 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChest ImaGenome Dataset for Clinical Reasoning
Jul 31, 2021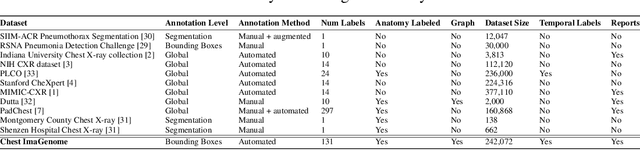
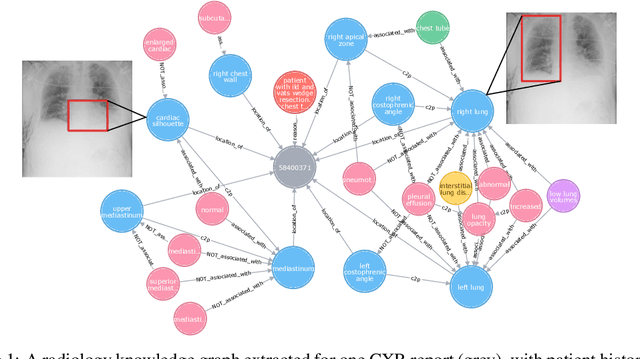
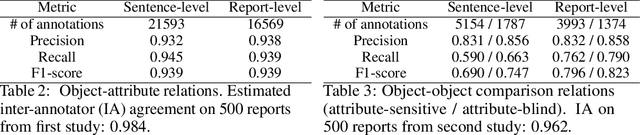

Despite the progress in automatic detection of radiologic findings from chest X-ray (CXR) images in recent years, a quantitative evaluation of the explainability of these models is hampered by the lack of locally labeled datasets for different findings. With the exception of a few expert-labeled small-scale datasets for specific findings, such as pneumonia and pneumothorax, most of the CXR deep learning models to date are trained on global "weak" labels extracted from text reports, or trained via a joint image and unstructured text learning strategy. Inspired by the Visual Genome effort in the computer vision community, we constructed the first Chest ImaGenome dataset with a scene graph data structure to describe $242,072$ images. Local annotations are automatically produced using a joint rule-based natural language processing (NLP) and atlas-based bounding box detection pipeline. Through a radiologist constructed CXR ontology, the annotations for each CXR are connected as an anatomy-centered scene graph, useful for image-level reasoning and multimodal fusion applications. Overall, we provide: i) $1,256$ combinations of relation annotations between $29$ CXR anatomical locations (objects with bounding box coordinates) and their attributes, structured as a scene graph per image, ii) over $670,000$ localized comparison relations (for improved, worsened, or no change) between the anatomical locations across sequential exams, as well as ii) a manually annotated gold standard scene graph dataset from $500$ unique patients.
Exploring Quality and Generalizability in Parameterized Neural Audio Effects
