 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePictures Of MIDI: Controlled Music Generation via Graphical Prompts for Image-Based Diffusion Inpainting
Jul 01, 2024



Recent years have witnessed significant progress in generative models for music, featuring diverse architectures that balance output quality, diversity, speed, and user control. This study explores a user-friendly graphical interface enabling the drawing of masked regions for inpainting by an Hourglass Diffusion Transformer (HDiT) model trained on MIDI piano roll images. To enhance note generation in specified areas, masked regions can be "repainted" with extra noise. The non-latent HDiTs linear scaling with pixel count allows efficient generation in pixel space, providing intuitive and interpretable controls such as masking throughout the network and removing the need to operate in compressed latent spaces such as those provided by pretrained autoencoders. We demonstrate that, in addition to inpainting of melodies, accompaniment, and continuations, the use of repainting can help increase note density yielding musical structures closely matching user specifications such as rising, falling, or diverging melody and/or accompaniment, even when these lie outside the typical training data distribution. We achieve performance on par with prior results while operating at longer context windows, with no autoencoder, and can enable complex geometries for inpainting masks, increasing the options for machine-assisted composers to control the generated music.
Operational Latent Spaces
Jun 04, 2024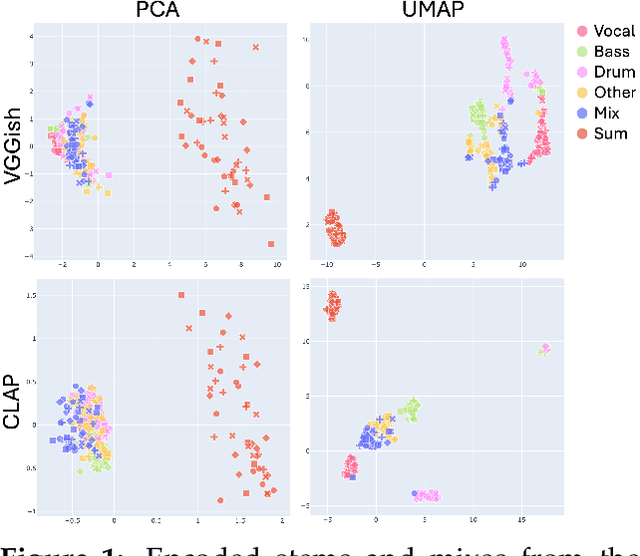
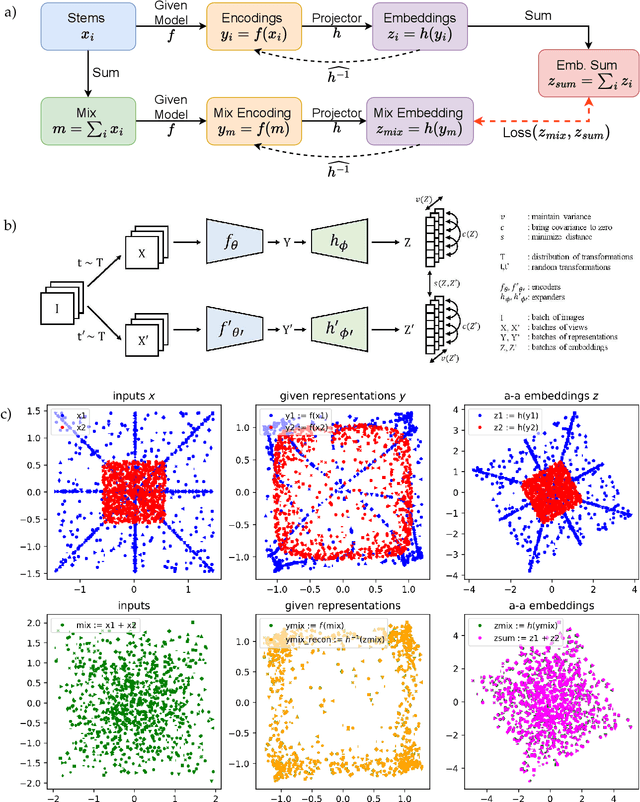


We investigate the construction of latent spaces through self-supervised learning to support semantically meaningful operations. Analogous to operational amplifiers, these "operational latent spaces" (OpLaS) not only demonstrate semantic structure such as clustering but also support common transformational operations with inherent semantic meaning. Some operational latent spaces are found to have arisen "unintentionally" in the progress toward some (other) self-supervised learning objective, in which unintended but still useful properties are discovered among the relationships of points in the space. Other spaces may be constructed "intentionally" by developers stipulating certain kinds of clustering or transformations intended to produce the desired structure. We focus on the intentional creation of operational latent spaces via self-supervised learning, including the introduction of rotation operators via a novel "FiLMR" layer, which can be used to enable ring-like symmetries found in some musical constructions.
