 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Control Center for Data Product Optimization
Mar 10, 2026Data products enable end users to gain greater insights about their data by providing supporting assets, such as example question-SQL pairs which can be answered using the data or views over the database tables. However, producing useful data products is challenging, and typically requires domain experts to hand-craft supporting assets. We propose a system that automates data product improvement through specialized AI agents operating in a continuous optimization loop. By surfacing questions, monitoring multi-dimensional quality metrics, and supporting human-in-the-loop controls, it transforms data into observable and refinable assets that balance automation with trust and oversight.
Modern Hopfield Networks meet Encoded Neural Representations -- Addressing Practical Considerations
Sep 24, 2024
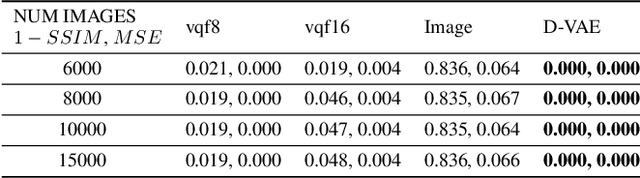
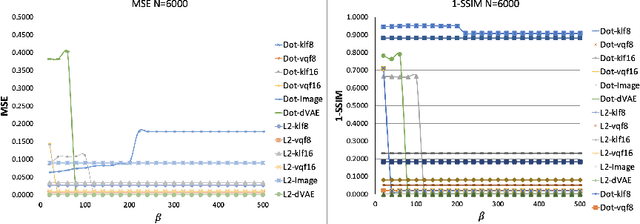
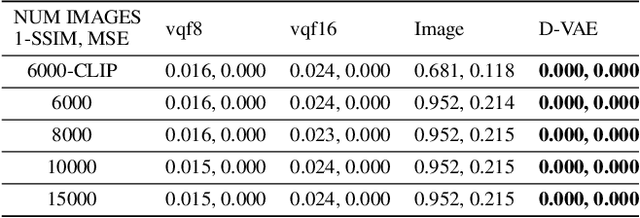
Content-addressable memories such as Modern Hopfield Networks (MHN) have been studied as mathematical models of auto-association and storage/retrieval in the human declarative memory, yet their practical use for large-scale content storage faces challenges. Chief among them is the occurrence of meta-stable states, particularly when handling large amounts of high dimensional content. This paper introduces Hopfield Encoding Networks (HEN), a framework that integrates encoded neural representations into MHNs to improve pattern separability and reduce meta-stable states. We show that HEN can also be used for retrieval in the context of hetero association of images with natural language queries, thus removing the limitation of requiring access to partial content in the same domain. Experimental results demonstrate substantial reduction in meta-stable states and increased storage capacity while still enabling perfect recall of a significantly larger number of inputs advancing the practical utility of associative memory networks for real-world tasks.
Image-Based Soil Organic Carbon Remote Sensing from Satellite Images with Fourier Neural Operator and Structural Similarity
Nov 21, 2023

Soil organic carbon (SOC) sequestration is the transfer and storage of atmospheric carbon dioxide in soils, which plays an important role in climate change mitigation. SOC concentration can be improved by proper land use, thus it is beneficial if SOC can be estimated at a regional or global scale. As multispectral satellite data can provide SOC-related information such as vegetation and soil properties at a global scale, estimation of SOC through satellite data has been explored as an alternative to manual soil sampling. Although existing studies show promising results, they are mainly based on pixel-based approaches with traditional machine learning methods, and convolutional neural networks (CNNs) are uncommon. To study the use of CNNs on SOC remote sensing, here we propose the FNO-DenseNet based on the Fourier neural operator (FNO). By combining the advantages of the FNO and DenseNet, the FNO-DenseNet outperformed the FNO in our experiments with hundreds of times fewer parameters. The FNO-DenseNet also outperformed a pixel-based random forest by 18% in the mean absolute percentage error.
