 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAME: A Semantically-Aligned Music Autoencoder
May 18, 2026Latent representations are at the heart of the majority of modern generative models. In the audio domain they are typically produced by a neural-audio-codec autoencoder. In this work we introduce SAME (Semantically-Aligned Music autoEncoder), an autoencoder for stereo music and general audio that reaches a 4096$\times$ temporal compression ratio while maintaining reconstruction quality and downstream generative performance. We achieve this by combining a tranformer-based backbone with set of semantic regularisation approaches, phase-aware reconstruction losses and improved discriminator designs. The architecture delivers substantial computational cost benefits, through both its high compression ratio and its reliance on well-optimised transformer primitives. Two variants (a large SAME-L and a CPU-deployable SAME-S) are released in open-weights form.
Low-Resource Guidance for Controllable Latent Audio Diffusion
Mar 04, 2026Generative audio requires fine-grained controllable outputs, yet most existing methods require model retraining on specific controls or inference-time controls (\textit{e.g.}, guidance) that can also be computationally demanding. By examining the bottlenecks of existing guidance-based controls, in particular their high cost-per-step due to decoder backpropagation, we introduce a guidance-based approach through selective TFG and Latent-Control Heads (LatCHs), which enables controlling latent audio diffusion models with low computational overhead. LatCHs operate directly in latent space, avoiding the expensive decoder step, and requiring minimal training resources (7M parameters and $\approx$ 4 hours of training). Experiments with Stable Audio Open demonstrate effective control over intensity, pitch, and beats (and a combination of those) while maintaining generation quality. Our method balances precision and audio fidelity with far lower computational costs than standard end-to-end guidance. Demo examples can be found at https://zacharynovack.github.io/latch/latch.html.
Fast Text-to-Audio Generation with Adversarial Post-Training
May 14, 2025Text-to-audio systems, while increasingly performant, are slow at inference time, thus making their latency unpractical for many creative applications. We present Adversarial Relativistic-Contrastive (ARC) post-training, the first adversarial acceleration algorithm for diffusion/flow models not based on distillation. While past adversarial post-training methods have struggled to compare against their expensive distillation counterparts, ARC post-training is a simple procedure that (1) extends a recent relativistic adversarial formulation to diffusion/flow post-training and (2) combines it with a novel contrastive discriminator objective to encourage better prompt adherence. We pair ARC post-training with a number optimizations to Stable Audio Open and build a model capable of generating $\approx$12s of 44.1kHz stereo audio in $\approx$75ms on an H100, and $\approx$7s on a mobile edge-device, the fastest text-to-audio model to our knowledge.
Scaling Transformers for Low-Bitrate High-Quality Speech Coding
Nov 29, 2024



The tokenization of speech with neural audio codec models is a vital part of modern AI pipelines for the generation or understanding of speech, alone or in a multimodal context. Traditionally such tokenization models have concentrated on low parameter-count architectures using only components with strong inductive biases. In this work we show that by scaling a transformer architecture with large parameter count to this problem, and applying a flexible Finite Scalar Quantization (FSQ) based bottleneck, it is possible to reach state-of-the-art speech quality at extremely low bit-rates of $400$ or $700$ bits-per-second. The trained models strongly out-perform existing baselines in both objective and subjective tests.
Stable Audio Open
Jul 19, 2024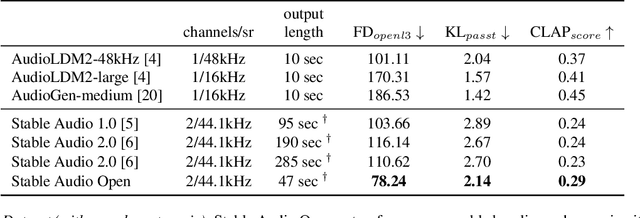
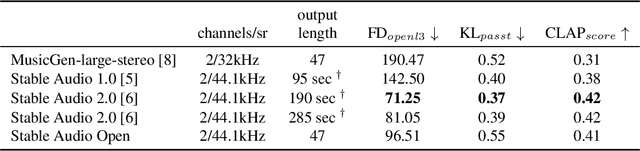
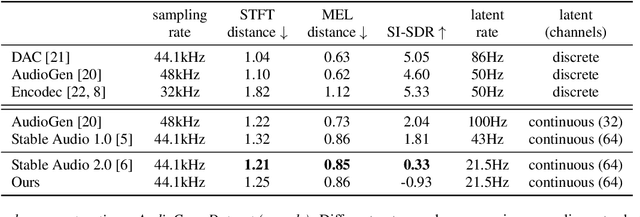
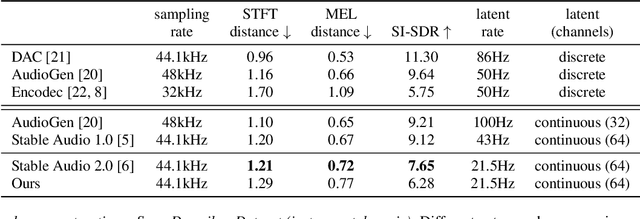
Open generative models are vitally important for the community, allowing for fine-tunes and serving as baselines when presenting new models. However, most current text-to-audio models are private and not accessible for artists and researchers to build upon. Here we describe the architecture and training process of a new open-weights text-to-audio model trained with Creative Commons data. Our evaluation shows that the model's performance is competitive with the state-of-the-art across various metrics. Notably, the reported FDopenl3 results (measuring the realism of the generations) showcase its potential for high-quality stereo sound synthesis at 44.1kHz.