Fast Timing-Conditioned Latent Audio Diffusion
Feb 08, 2024Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
Leveraging Neural Representations for Audio Manipulation
Apr 10, 2023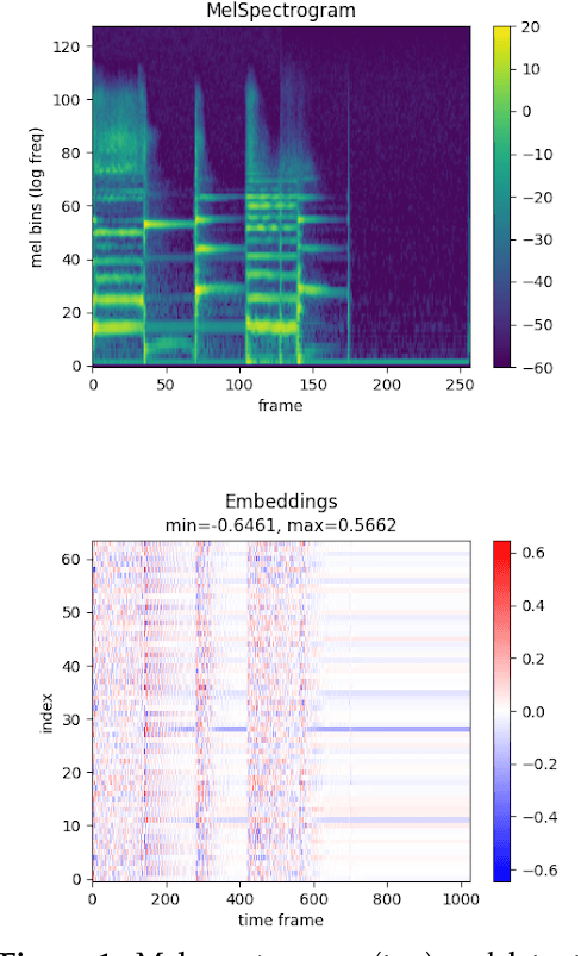

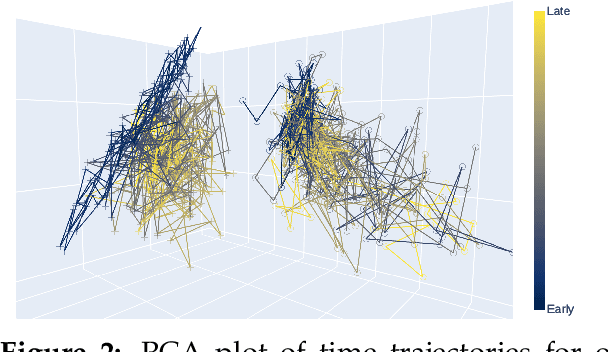
We investigate applying audio manipulations using pretrained neural network-based autoencoders as an alternative to traditional signal processing methods, since the former may provide greater semantic or perceptual organization. To establish the potential of this approach, we first establish if representations from these models encode information about manipulations. We carry out experiments and produce visualizations using representations from two different pretrained autoencoders. Our findings indicate that, while some information about audio manipulations is encoded, this information is both limited and encoded in a non-trivial way. This is supported by our attempts to visualize these representations, which demonstrated that trajectories of representations for common manipulations are typically nonlinear and content dependent, even for linear signal manipulations. As a result, it is not yet clear how these pretrained autoencoders can be used to manipulate audio signals, however, our results indicate this may be due to the lack of disentanglement with respect to common audio manipulations.
espiownage: Tracking Transients in Steelpan Drum Strikes Using Surveillance Technology
Oct 23, 2021



We present an improvement in the ability to meaningfully track features in high speed videos of Caribbean steelpan drums illuminated by Electronic Speckle Pattern Interferometry (ESPI). This is achieved through the use of up-to-date computer vision libraries for object detection and image segmentation as well as a significant effort toward cleaning the dataset previously used to train systems for this application. Besides improvements on previous metric scores by 10% or more, noteworthy in this project are the introduction of a segmentation-regression map for the entire drum surface yielding interference fringe counts comparable to those obtained via object detection, as well as the accelerated workflow for coordinating the data-cleaning-and-model-training feedback loop for rapid iteration allowing this project to be conducted on a timescale of only 18 days.