Jun 10, 2020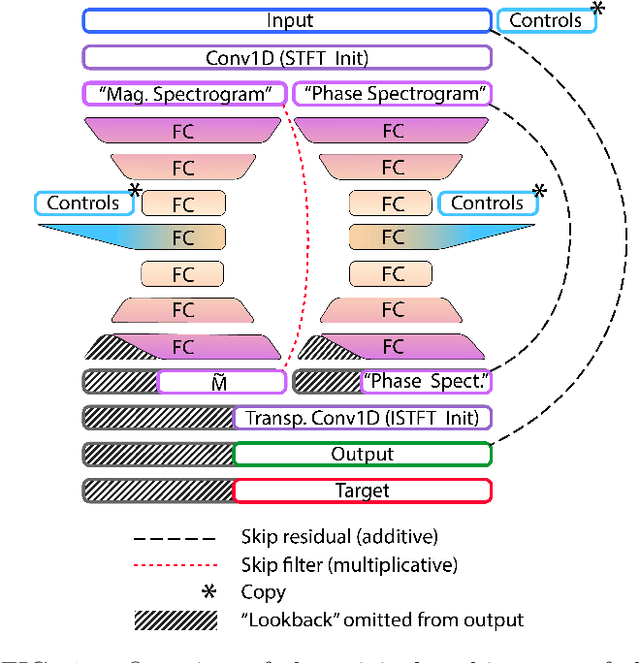
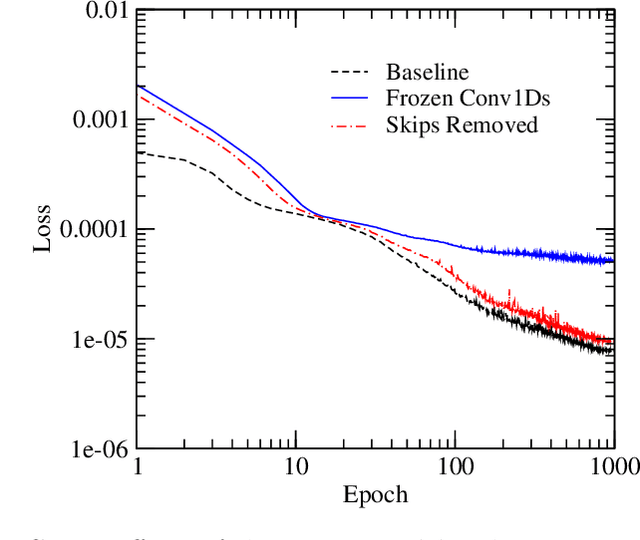
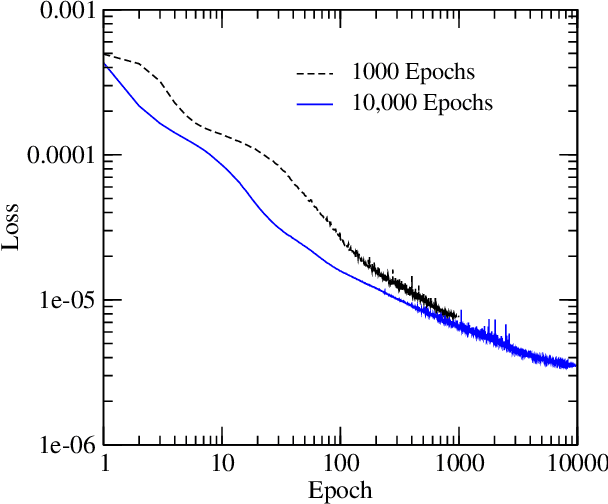
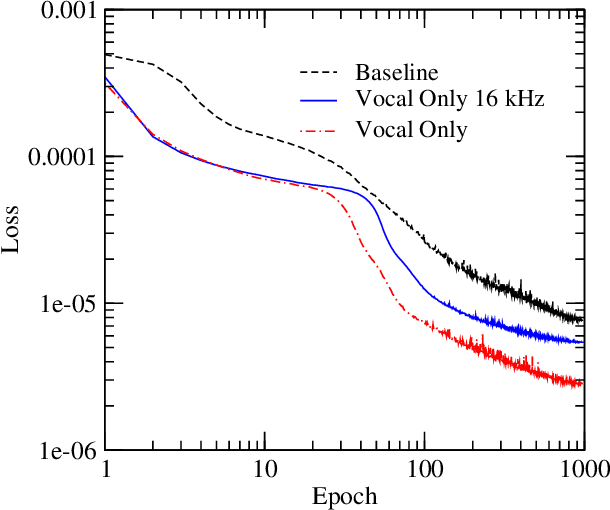
Deep neural networks have shown promise for music audio signal processing applications, often surpassing prior approaches, particularly as end-to-end models in the waveform domain. Yet results to date have tended to be constrained by low sample rates, noise, narrow domains of signal types, and/or lack of parameterized controls (i.e. "knobs"), making their suitability for professional audio engineering workflows still lacking. This work expands on prior research published on modeling nonlinear time-dependent signal processing effects associated with music production by means of a deep neural network, one which includes the ability to emulate the parameterized settings you would see on an analog piece of equipment, with the goal of eventually producing commercially viable, high quality audio, i.e. 44.1 kHz sampling rate at 16-bit resolution. The results in this paper highlight progress in modeling these effects through architecture and optimization changes, towards increasing computational efficiency, lowering signal-to-noise ratio, and extending to a larger variety of nonlinear audio effects. Toward these ends, the strategies employed involved a three-pronged approach: model speed, model accuracy, and model generalizability. Most of the presented methods provide marginal or no increase in output accuracy over the original model, with the exception of dataset manipulation. We found that limiting the audio content of the dataset, for example using datasets of just a single instrument, provided a significant improvement in model accuracy over models trained on more general datasets.