 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Prediction of Outcome in Treatment of Cerebral Aneurysms
Nov 18, 2022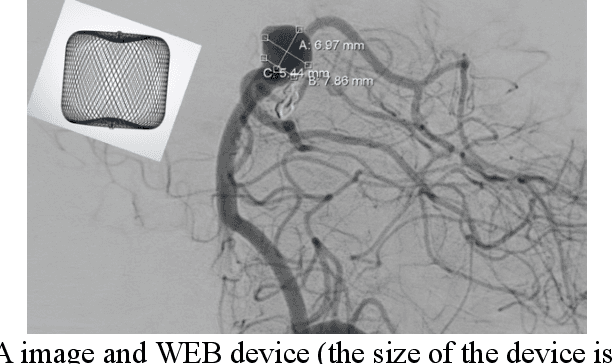
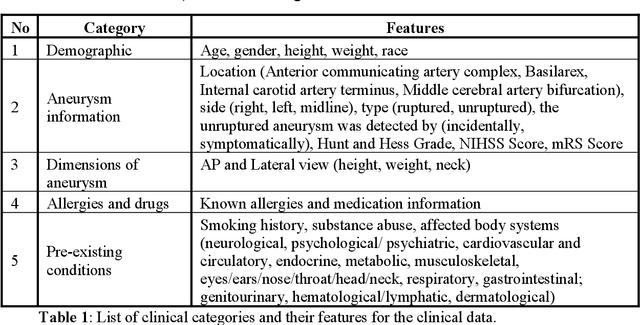
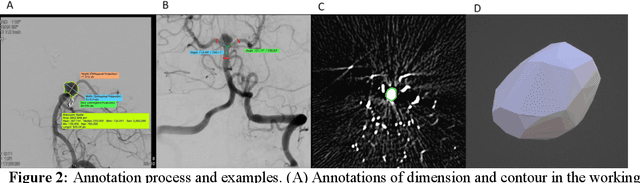
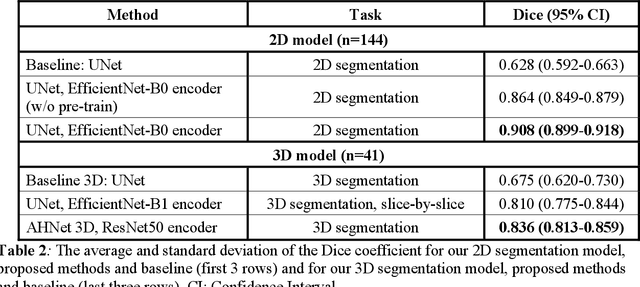
Intrasaccular flow disruptors treat cerebral aneurysms by diverting the blood flow from the aneurysm sac. Residual flow into the sac after the intervention is a failure that could be due to the use of an undersized device, or to vascular anatomy and clinical condition of the patient. We report a machine learning model based on over 100 clinical and imaging features that predict the outcome of wide-neck bifurcation aneurysm treatment with an intravascular embolization device. We combine clinical features with a diverse set of common and novel imaging measurements within a random forest model. We also develop neural network segmentation algorithms in 2D and 3D to contour the sac in angiographic images and automatically calculate the imaging features. These deliver 90% overlap with manual contouring in 2D and 83% in 3D. Our predictive model classifies complete vs. partial occlusion outcomes with an accuracy of 75.31%, and weighted F1-score of 0.74.