ConvNets for Counting: Object Detection of Transient Phenomena in Steelpan Drums
Feb 01, 2021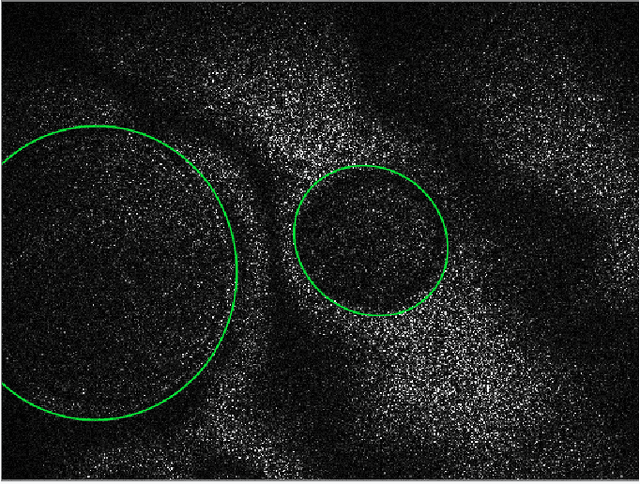
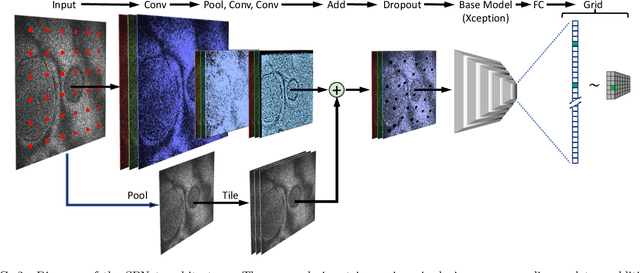

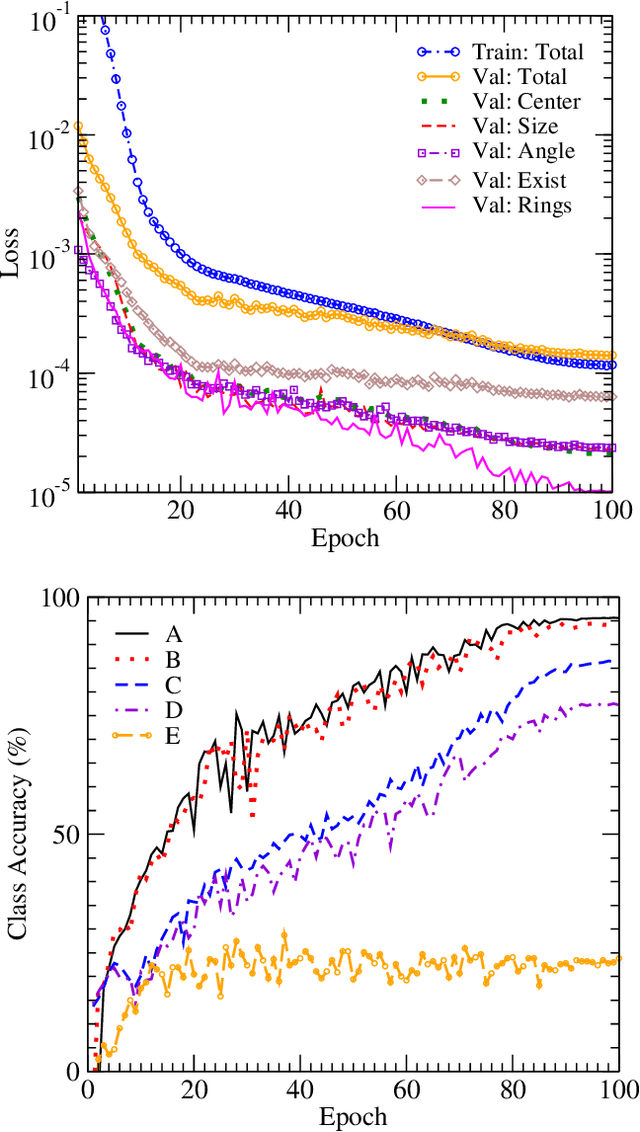
We train an object detector built from convolutional neural networks to count interference fringes in elliptical antinode regions visible in frames of high-speed video recordings of transient oscillations in Caribbean steelpan drums illuminated by electronic speckle pattern interferometry (ESPI). The annotations provided by our model, "SPNet" are intended to contribute to the understanding of time-dependent behavior in such drums by tracking the development of sympathetic vibration modes. The system is trained on a dataset of crowdsourced human-annotated images obtained from the Zooniverse Steelpan Vibrations Project. Due to the relatively small number of human-annotated images, we also train on a large corpus of synthetic images whose visual properties have been matched to those of the real images by using a Generative Adversarial Network to perform style transfer. Applying the model to predict annotations of thousands of unlabeled video frames, we can track features and measure oscillations consistent with audio recordings of the same drum strikes. One surprising result is that the machine-annotated video frames reveal transitions between the first and second harmonics of drum notes that significantly precede such transitions present in the audio recordings. As this paper primarily concerns the development of the model, deeper physical insights await its further application.
