 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreation and Validation of a Chest X-Ray Dataset with Eye-tracking and Report Dictation for AI Development
Oct 08, 2020
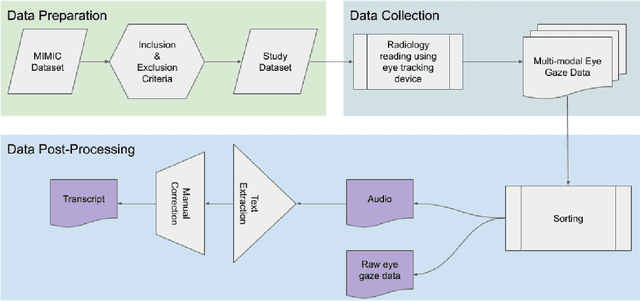
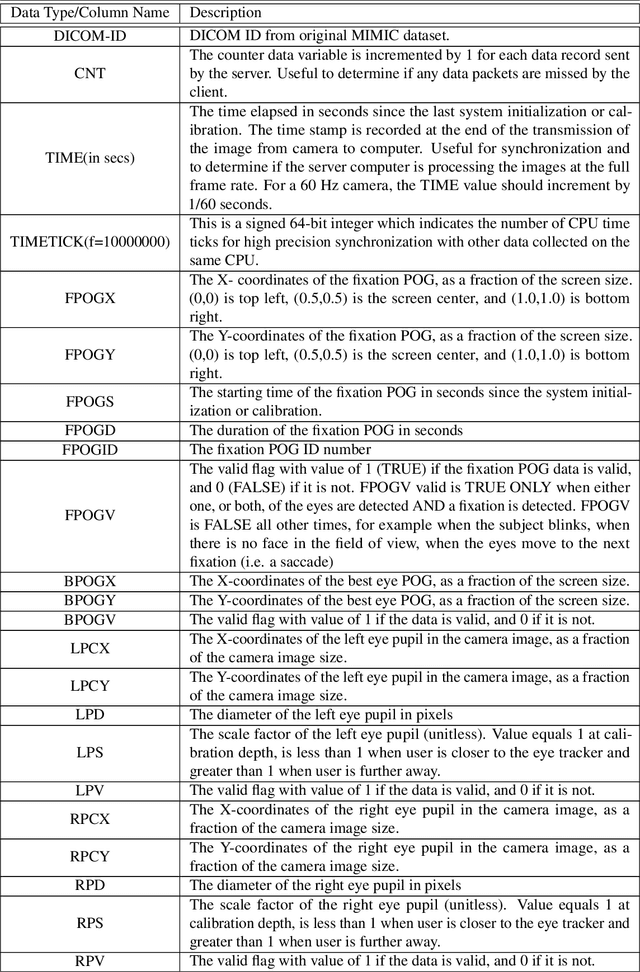
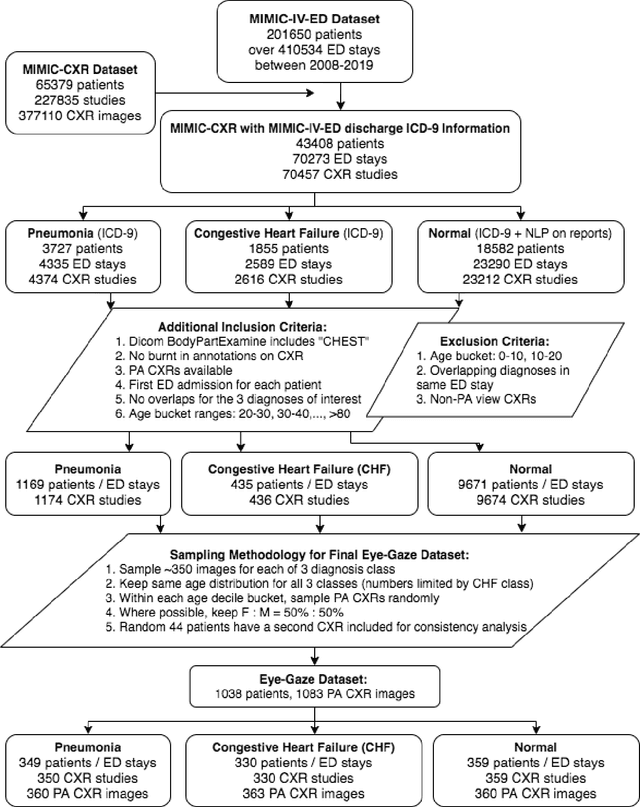
We developed a rich dataset of Chest X-Ray (CXR) images to assist investigators in artificial intelligence. The data were collected using an eye tracking system while a radiologist reviewed and reported on 1,083 CXR images. The dataset contains the following aligned data: CXR image, transcribed radiology report text, radiologist's dictation audio and eye gaze coordinates data. We hope this dataset can contribute to various areas of research particularly towards explainable and multimodal deep learning / machine learning methods. Furthermore, investigators in disease classification and localization, automated radiology report generation, and human-machine interaction can benefit from these data. We report deep learning experiments that utilize the attention maps produced by eye gaze dataset to show the potential utility of this data.