* 10 pages
CheXRelNet: An Anatomy-Aware Model for Tracking Longitudinal Relationships between Chest X-Rays
Aug 08, 2022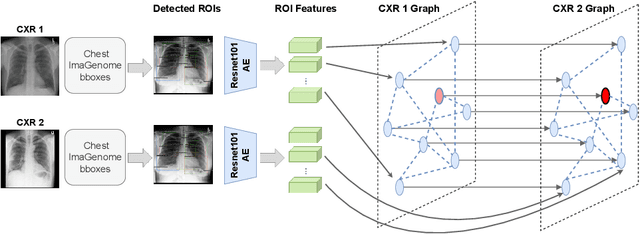
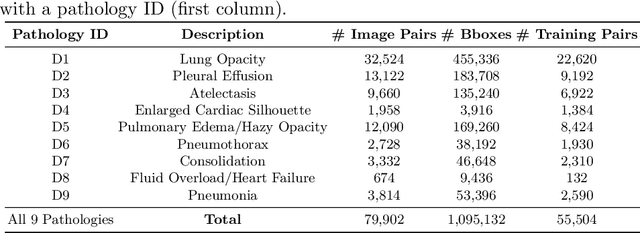
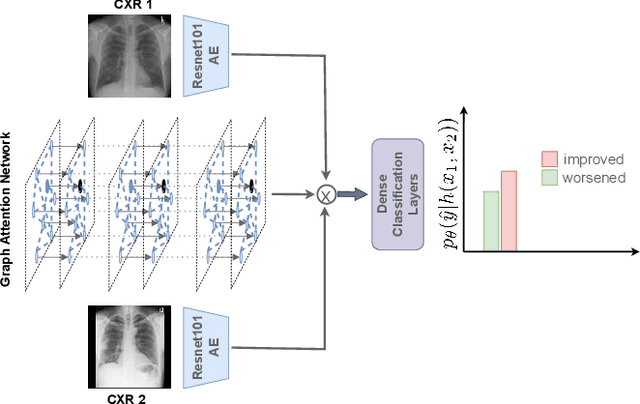
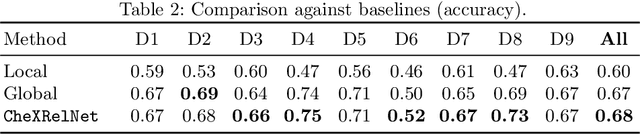
Despite the progress in utilizing deep learning to automate chest radiograph interpretation and disease diagnosis tasks, change between sequential Chest X-rays (CXRs) has received limited attention. Monitoring the progression of pathologies that are visualized through chest imaging poses several challenges in anatomical motion estimation and image registration, i.e., spatially aligning the two images and modeling temporal dynamics in change detection. In this work, we propose CheXRelNet, a neural model that can track longitudinal pathology change relations between two CXRs. CheXRelNet incorporates local and global visual features, utilizes inter-image and intra-image anatomical information, and learns dependencies between anatomical region attributes, to accurately predict disease change for a pair of CXRs. Experimental results on the Chest ImaGenome dataset show increased downstream performance compared to baselines. Code is available at https://github.com/PLAN-Lab/ChexRelNet
3D Segmentation with Fully Trainable Gabor Kernels and Pearson's Correlation Coefficient
Jan 10, 2022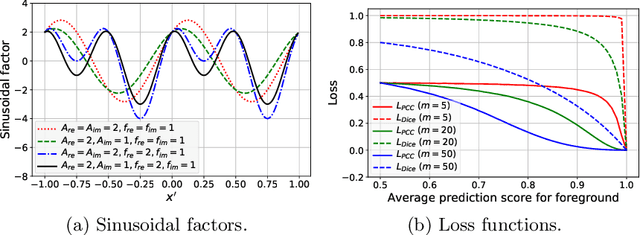
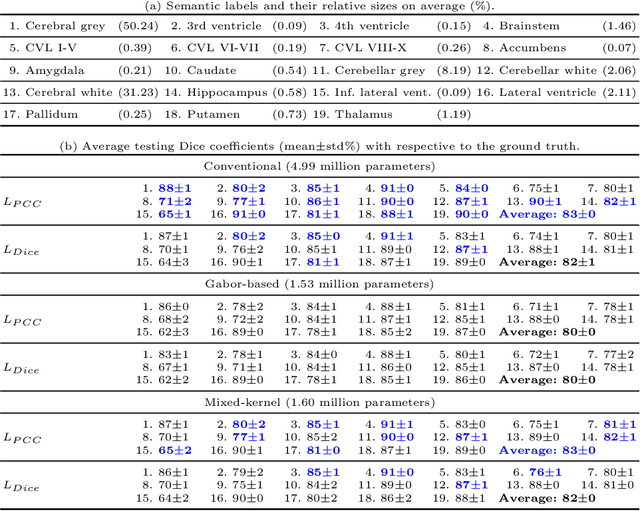
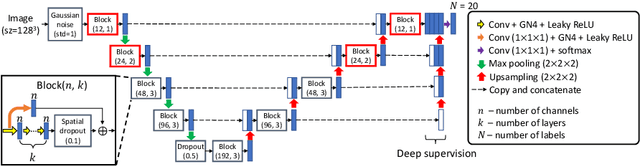

The convolutional layer and loss function are two fundamental components in deep learning. Because of the success of conventional deep learning kernels, the less versatile Gabor kernels become less popular despite the fact that they can provide abundant features at different frequencies, orientations, and scales with much fewer parameters. For existing loss functions for multi-class image segmentation, there is usually a tradeoff among accuracy, robustness to hyperparameters, and manual weight selections for combining different losses. Therefore, to gain the benefits of using Gabor kernels while keeping the advantage of automatic feature generation in deep learning, we propose a fully trainable Gabor-based convolutional layer where all Gabor parameters are trainable through backpropagation. Furthermore, we propose a loss function based on the Pearson's correlation coefficient, which is accurate, robust to learning rates, and does not require manual weight selections. Experiments on 43 3D brain magnetic resonance images with 19 anatomical structures show that, using the proposed loss function with a proper combination of conventional and Gabor-based kernels, we can train a network with only 1.6 million parameters to achieve an average Dice coefficient of 83%. This size is 44 times smaller than the V-Net which has 71 million parameters. This paper demonstrates the potentials of using learnable parametric kernels in deep learning for 3D segmentation.
