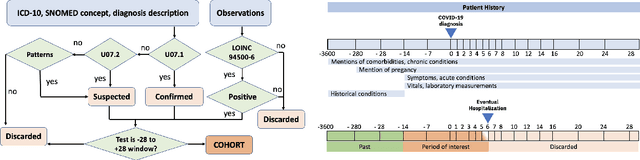
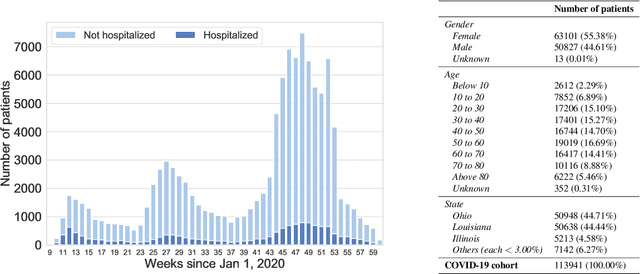
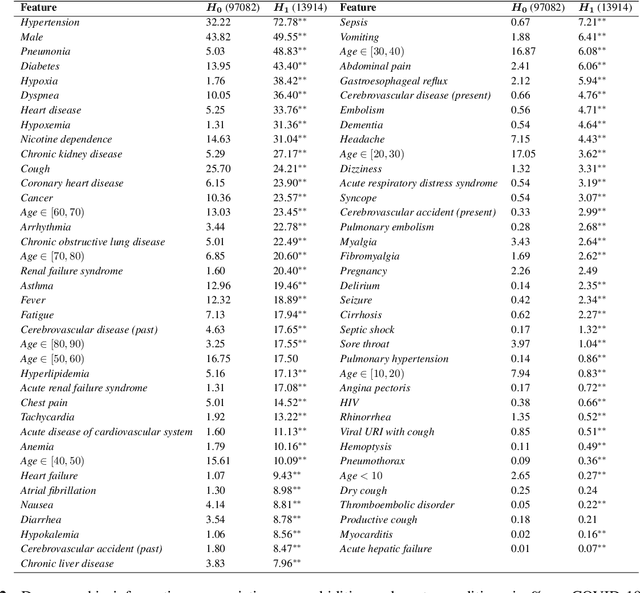
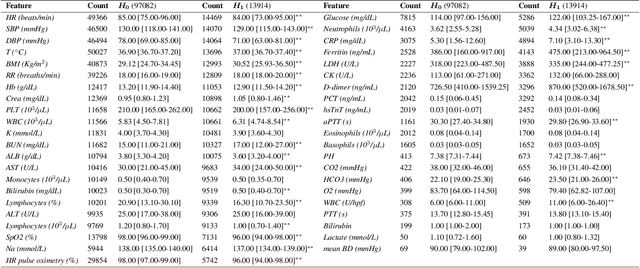
We develop various AI models to predict hospitalization on a large (over 110$k$) cohort of COVID-19 positive-tested US patients, sourced from March 2020 to February 2021. Models range from Random Forest to Neural Network (NN) and Time Convolutional NN, where combination of the data modalities (tabular and time dependent) are performed at different stages (early vs. model fusion). Despite high data unbalance, the models reach average precision 0.96-0.98 (0.75-0.85), recall 0.96-0.98 (0.74-0.85), and $F_1$-score 0.97-0.98 (0.79-0.83) on the non-hospitalized (or hospitalized) class. Performances do not significantly drop even when selected lists of features are removed to study model adaptability to different scenarios. However, a systematic study of the SHAP feature importance values for the developed models in the different scenarios shows a large variability across models and use cases. This calls for even more complete studies on several explainability methods before their adoption in high-stakes scenarios.
Chest ImaGenome Dataset for Clinical Reasoning
Jul 31, 2021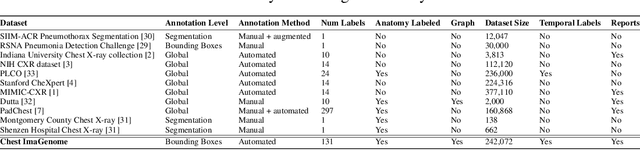
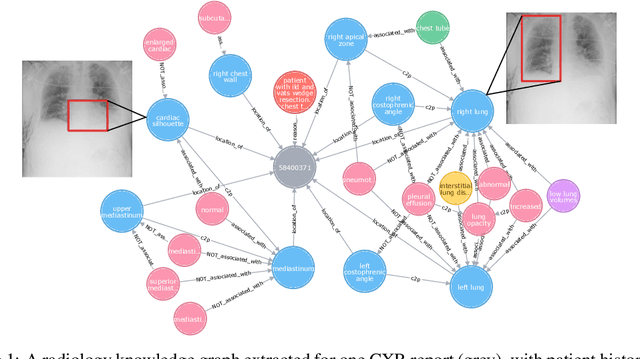
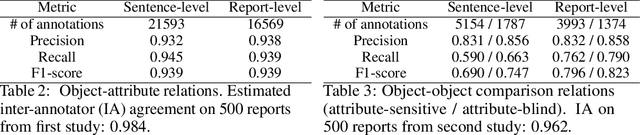

Despite the progress in automatic detection of radiologic findings from chest X-ray (CXR) images in recent years, a quantitative evaluation of the explainability of these models is hampered by the lack of locally labeled datasets for different findings. With the exception of a few expert-labeled small-scale datasets for specific findings, such as pneumonia and pneumothorax, most of the CXR deep learning models to date are trained on global "weak" labels extracted from text reports, or trained via a joint image and unstructured text learning strategy. Inspired by the Visual Genome effort in the computer vision community, we constructed the first Chest ImaGenome dataset with a scene graph data structure to describe $242,072$ images. Local annotations are automatically produced using a joint rule-based natural language processing (NLP) and atlas-based bounding box detection pipeline. Through a radiologist constructed CXR ontology, the annotations for each CXR are connected as an anatomy-centered scene graph, useful for image-level reasoning and multimodal fusion applications. Overall, we provide: i) $1,256$ combinations of relation annotations between $29$ CXR anatomical locations (objects with bounding box coordinates) and their attributes, structured as a scene graph per image, ii) over $670,000$ localized comparison relations (for improved, worsened, or no change) between the anatomical locations across sequential exams, as well as ii) a manually annotated gold standard scene graph dataset from $500$ unique patients.