Exploring Quality and Generalizability in Parameterized Neural Audio Effects
Jun 10, 2020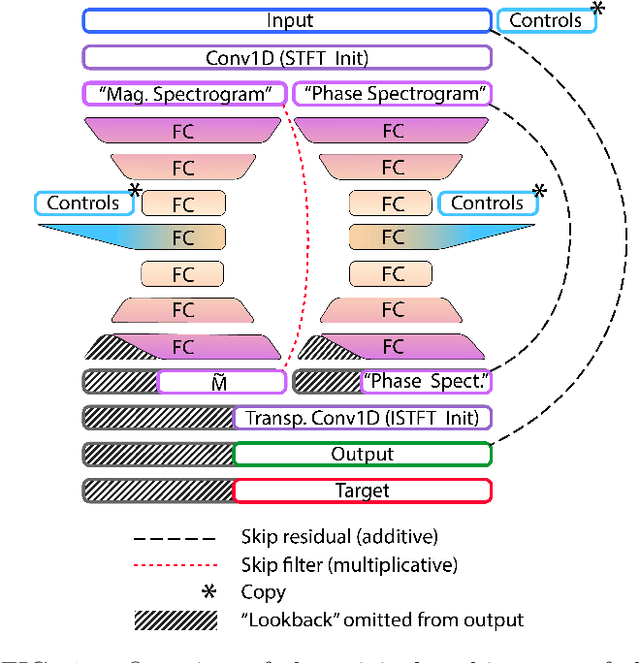
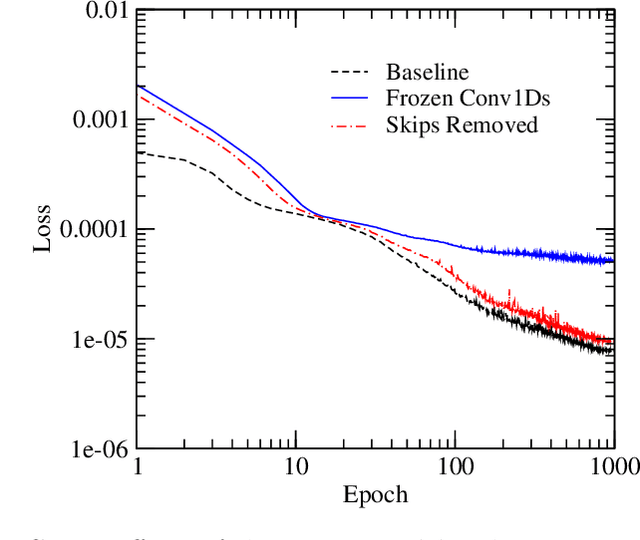
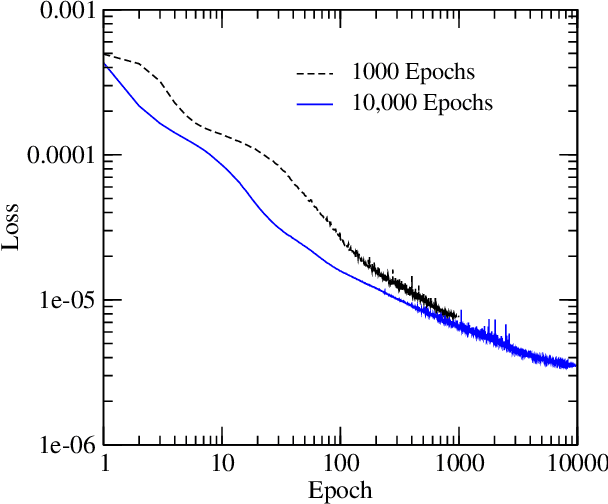
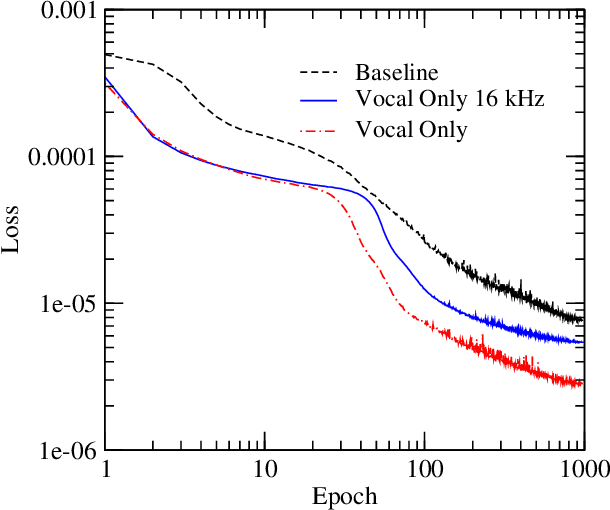
Deep neural networks have shown promise for music audio signal processing applications, often surpassing prior approaches, particularly as end-to-end models in the waveform domain. Yet results to date have tended to be constrained by low sample rates, noise, narrow domains of signal types, and/or lack of parameterized controls (i.e. "knobs"), making their suitability for professional audio engineering workflows still lacking. This work expands on prior research published on modeling nonlinear time-dependent signal processing effects associated with music production by means of a deep neural network, one which includes the ability to emulate the parameterized settings you would see on an analog piece of equipment, with the goal of eventually producing commercially viable, high quality audio, i.e. 44.1 kHz sampling rate at 16-bit resolution. The results in this paper highlight progress in modeling these effects through architecture and optimization changes, towards increasing computational efficiency, lowering signal-to-noise ratio, and extending to a larger variety of nonlinear audio effects. Toward these ends, the strategies employed involved a three-pronged approach: model speed, model accuracy, and model generalizability. Most of the presented