Basis Scaling and Double Pruning for Efficient Transfer Learning
Aug 06, 2021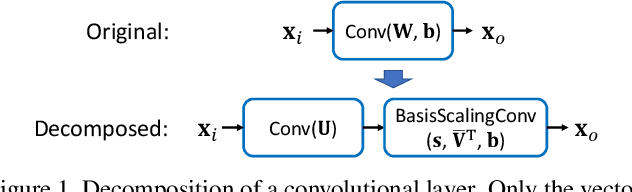
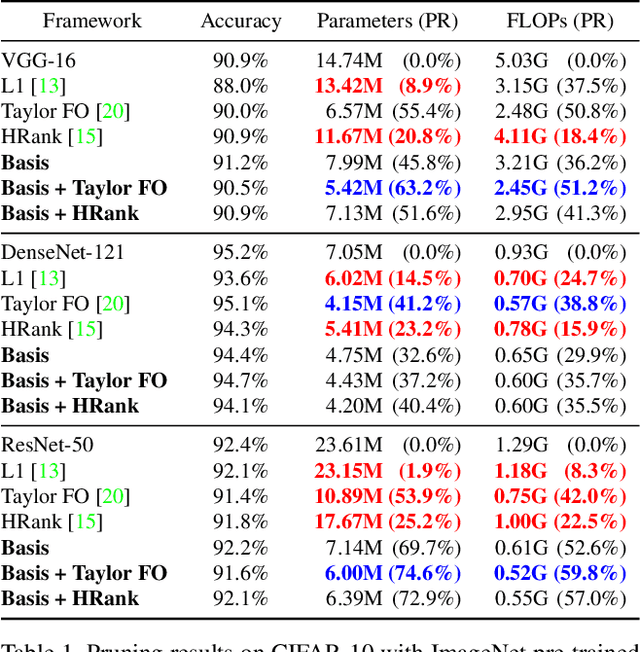
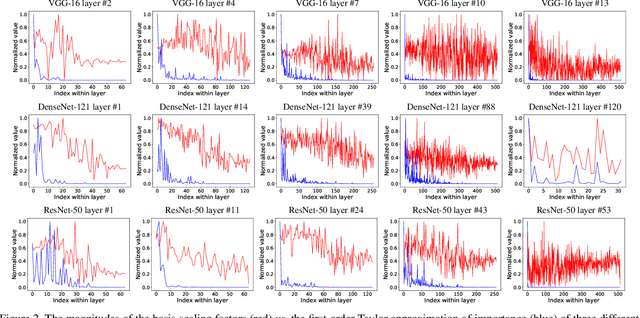
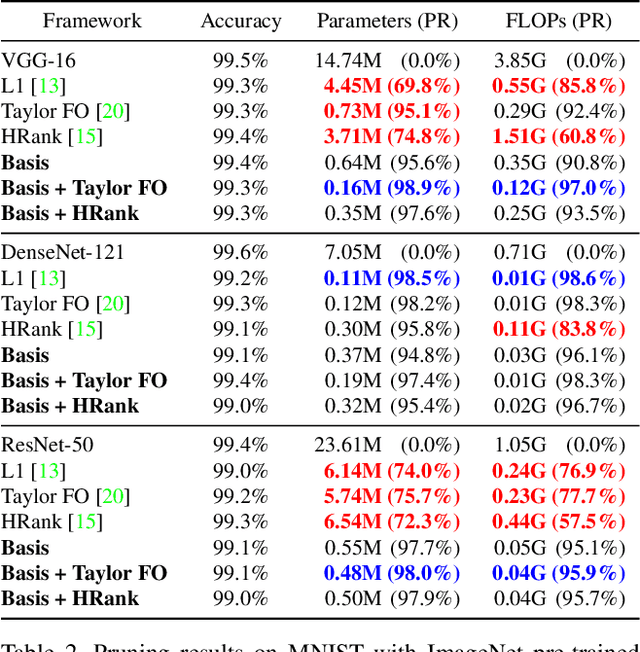
Transfer learning allows the reuse of deep learning features on new datasets with limited data. However, the resulting models could be unnecessarily large and thus inefficient. Although network pruning can be applied to improve inference efficiency, existing algorithms usually require fine-tuning and may not be suitable for small datasets. In this paper, we propose an algorithm that transforms the convolutional weights into the subspaces of orthonormal bases where a model is pruned. Using singular value decomposition, we decompose a convolutional layer into two layers: a convolutional layer with the orthonormal basis vectors as the filters, and a layer that we name "BasisScalingConv", which is responsible for rescaling the features and transforming them back to the original space. As the filters in each transformed layer are linearly independent with known relative importance, pruning can be more effective and stable, and fine tuning individual weights is unnecessary. Furthermore, as the numbers of input and output channels of the original convolutional layer remain unchanged, basis pruning is applicable to virtually all network architectures. Basis pruning can also be combined with existing pruning algorithms for double pruning to further increase the pruning capability. With less than 1% reduction in the classification accuracy, we can achieve pruning ratios up to 98.9% in parameters and 98.6% in FLOPs.
Chest ImaGenome Dataset for Clinical Reasoning
