 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking in the Right place for Anomalies: Explainable AI through Automatic Location Learning
Aug 02, 2020
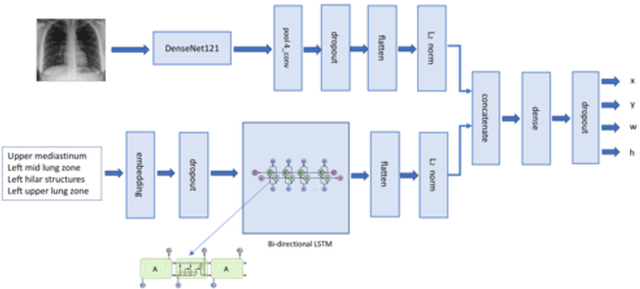
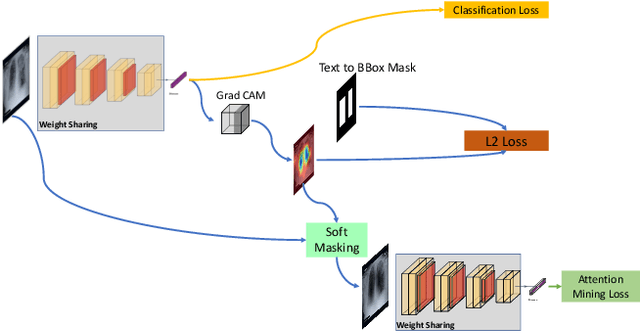

Deep learning has now become the de facto approach to the recognition of anomalies in medical imaging. Their 'black box' way of classifying medical images into anomaly labels poses problems for their acceptance, particularly with clinicians. Current explainable AI methods offer justifications through visualizations such as heat maps but cannot guarantee that the network is focusing on the relevant image region fully containing the anomaly. In this paper, we develop an approach to explainable AI in which the anomaly is assured to be overlapping the expected location when present. This is made possible by automatically extracting location-specific labels from textual reports and learning the association of expected locations to labels using a hybrid combination of Bi-Directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM) and DenseNet-121. Use of this expected location to bias the subsequent attention-guided inference network based on ResNet101 results in the isolation of the anomaly at the expected location when present. The method is evaluated on a large chest X-ray dataset.
* 5 pages, Paper presented as a poster at the International Symposium on Biomedical Imaging, 2020, Paper Number 655
Chest X-ray Report Generation through Fine-Grained Label Learning
Jul 27, 2020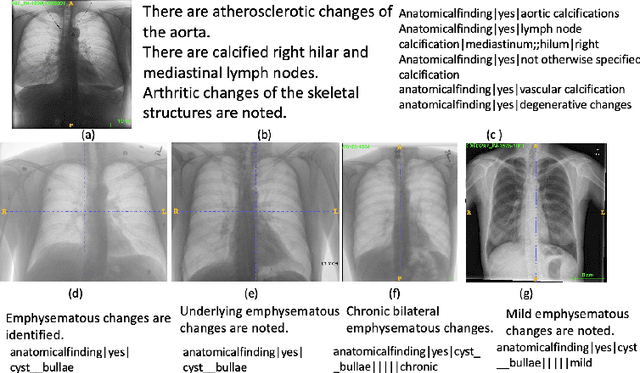


