 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxCorrMGNN: A Multi-Graph Neural Network Framework for Generalized Multimodal Fusion of Medical Data for Outcome Prediction
Jul 13, 2023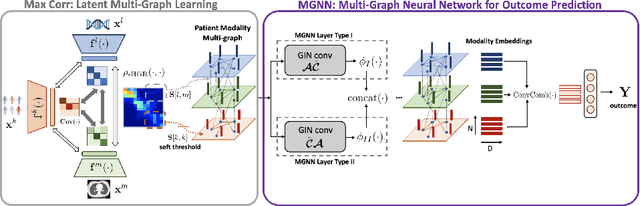
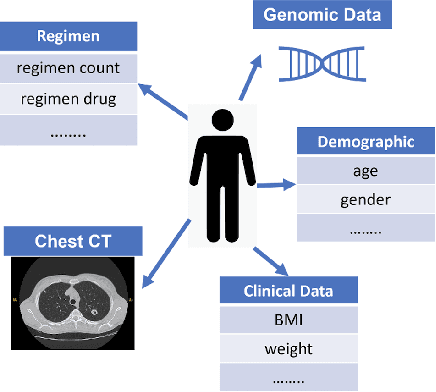
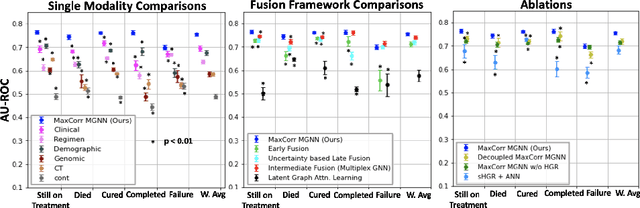
With the emergence of multimodal electronic health records, the evidence for an outcome may be captured across multiple modalities ranging from clinical to imaging and genomic data. Predicting outcomes effectively requires fusion frameworks capable of modeling fine-grained and multi-faceted complex interactions between modality features within and across patients. We develop an innovative fusion approach called MaxCorr MGNN that models non-linear modality correlations within and across patients through Hirschfeld-Gebelein-Renyi maximal correlation (MaxCorr) embeddings, resulting in a multi-layered graph that preserves the identities of the modalities and patients. We then design, for the first time, a generalized multi-layered graph neural network (MGNN) for task-informed reasoning in multi-layered graphs, that learns the parameters defining patient-modality graph connectivity and message passing in an end-to-end fashion. We evaluate our model an outcome prediction task on a Tuberculosis (TB) dataset consistently outperforming several state-of-the-art neural, graph-based and traditional fusion techniques.
Fusing Modalities by Multiplexed Graph Neural Networks for Outcome Prediction in Tuberculosis
Oct 25, 2022In a complex disease such as tuberculosis, the evidence for the disease and its evolution may be present in multiple modalities such as clinical, genomic, or imaging data. Effective patient-tailored outcome prediction and therapeutic guidance will require fusing evidence from these modalities. Such multimodal fusion is difficult since the evidence for the disease may not be uniform across all modalities, not all modality features may be relevant, or not all modalities may be present for all patients. All these nuances make simple methods of early, late, or intermediate fusion of features inadequate for outcome prediction. In this paper, we present a novel fusion framework using multiplexed graphs and derive a new graph neural network for learning from such graphs. Specifically, the framework allows modalities to be represented through their targeted encodings, and models their relationship explicitly via multiplexed graphs derived from salient features in a combined latent space. We present results that show that our proposed method outperforms state-of-the-art methods of fusing modalities for multi-outcome prediction on a large Tuberculosis (TB) dataset.
Extracting and Learning Fine-Grained Labels from Chest Radiographs
Nov 18, 2020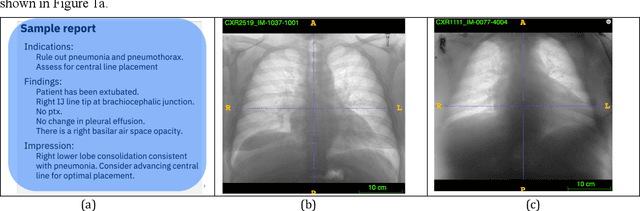



Chest radiographs are the most common diagnostic exam in emergency rooms and intensive care units today. Recently, a number of researchers have begun working on large chest X-ray datasets to develop deep learning models for recognition of a handful of coarse finding classes such as opacities, masses and nodules. In this paper, we focus on extracting and learning fine-grained labels for chest X-ray images. Specifically we develop a new method of extracting fine-grained labels from radiology reports by combining vocabulary-driven concept extraction with phrasal grouping in dependency parse trees for association of modifiers with findings. A total of 457 fine-grained labels depicting the largest spectrum of findings to date were selected and sufficiently large datasets acquired to train a new deep learning model designed for fine-grained classification. We show results that indicate a highly accurate label extraction process and a reliable learning of fine-grained labels. The resulting network, to our knowledge, is the first to recognize fine-grained descriptions of findings in images covering over nine modifiers including laterality, location, severity, size and appearance.
Chest X-ray Report Generation through Fine-Grained Label Learning
Jul 27, 2020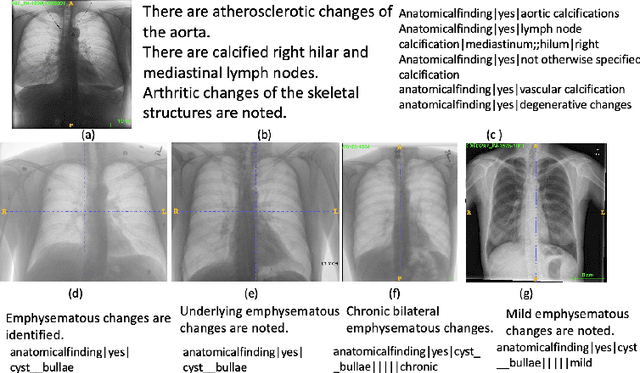


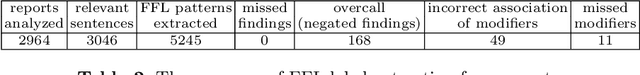
Obtaining automated preliminary read reports for common exams such as chest X-rays will expedite clinical workflows and improve operational efficiencies in hospitals. However, the quality of reports generated by current automated approaches is not yet clinically acceptable as they cannot ensure the correct detection of a broad spectrum of radiographic findings nor describe them accurately in terms of laterality, anatomical location, severity, etc. In this work, we present a domain-aware automatic chest X-ray radiology report generation algorithm that learns fine-grained description of findings from images and uses their pattern of occurrences to retrieve and customize similar reports from a large report database. We also develop an automatic labeling algorithm for assigning such descriptors to images and build a novel deep learning network that recognizes both coarse and fine-grained descriptions of findings. The resulting report generation algorithm significantly outperforms the state of the art using established score metrics.