Jul 31, 2021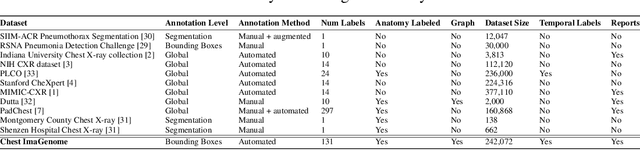
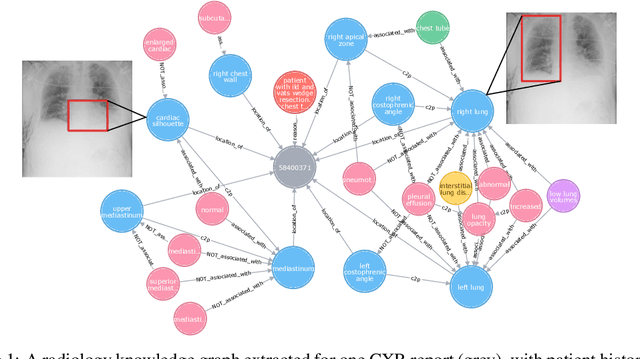
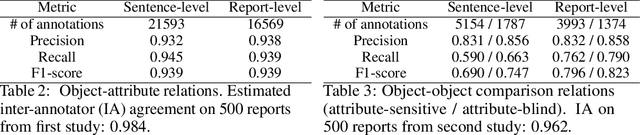

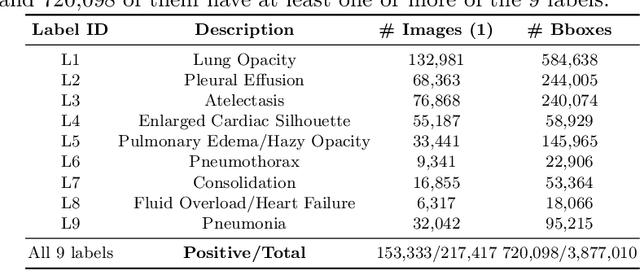
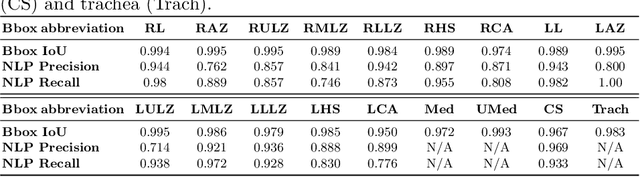
Despite the progress in automatic detection of radiologic findings from chest X-ray (CXR) images in recent years, a quantitative evaluation of the explainability of these models is hampered by the lack of locally labeled datasets for different findings. With the exception of a few expert-labeled small-scale datasets for specific findings, such as pneumonia and pneumothorax, most of the CXR deep learning models to date are trained on global "weak" labels extracted from text reports, or trained via a joint image and unstructured text learning strategy. Inspired by the Visual Genome effort in the computer vision community, we constructed the first Chest ImaGenome dataset with a scene graph data structure to describe $242,072$ images. Local annotations are automatically produced using a joint rule-based natural language processing (NLP) and atlas-based bounding box detection pipeline. Through a radiologist constructed CXR ontology, the annotations for each CXR are connected as an anatomy-centered scene graph, useful for image-level reasoning and multimodal fusion applications. Overall, we provide: i) $1,256$ combinations of relation annotations between $29$ CXR anatomical locations (objects with bounding box coordinates) and their attributes, structured as a scene graph per image, ii) over $670,000$ localized comparison relations (for improved, worsened, or no change) between the anatomical locations across sequential exams, as well as ii) a manually annotated gold standard scene graph dataset from $500$ unique patients.
