Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Audio Open
Paper and Code
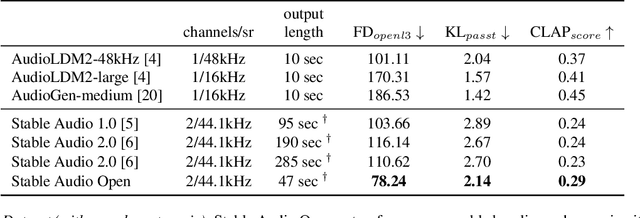
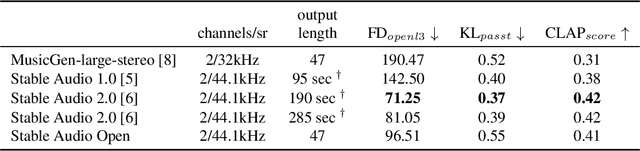
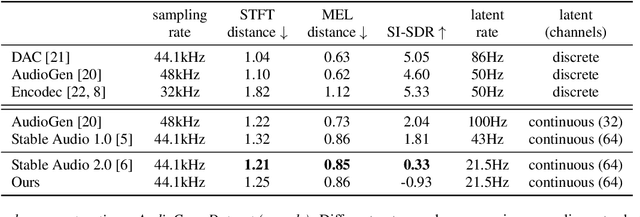
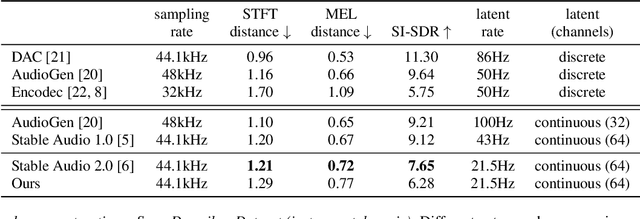
Open generative models are vitally important for the community, allowing for fine-tunes and serving as baselines when presenting new models. However, most current text-to-audio models are private and not accessible for artists and researchers to build upon. Here we describe the architecture and training process of a new open-weights text-to-audio model trained with Creative Commons data. Our evaluation shows that the model's performance is competitive with the state-of-the-art across various metrics. Notably, the reported FDopenl3 results (measuring the realism of the generations) showcase its potential for high-quality stereo sound synthesis at 44.1kHz.
* Demo: https://stability-ai.github.io/stable-audio-open-demo/ Weights:
https://huggingface.co/stabilityai/stable-audio-open-1.0 Code:
https://github.com/Stability-AI/stable-audio-tools. arXiv admin note: text
overlap with arXiv:2404.10301
View paper on