HartleyMHA: Self-Attention in Frequency Domain for Resolution-Robust and Parameter-Efficient 3D Image Segmentation
Oct 05, 2023With the introduction of Transformers, different attention-based models have been proposed for image segmentation with promising results. Although self-attention allows capturing of long-range dependencies, it suffers from a quadratic complexity in the image size especially in 3D. To avoid the out-of-memory error during training, input size reduction is usually required for 3D segmentation, but the accuracy can be suboptimal when the trained models are applied on the original image size. To address this limitation, inspired by the Fourier neural operator (FNO), we introduce the HartleyMHA model which is robust to training image resolution with efficient self-attention. FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We modify the FNO by using the Hartley transform with shared parameters to reduce the model size by orders of magnitude, and this allows us to further apply self-attention in the frequency domain for more expressive high-order feature combination with improved efficiency. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
FNOSeg3D: Resolution-Robust 3D Image Segmentation with Fourier Neural Operator
Oct 05, 2023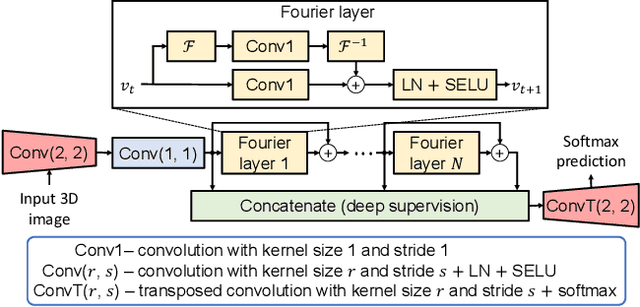
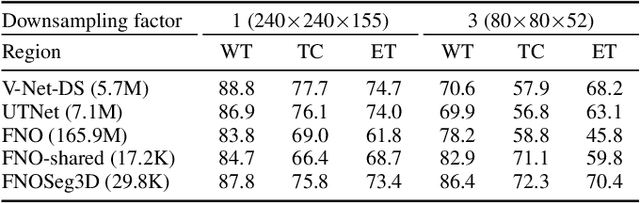
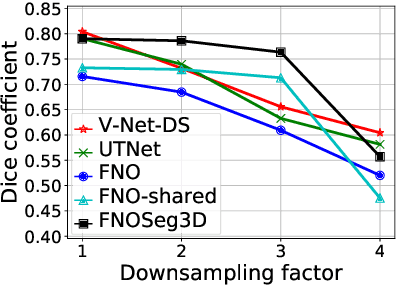

Due to the computational complexity of 3D medical image segmentation, training with downsampled images is a common remedy for out-of-memory errors in deep learning. Nevertheless, as standard spatial convolution is sensitive to variations in image resolution, the accuracy of a convolutional neural network trained with downsampled images can be suboptimal when applied on the original resolution. To address this limitation, we introduce FNOSeg3D, a 3D segmentation model robust to training image resolution based on the Fourier neural operator (FNO). The FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We improve the FNO by reducing its parameter requirement and enhancing its learning capability through residual connections and deep supervision, and these result in our FNOSeg3D model which is parameter efficient and resolution robust. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
3D Segmentation with Fully Trainable Gabor Kernels and Pearson's Correlation Coefficient
Jan 10, 2022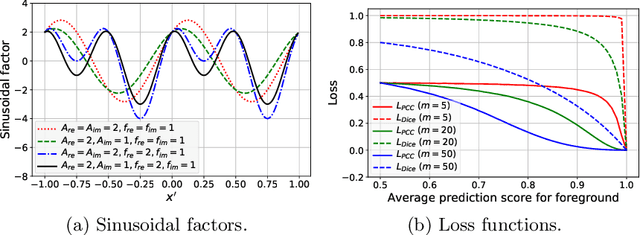
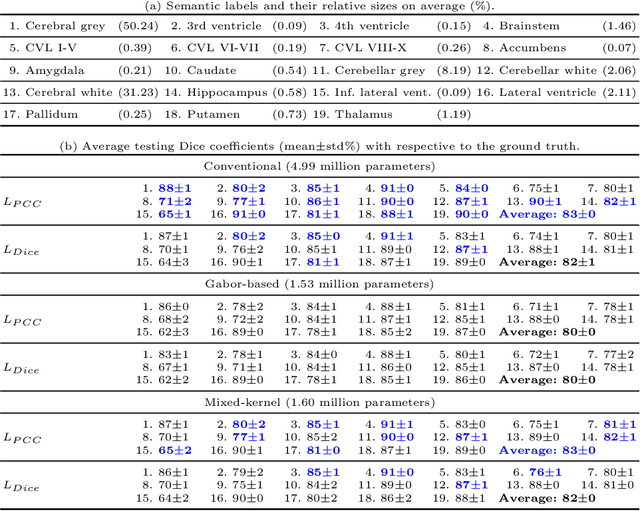
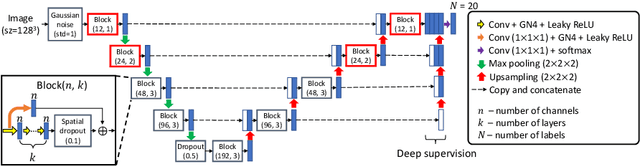

The convolutional layer and loss function are two fundamental components in deep learning. Because of the success of conventional deep learning kernels, the less versatile Gabor kernels become less popular despite the fact that they can provide abundant features at different frequencies, orientations, and scales with much fewer parameters. For existing loss functions for multi-class image segmentation, there is usually a tradeoff among accuracy, robustness to hyperparameters, and manual weight selections for combining different losses. Therefore, to gain the benefits of using Gabor kernels while keeping the advantage of automatic feature generation in deep learning, we propose a fully trainable Gabor-based convolutional layer where all Gabor parameters are trainable through backpropagation. Furthermore, we propose a loss function based on the Pearson's correlation coefficient, which is accurate, robust to learning rates, and does not require manual weight selections. Experiments on 43 3D brain magnetic resonance images with 19 anatomical structures show that, using the proposed loss function with a proper combination of conventional and Gabor-based kernels, we can train a network with only 1.6 million parameters to achieve an average Dice coefficient of 83%. This size is 44 times smaller than the V-Net which has 71 million parameters. This paper demonstrates the potentials of using learnable parametric kernels in deep learning for 3D segmentation.