AnaXNet: Anatomy Aware Multi-label Finding Classification in Chest X-ray
May 20, 2021
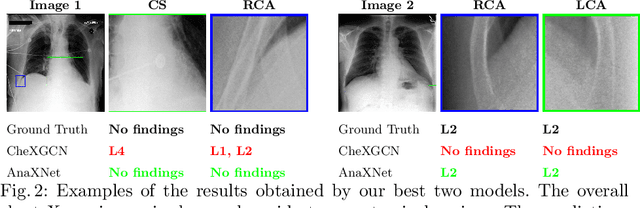
Radiologists usually observe anatomical regions of chest X-ray images as well as the overall image before making a decision. However, most existing deep learning models only look at the entire X-ray image for classification, failing to utilize important anatomical information. In this paper, we propose a novel multi-label chest X-ray classification model that accurately classifies the image finding and also localizes the findings to their correct anatomical regions. Specifically, our model consists of two modules, the detection module and the anatomical dependency module. The latter utilizes graph convolutional networks, which enable our model to learn not only the label dependency but also the relationship between the anatomical regions in the chest X-ray. We further utilize a method to efficiently create an adjacency matrix for the anatomical regions using the correlation of the label across the different regions. Detailed experiments and analysis of our results show the effectiveness of our method when compared to the current state-of-the-art multi-label chest X-ray image classification methods while also providing accurate location information.
Channel Scaling: A Scale-and-Select Approach for Transfer Learning
Mar 22, 2021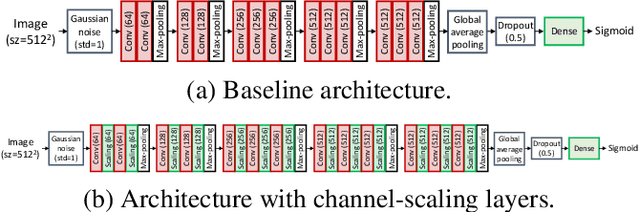
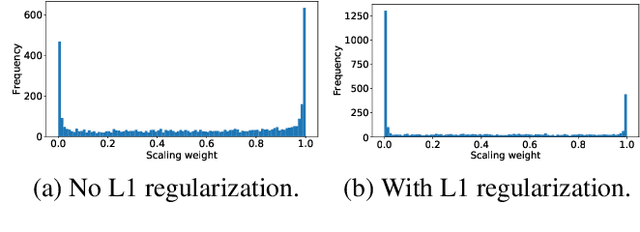
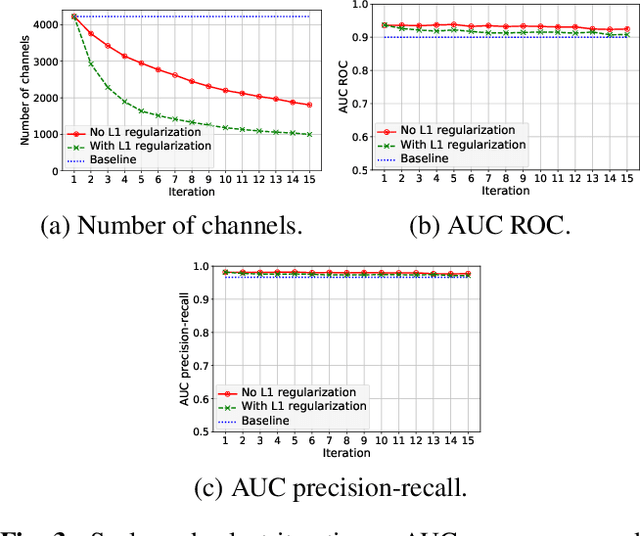
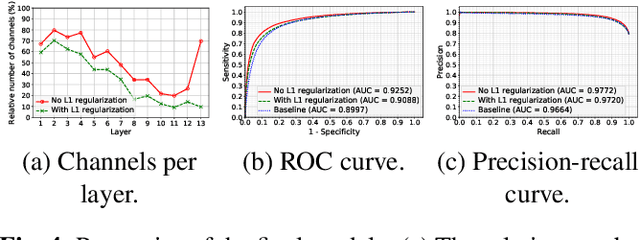
Transfer learning with pre-trained neural networks is a common strategy for training classifiers in medical image analysis. Without proper channel selections, this often results in unnecessarily large models that hinder deployment and explainability. In this paper, we propose a novel approach to efficiently build small and well performing networks by introducing the channel-scaling layers. A channel-scaling layer is attached to each frozen convolutional layer, with the trainable