Obtaining automated preliminary read reports for common exams such as chest X-rays will expedite clinical workflows and improve operational efficiencies in hospitals. However, the quality of reports generated by current automated approaches is not yet clinically acceptable as they cannot ensure the correct detection of a broad spectrum of radiographic findings nor describe them accurately in terms of laterality, anatomical location, severity, etc. In this work, we present a domain-aware automatic chest X-ray radiology report generation algorithm that learns fine-grained description of findings from images and uses their pattern of occurrences to retrieve and customize similar reports from a large report database. We also develop an automatic labeling algorithm for assigning such descriptors to images and build a novel deep learning network that recognizes both coarse and fine-grained descriptions of findings. The resulting report generation algorithm significantly outperforms the state of the art using established score metrics.
Building a Benchmark Dataset and Classifiers for Sentence-Level Findings in AP Chest X-rays
Jun 21, 2019
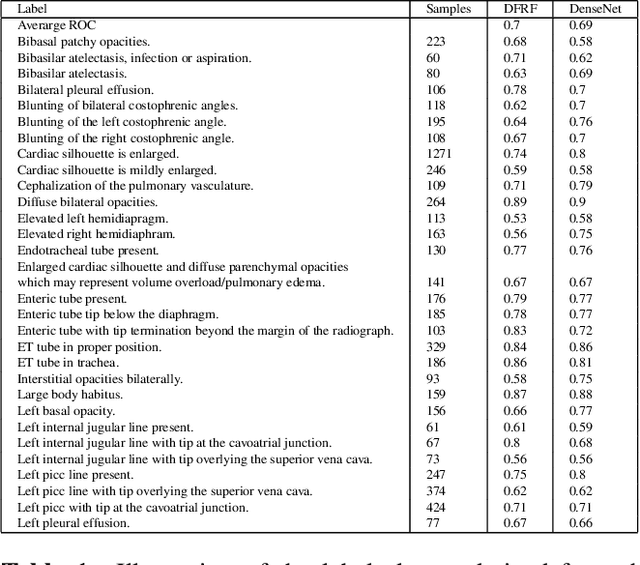
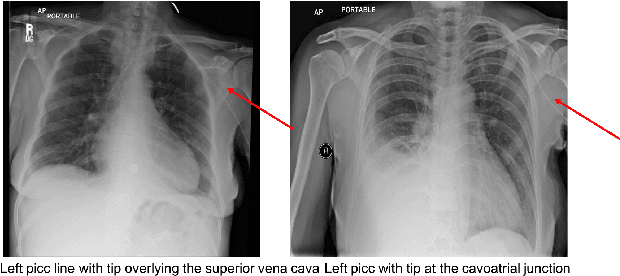
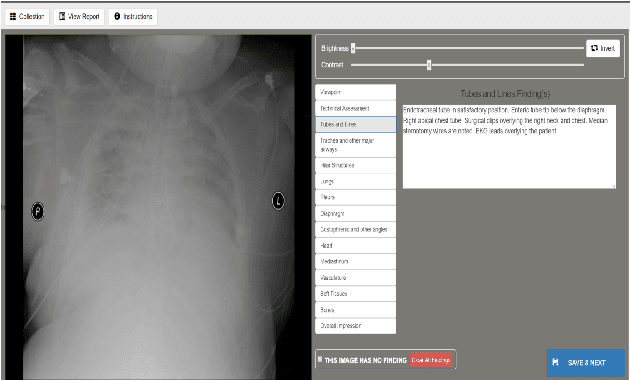
Chest X-rays are the most common diagnostic exams in emergency rooms and hospitals. There has been a surge of work on automatic interpretation of chest X-rays using deep learning approaches after the availability of large open source chest X-ray dataset from NIH. However, the labels are not sufficiently rich and descriptive for training classification tools. Further, it does not adequately address the findings seen in Chest X-rays taken in anterior-posterior (AP) view which also depict the placement of devices such as central vascular lines and tubes. In this paper, we present a new chest X-ray benchmark database of 73 rich sentence-level descriptors of findings seen in AP chest X-rays. We describe our method of obtaining these findings through a semi-automated ground truth generation process from crowdsourcing of clinician annotations. We also present results of building classifiers for these findings that show that such higher granularity labels can also be learned through the framework of deep learning classifiers.
Bimodal network architectures for automatic generation of image annotation from text
Sep 05, 2018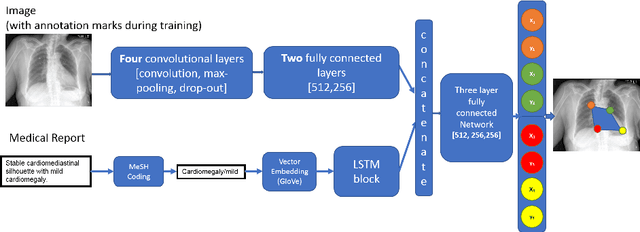

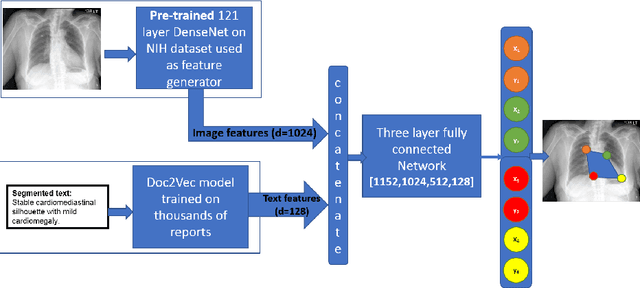
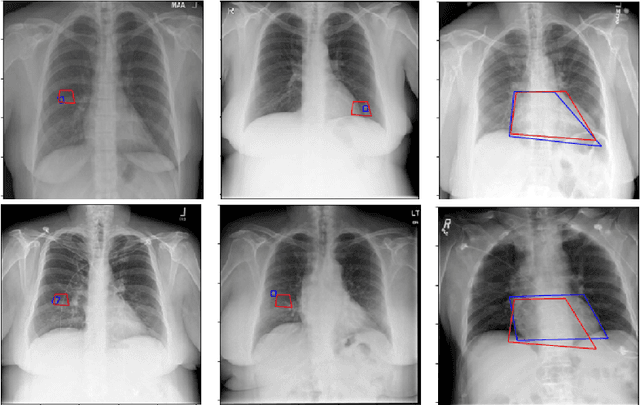
Medical image analysis practitioners have embraced big data methodologies. This has created a need for large annotated datasets. The source of big data is typically large image collections and clinical reports recorded for these images. In many cases, however, building algorithms aimed at segmentation and detection of disease requires a training dataset with markings of the areas of interest on the image that match with the described anomalies. This process of annotation is expensive and needs the involvement of clinicians. In this work we propose two separate deep neural network architectures for automatic marking of a region of interest (ROI) on the image best representing a finding location, given a textual report or a set of keywords. One architecture consists of LSTM and CNN components and is trained end to end with images, matching text, and markings of ROIs for those images. The output layer estimates the coordinates of the vertices of a polygonal region. The second architecture uses a network pre-trained on a large dataset of the same image types for learning feature representations of the findings of interest. We show that for a variety of findings from chest X-ray images, both proposed architectures learn to estimate the ROI, as validated by clinical annotations. There is a clear advantage obtained from the architecture with pre-trained imaging network. The centroids of the ROIs marked by this network were on average at a distance equivalent to 5.1% of the image width from the centroids of the ground truth ROIs.
* Accepted to MICCAI 2018, LNCS 11070