methods provide marginal or no increase in output accuracy over the original model, with the exception of dataset manipulation. We found that limiting the audio content of the dataset, for example using datasets of just a single instrument, provided a significant improvement in model accuracy over models trained on more general datasets.
SignalTrain: Profiling Audio Compressors with Deep Neural Networks
May 30, 2019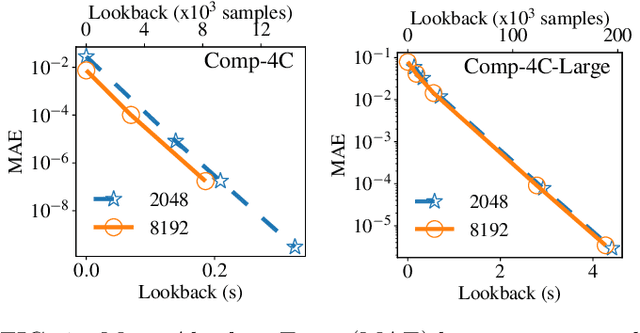
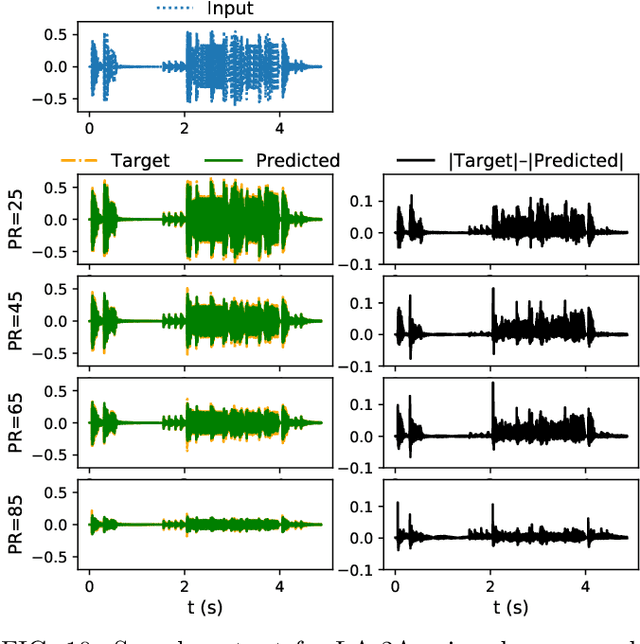
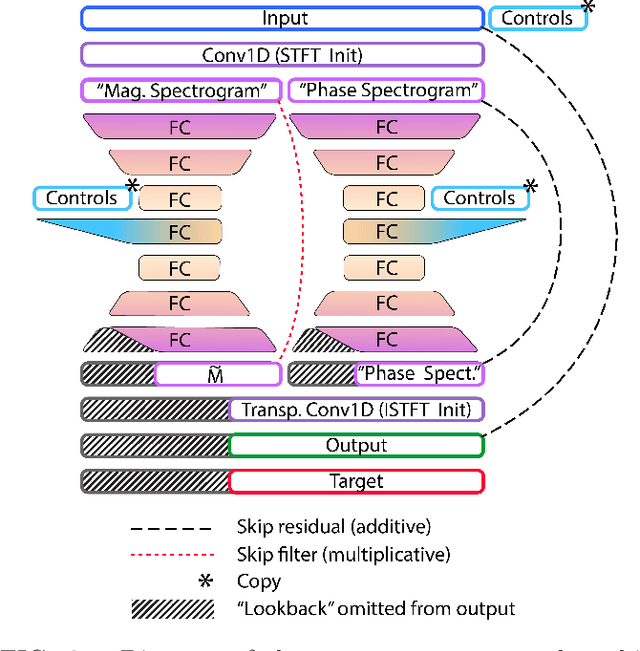
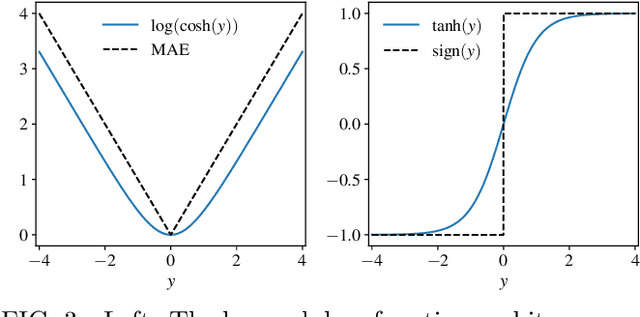
In this work we present a data-driven approach for predicting the behavior of (i.e., profiling) a given non-linear audio signal processing effect (henceforth "audio effect"). Our objective is to learn a mapping function that maps the unprocessed audio to the processed by the audio effect to be profiled, using time-domain samples. To that aim, we employ a deep auto-encoder model that is conditioned on both time-domain samples and the control parameters of the target audio effect. As a test-case study, we focus on the offline profiling of two dynamic range compression audio effects, one software-based and the other analog. Compressors were chosen because they are a widely used and important set of effects and because their parameterized nonlinear time-dependent nature makes them a challenging problem for a system aiming to profile "general" audio effects. Results from our experimental procedure show that the primary functional and auditory characteristics of the compressors can be captured, however there is still sufficient audible noise to merit further investigation before such methods are applied to real-world audio processing workflows.
Challenges for an Ontology of Artificial Intelligence
Feb 25, 2019Of primary importance in formulating a response to the increasing prevalence and power of artificial intelligence (AI) applications in society are questions of ontology. Questions such as: What "are" these systems? How are they to be regarded? How does an algorithm come to be regarded as an agent? We discuss three factors which hinder discussion and obscure attempts to form a clear ontology of AI: (1) the various and evolving definitions of AI, (2) the tendency for pre-existing technologies to be assimilated and regarded as "normal," and (3) the tendency of human beings to anthropomorphize. This list is not intended as exhaustive, nor is it seen to preclude entirely a clear ontology, however, these challenges are a necessary set of topics for consideration. Each of these factors is seen to present a 'moving target' for discussion, which poses a challenge for both technical specialists and non-practitioners of AI systems development (e.g., philosophers and theologians) to speak meaningfully given that the corpus of AI structures and capabilities evolves at a rapid pace. Finally, we present avenues for moving forward, including opportunities for collaborative synthesis for scholars in philosophy and science.