scaling weights inferring the importance of the corresponding feature channels. Unlike the fine-tuning approaches, we maintain the weights of the original channels and large datasets are not required. By imposing L1 regularization and thresholding on the scaling weights, this framework iteratively removes unnecessary feature channels from a pre-trained model. Using an ImageNet pre-trained VGG16 model, we demonstrate the capabilities of the proposed framework on classifying opacity from chest X-ray images. The results show that we can reduce the number of parameters by 95% while delivering a superior performance.
Statistical learning and cross-validation for point processes
Mar 01, 2021
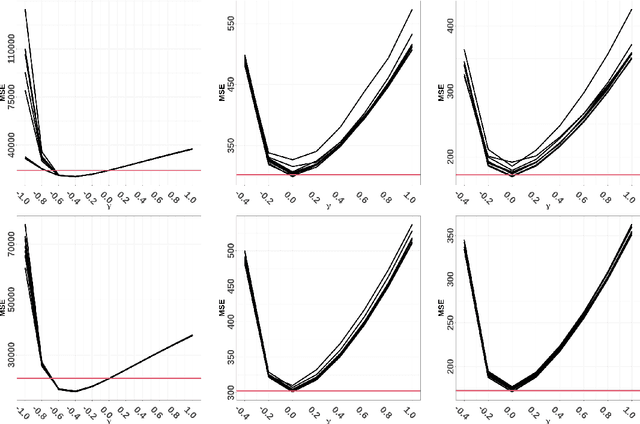

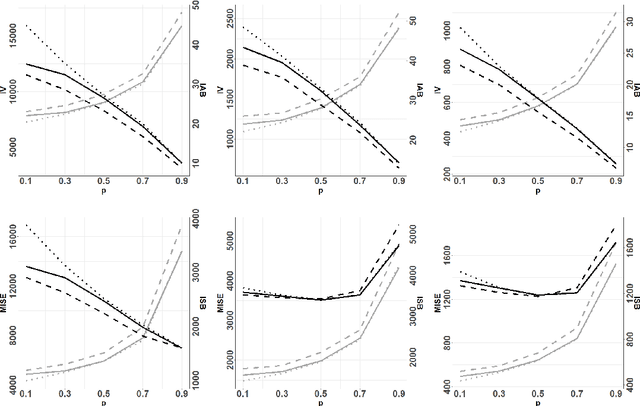
This paper presents the first general (supervised) statistical learning framework for point processes in general spaces. Our approach is based on the combination of two new concepts, which we define in the paper: i) bivariate innovations, which are measures of discrepancy/prediction-accuracy between two point processes, and ii) point process cross-validation (CV), which we here define through point process thinning. The general idea is to carry out the fitting by predicting CV-generated validation sets using the corresponding training sets; the prediction error, which we minimise, is measured by means of bivariate innovations. Having established various theoretical properties of our bivariate innovations, we study in detail the case where the CV procedure is obtained through independent thinning and we apply our statistical learning methodology to three typical spatial statistical settings, namely parametric intensity estimation, non-parametric intensity estimation and Papangelou conditional intensity fitting. Aside from deriving theoretical properties related to these cases, in each of them we numerically show that our statistical learning approach outperforms the state of the art in terms of mean (integrated) squared error.