Long-form music generation with latent diffusion
Apr 16, 2024Audio-based generative models for music have seen great strides recently, but so far have not managed to produce full-length music tracks with coherent musical structure. We show that by training a generative model on long temporal contexts it is possible to produce long-form music of up to 4m45s. Our model consists of a diffusion-transformer operating on a highly downsampled continuous latent representation (latent rate of 21.5Hz). It obtains state-of-the-art generations according to metrics on audio quality and prompt alignment, and subjective tests reveal that it produces full-length music with coherent structure.
Fast Timing-Conditioned Latent Audio Diffusion
Feb 08, 2024Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
ProgGP: From GuitarPro Tablature Neural Generation To Progressive Metal Production
Jul 11, 2023Recent work in the field of symbolic music generation has shown value in using a tokenization based on the GuitarPro format, a symbolic representation supporting guitar expressive attributes, as an input and output representation. We extend this work by fine-tuning a pre-trained Transformer model on ProgGP, a custom dataset of 173 progressive metal songs, for the purposes of creating compositions from that genre through a human-AI partnership. Our model is able to generate multiple guitar, bass guitar, drums, piano and orchestral parts. We examine the validity of the generated music using a mixed methods approach by combining quantitative analyses following a computational musicology paradigm and qualitative analyses following a practice-based research paradigm. Finally, we demonstrate the value of the model by using it as a tool to create a progressive metal song, fully produced and mixed by a human metal producer based on AI-generated music.
ShredGP: Guitarist Style-Conditioned Tablature Generation
Jul 11, 2023GuitarPro format tablatures are a type of digital music notation that encapsulates information about guitar playing techniques and fingerings. We introduce ShredGP, a GuitarPro tablature generative Transformer-based model conditioned to imitate the style of four distinct iconic electric guitarists. In order to assess the idiosyncrasies of each guitar player, we adopt a computational musicology methodology by analysing features computed from the tokens yielded by the DadaGP encoding scheme. Statistical analyses of the features evidence significant differences between the four guitarists. We trained two variants of the ShredGP model, one using a multi-instrument corpus, the other using solo guitar data. We present a BERT-based model for guitar player classification and use it to evaluate the generated examples. Overall, results from the classifier show that ShredGP is able to generate content congruent with the style of the targeted guitar player. Finally, we reflect on prospective applications for ShredGP for human-AI music interaction.
GTR-CTRL: Instrument and Genre Conditioning for Guitar-Focused Music Generation with Transformers
Feb 10, 2023Recently, symbolic music generation with deep learning techniques has witnessed steady improvements. Most works on this topic focus on MIDI representations, but less attention has been paid to symbolic music generation using guitar tablatures (tabs) which can be used to encode multiple instruments. Tabs include information on expressive techniques and fingerings for fretted string instruments in addition to rhythm and pitch. In this work, we use the DadaGP dataset for guitar tab music generation, a corpus of over 26k songs in GuitarPro and token formats. We introduce methods to condition a Transformer-XL deep learning model to generate guitar tabs (GTR-CTRL) based on desired instrumentation (inst-CTRL) and genre (genre-CTRL). Special control tokens are appended at the beginning of each song in the training corpus. We assess the performance of the model with and without conditioning. We propose instrument presence metrics to assess the inst-CTRL model's response to a given instrumentation prompt. We trained a BERT model for downstream genre classification and used it to assess the results obtained with the genre-CTRL model. Statistical analyses evidence significant differences between the conditioned and unconditioned models. Overall, results indicate that the GTR-CTRL methods provide more flexibility and control for guitar-focused symbolic music generation than an unconditioned model.
* This preprint is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023