Match What Matters: Generative Implicit Feature Replay for Continual Learning
Jun 09, 2021
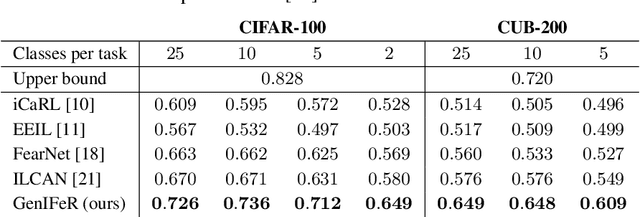
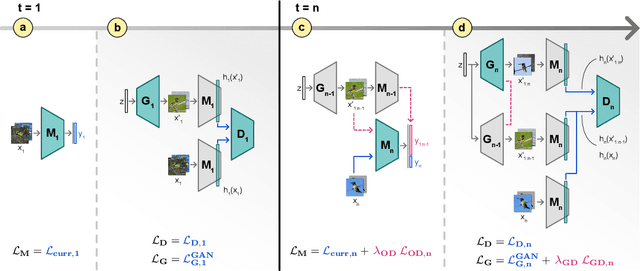

Neural networks are prone to catastrophic forgetting when trained incrementally on different tasks. In order to prevent forgetting, most existing methods retain a small subset of previously seen samples, which in turn can be used for joint training with new tasks. While this is indeed effective, it may not always be possible to store such samples, e.g., due to data protection regulations. In these cases, one can instead employ generative models to create artificial samples or features representing memories from previous tasks. Following a similar direction, we propose GenIFeR (Generative Implicit Feature Replay) for class-incremental learning. The main idea is to train a generative adversarial network (GAN) to generate images that contain realistic features. While the generator creates images at full resolution, the discriminator only sees the corresponding features extracted by the continually trained classifier. Since the classifier compresses raw images into features that are actually relevant for classification, the GAN can match this target distribution more accurately. On the other hand, allowing the generator to create full resolution images has several benefits: In contrast to previous approaches, the feature extractor of the classifier does not have to be frozen. In addition, we can employ augmentations on generated images, which not only boosts classification performance, but also mitigates discriminator overfitting during GAN training. We empirically show that GenIFeR is superior to both conventional generative image and feature replay. In particular, we significantly outperform the state-of-the-art in generative replay for various settings on the CIFAR-100 and CUB-200 datasets.
Artificial Intelligence Decision Support for Medical Triage
Nov 09, 2020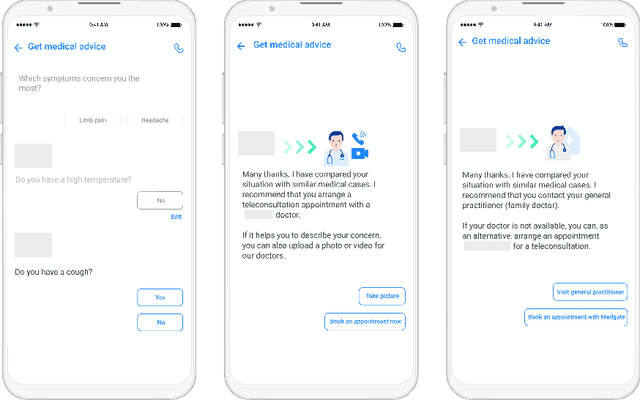
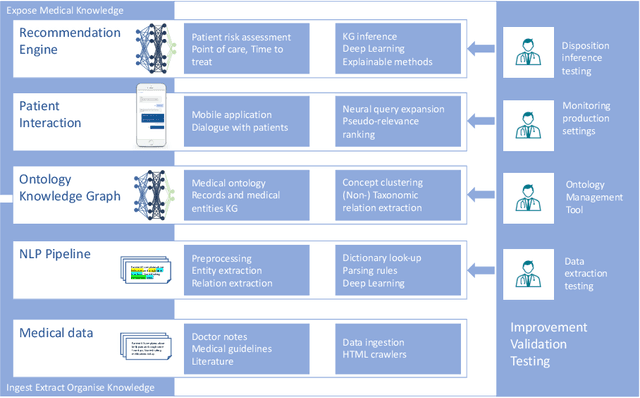
Applying state-of-the-art machine learning and natural language processing on approximately one million of teleconsultation records, we developed a triage system, now certified and in use at the largest European telemedicine provider. The system evaluates care alternatives through interactions with patients via a mobile application. Reasoning on an initial set of provided symptoms, the triage application generates AI-powered, personalized questions to better characterize the problem and recommends the most appropriate point of care and time frame for a consultation. The underlying technology was developed to meet the needs for performance, transparency, user acceptance and ease of use, central aspects to the adoption of AI-based decision support systems. Providing such remote guidance at the beginning of the chain of care has significant potential for improving cost efficiency, patient experience and outcomes. Being remote, always available and highly scalable, this service is fundamental in high demand situations, such as the current COVID-19 outbreak.