Creation and Validation of a Chest X-Ray Dataset with Eye-tracking and Report Dictation for AI Development
Oct 08, 2020
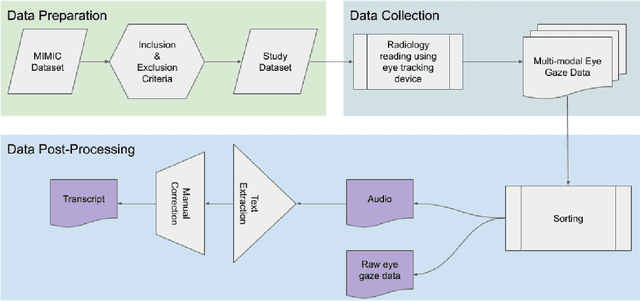
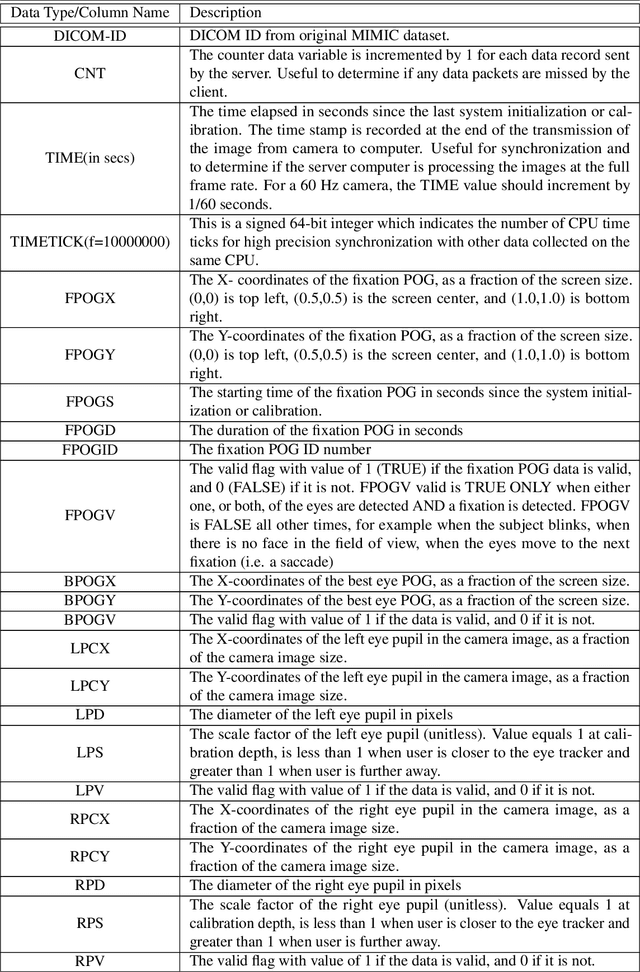
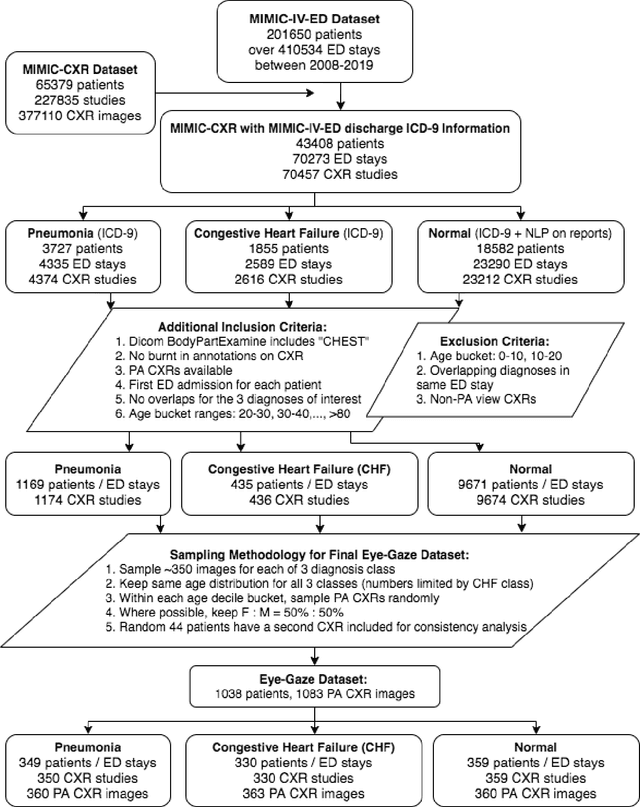
We developed a rich dataset of Chest X-Ray (CXR) images to assist investigators in artificial intelligence. The data were collected using an eye tracking system while a radiologist reviewed and reported on 1,083 CXR images. The dataset contains the following aligned data: CXR image, transcribed radiology report text, radiologist's dictation audio and eye gaze coordinates data. We hope this dataset can contribute to various areas of research particularly towards explainable and multimodal deep learning / machine learning methods. Furthermore, investigators in disease classification and localization, automated radiology report generation, and human-machine interaction can benefit from these data. We report deep learning experiments that utilize the attention maps produced by eye gaze dataset to show the potential utility of this data.