Addressing Deep Learning Model Uncertainty in Long-Range Climate Forecasting with Late Fusion
Dec 10, 2021
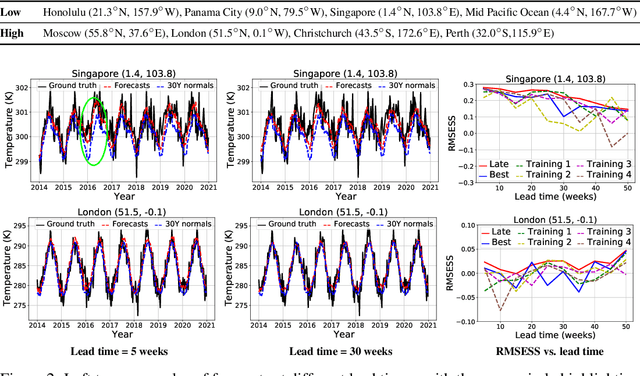
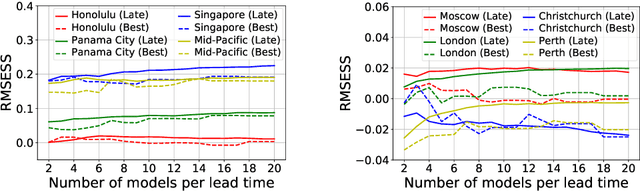
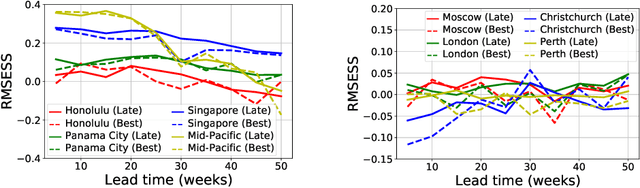
Global warming leads to the increase in frequency and intensity of climate extremes that cause tremendous loss of lives and property. Accurate long-range climate prediction allows more time for preparation and disaster risk management for such extreme events. Although machine learning approaches have shown promising results in long-range climate forecasting, the associated model uncertainties may reduce their reliability. To address this issue, we propose a late fusion approach that systematically combines the predictions from multiple models to reduce the expected errors of the fused results. We also propose a network architecture with the novel denormalization layer to gain the benefits of data normalization without actually normalizing the data. The experimental results on long-range 2m temperature forecasting show that the framework outperforms the 30-year climate normals, and the accuracy can be improved by increasing the number of models.