Looking in the Right place for Anomalies: Explainable AI through Automatic Location Learning
Aug 02, 2020
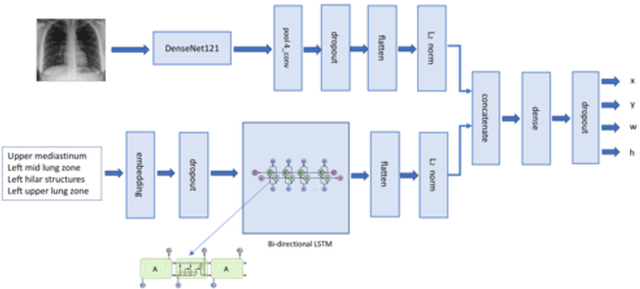
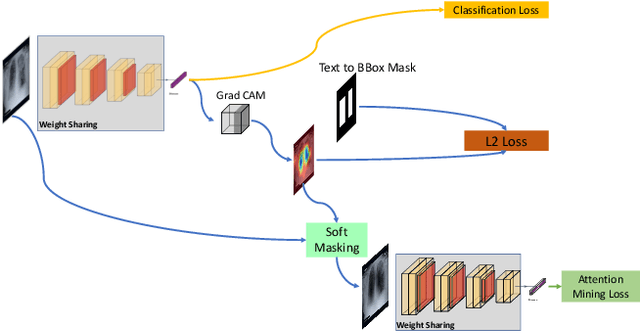

Deep learning has now become the de facto approach to the recognition of anomalies in medical imaging. Their 'black box' way of classifying medical images into anomaly labels poses problems for their acceptance, particularly with clinicians. Current explainable AI methods offer justifications through visualizations such as heat maps but cannot guarantee that the network is focusing on the relevant image region fully containing the anomaly. In this paper, we develop an approach to explainable AI in which the anomaly is assured to be overlapping the expected location when present. This is made possible by automatically extracting location-specific labels from textual reports and learning the association of expected locations to labels using a hybrid combination of Bi-Directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM) and DenseNet-121. Use of this expected location to bias the subsequent attention-guided inference network based on ResNet101 results in the isolation of the anomaly at the expected location when present. The method is evaluated on a large chest X-ray dataset.
* 5 pages, Paper presented as a poster at the International Symposium on Biomedical Imaging, 2020, Paper Number 655
Identifying disease-free chest X-ray images with deep transfer learning
Apr 02, 2019Chest X-rays (CXRs) are among the most commonly used medical image modalities. They are mostly used for screening, and an indication of disease typically results in subsequent tests. As this is mostly a screening test used to rule out chest abnormalities, the requesting clinicians are often interested in whether a CXR is normal or not. A machine learning algorithm that can accurately screen out even a small proportion of the "real normal" exams out of all requested CXRs would be highly beneficial in reducing the workload for radiologists. In this work, we report a deep neural network trained for classifying CXRs with the goal of identifying a large number of normal (disease-free) images without risking the discharge of sick patients. We use an ImageNet-pretrained Inception-ResNet-v2 model to provide the image features, which are further used to train a model on CXRs labelled by expert radiologists. The probability threshold for classification is optimized for 100% precision for the normal class, ensuring no sick patients are released. At this threshold we report an average recall of 50%. This means that the proposed solution has the potential to cut in half the number of disease-free CXRs examined by radiologists, without risking the discharge of sick patients.