Learning Invariant Feature Representation to Improve Generalization across Chest X-ray Datasets
Aug 04, 2020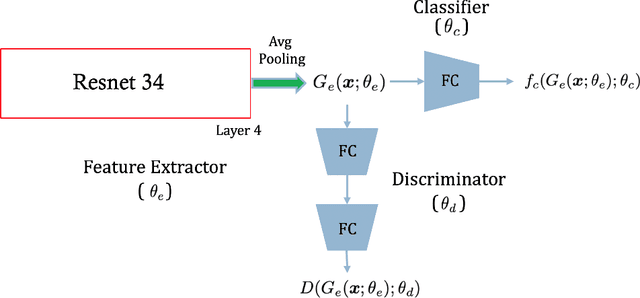
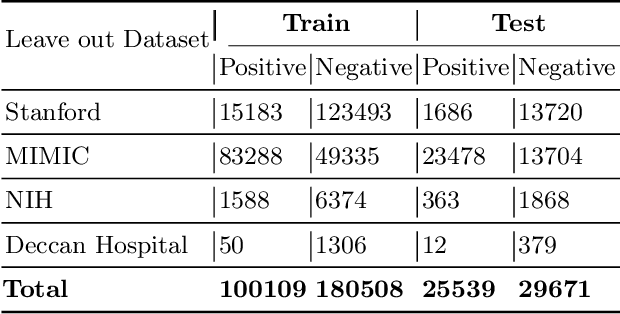

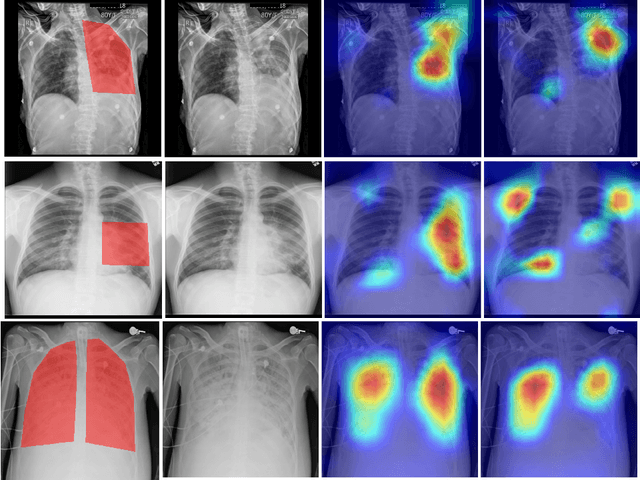
Chest radiography is the most common medical image examination for screening and diagnosis in hospitals. Automatic interpretation of chest X-rays at the level of an entry-level radiologist can greatly benefit work prioritization and assist in analyzing a larger population. Subsequently, several datasets and deep learning-based solutions have been proposed to identify diseases based on chest X-ray images. However, these methods are shown to be vulnerable to shift in the source of data: a deep learning model performing well when tested on the same dataset as training data, starts to perform poorly when it is tested on a dataset from a different source. In this work, we address this challenge of generalization to a new source by forcing the network to learn a source-invariant representation. By employing an adversarial training strategy, we show that a network can be forced to learn a source-invariant representation. Through pneumonia-classification experiments on multi-source chest X-ray datasets, we show that this algorithm helps in improving classification accuracy on a new source of X-ray dataset.