Basis Scaling and Double Pruning for Efficient Transfer Learning
Aug 06, 2021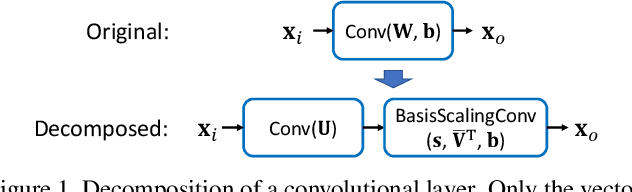
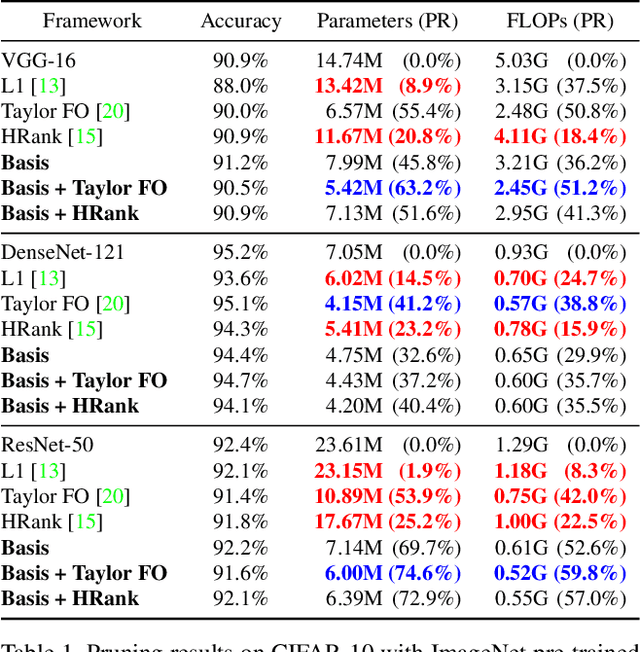
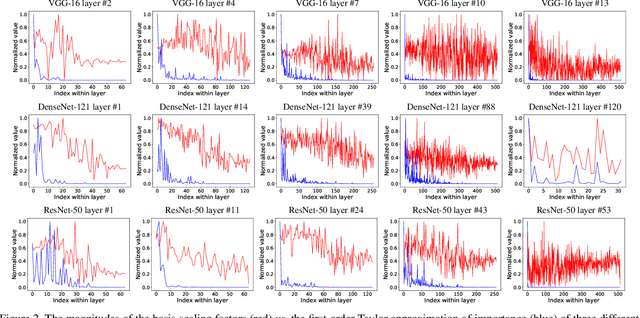
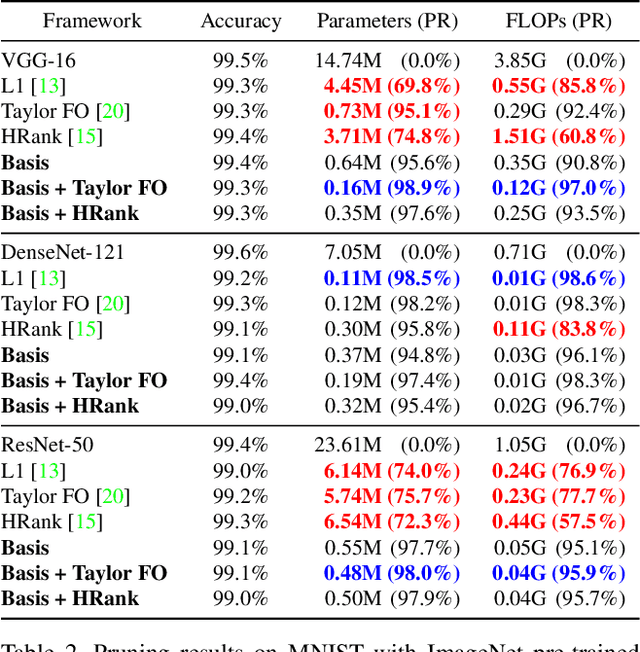
Transfer learning allows the reuse of deep learning features on new datasets with limited data. However, the resulting models could be unnecessarily large and thus inefficient. Although network pruning can be applied to improve inference efficiency, existing algorithms usually require fine-tuning and may not be suitable for small datasets. In this paper, we propose an algorithm that transforms the convolutional weights into the subspaces of orthonormal bases where a model is pruned. Using singular value decomposition, we decompose a convolutional layer into two layers: a convolutional layer with the orthonormal basis vectors as the filters, and a layer that we name "BasisScalingConv", which is responsible for rescaling the features and transforming them back to the original space. As the filters in each transformed layer are linearly independent with known relative importance, pruning can be more effective and stable, and fine tuning individual weights is unnecessary. Furthermore, as the numbers of input and output channels of the original convolutional layer remain unchanged, basis pruning is applicable to virtually all network architectures. Basis pruning can also be combined with existing pruning algorithms for double pruning to further increase the pruning capability. With less than 1% reduction in the classification accuracy, we can achieve pruning ratios up to 98.9% in parameters and 98.6% in FLOPs.