Classification of radiology reports by modality and anatomy: A comparative study
Dec 27, 2018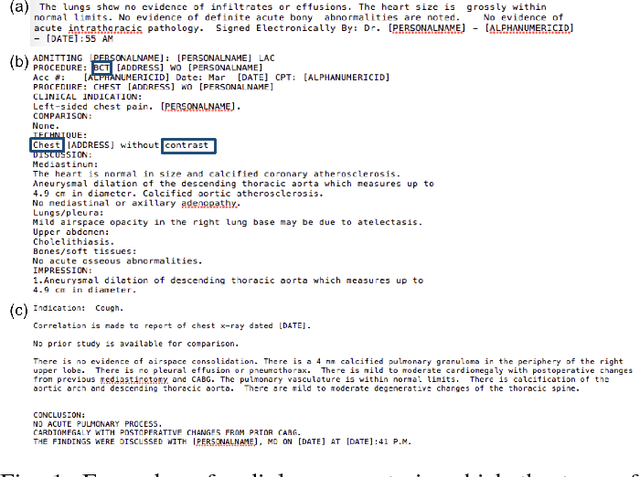
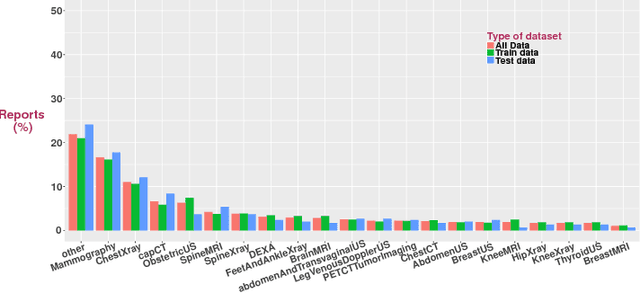
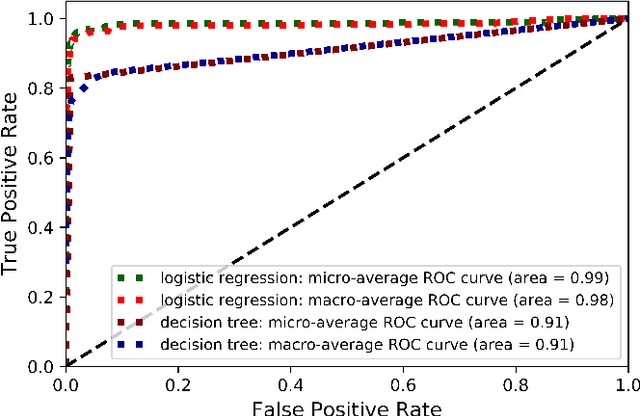
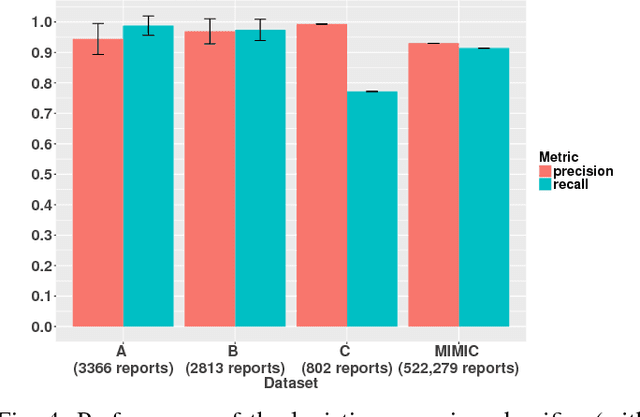
Data labeling is currently a time-consuming task that often requires expert knowledge. In research settings, the availability of correctly labeled data is crucial to ensure that model predictions are accurate and useful. We propose relatively simple machine learning-based models that achieve high performance metrics in the binary and multiclass classification of radiology reports. We compare the performance of these algorithms to that of a data-driven approach based on NLP, and find that the logistic regression classifier outperforms all other models, in both the binary and multiclass classification tasks. We then choose the logistic regression binary classifier to predict chest X-ray (CXR)/ non-chest X-ray (non-CXR) labels in reports from different datasets, unseen during any training phase of any of the models. Even in unseen report collections, the binary logistic regression classifier achieves average precision values of above 0.9. Based on the regression coefficient values, we also identify frequent tokens in CXR and non-CXR reports that are features with possibly high predictive power.