Multiview and Multiclass Image Segmentation using Deep Learning in Fetal Echocardiography
Mar 23, 2021Congenital heart disease (CHD) is the most common congenital abnormality associated with birth defects in the United States. Despite training efforts and substantial advancement in ultrasound technology over the past years, CHD remains an abnormality that is frequently missed during prenatal ultrasonography. Therefore, computer-aided detection of CHD can play a critical role in prenatal care by improving screening and diagnosis. Since many CHDs involve structural abnormalities, automatic segmentation of anatomical structures is an important step in the analysis of fetal echocardiograms. While existing methods mainly focus on the four-chamber view with a small number of structures, here we present a more comprehensive deep learning segmentation framework covering 14 anatomical structures in both three-vessel trachea and four-chamber views. Specifically, our framework enhances the V-Net with spatial dropout, group normalization, and deep supervision to train a segmentation model that can be applied on both views regardless of abnormalities. By identifying the pitfall of using the Dice loss when some labels are unavailable in some images, this framework integrates information from multiple views and is robust to missing structures due to anatomical anomalies, achieving an average Dice score of 79%.
Channel Scaling: A Scale-and-Select Approach for Transfer Learning
Mar 22, 2021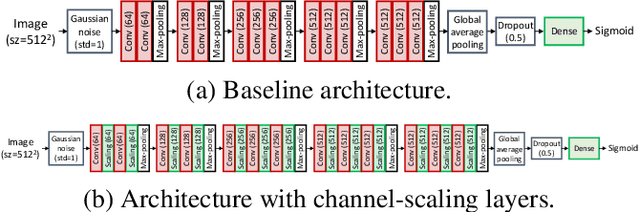
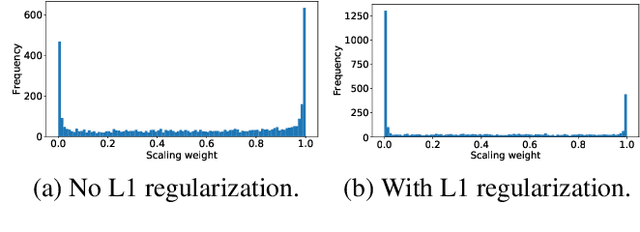
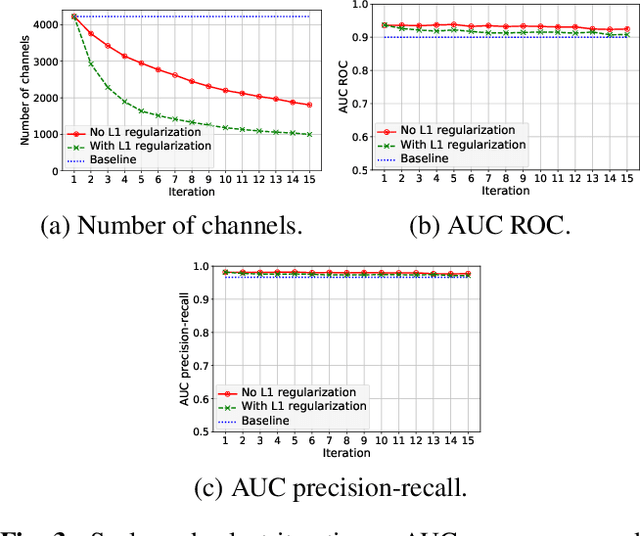
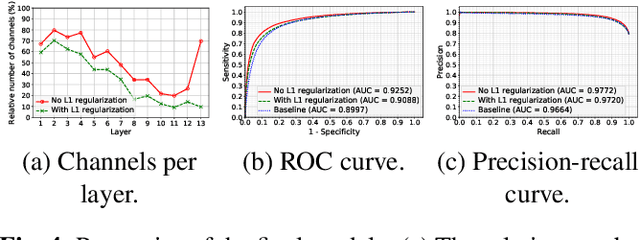
Transfer learning with pre-trained neural networks is a common strategy for training classifiers in medical image analysis. Without proper channel selections, this often results in unnecessarily large models that hinder deployment and explainability. In this paper, we propose a novel approach to efficiently build small and well performing networks by introducing the channel-scaling layers. A channel-scaling layer is attached to each frozen convolutional layer, with the trainable scaling weights inferring the importance of the corresponding feature channels. Unlike the fine-tuning approaches, we maintain the weights of the original channels and large datasets are not required. By imposing L1 regularization and thresholding on the scaling weights, this framework iteratively removes unnecessary feature channels from a pre-trained model. Using an ImageNet pre-trained VGG16 model, we demonstrate the capabilities of the proposed framework on classifying opacity from chest X-ray images. The results show that we can reduce the number of parameters by 95% while delivering a superior performance.