 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Automated Radiology Report Quality through Fine-Grained Phrasal Grounding of Clinical Findings
Dec 02, 2024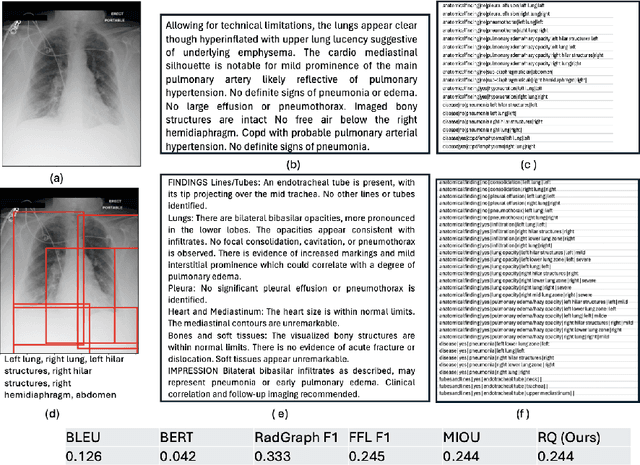
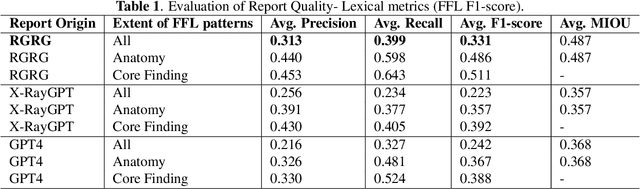
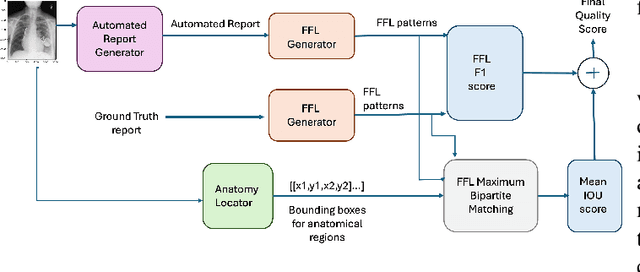

Several evaluation metrics have been developed recently to automatically assess the quality of generative AI reports for chest radiographs based only on textual information using lexical, semantic, or clinical named entity recognition methods. In this paper, we develop a new method of report quality evaluation by first extracting fine-grained finding patterns capturing the location, laterality, and severity of a large number of clinical findings. We then performed phrasal grounding to localize their associated anatomical regions on chest radiograph images. The textual and visual measures are then combined to rate the quality of the generated reports. We present results that compare this evaluation metric with other textual metrics on a gold standard dataset derived from the MIMIC collection and show its robustness and sensitivity to factual errors.
Modern Hopfield Networks meet Encoded Neural Representations -- Addressing Practical Considerations
Sep 24, 2024
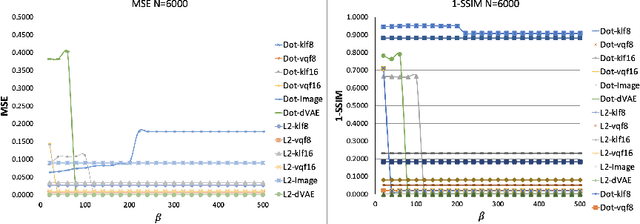
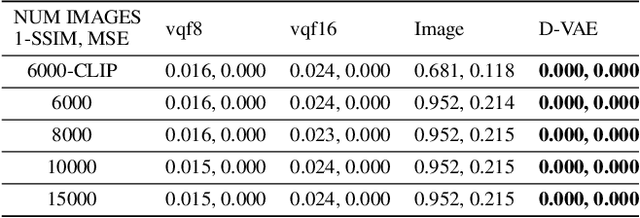
Content-addressable memories such as Modern Hopfield Networks (MHN) have been studied as mathematical models of auto-association and storage/retrieval in the human declarative memory, yet their practical use for large-scale content storage faces challenges. Chief among them is the occurrence of meta-stable states, particularly when handling large amounts of high dimensional content. This paper introduces Hopfield Encoding Networks (HEN), a framework that integrates encoded neural representations into MHNs to improve pattern separability and reduce meta-stable states. We show that HEN can also be used for retrieval in the context of hetero association of images with natural language queries, thus removing the limitation of requiring access to partial content in the same domain. Experimental results demonstrate substantial reduction in meta-stable states and increased storage capacity while still enabling perfect recall of a significantly larger number of inputs advancing the practical utility of associative memory networks for real-world tasks.
Image-Based Soil Organic Carbon Remote Sensing from Satellite Images with Fourier Neural Operator and Structural Similarity
Nov 21, 2023

Soil organic carbon (SOC) sequestration is the transfer and storage of atmospheric carbon dioxide in soils, which plays an important role in climate change mitigation. SOC concentration can be improved by proper land use, thus it is beneficial if SOC can be estimated at a regional or global scale. As multispectral satellite data can provide SOC-related information such as vegetation and soil properties at a global scale, estimation of SOC through satellite data has been explored as an alternative to manual soil sampling. Although existing studies show promising results, they are mainly based on pixel-based approaches with traditional machine learning methods, and convolutional neural networks (CNNs) are uncommon. To study the use of CNNs on SOC remote sensing, here we propose the FNO-DenseNet based on the Fourier neural operator (FNO). By combining the advantages of the FNO and DenseNet, the FNO-DenseNet outperformed the FNO in our experiments with hundreds of times fewer parameters. The FNO-DenseNet also outperformed a pixel-based random forest by 18% in the mean absolute percentage error.
Multimodal Machine Learning in Image-Based and Clinical Biomedicine: Survey and Prospects
Nov 20, 2023Machine learning (ML) applications in medical artificial intelligence (AI) systems have shifted from traditional and statistical methods to increasing application of deep learning models. This survey navigates the current landscape of multimodal ML, focusing on its profound impact on medical image analysis and clinical decision support systems. Emphasizing challenges and innovations in addressing multimodal representation, fusion, translation, alignment, and co-learning, the paper explores the transformative potential of multimodal models for clinical predictions. It also questions practical implementation of such models, bringing attention to the dynamics between decision support systems and healthcare providers. Despite advancements, challenges such as data biases and the scarcity of "big data" in many biomedical domains persist. We conclude with a discussion on effective innovation and collaborative efforts to further the miss
HartleyMHA: Self-Attention in Frequency Domain for Resolution-Robust and Parameter-Efficient 3D Image Segmentation
Oct 05, 2023With the introduction of Transformers, different attention-based models have been proposed for image segmentation with promising results. Although self-attention allows capturing of long-range dependencies, it suffers from a quadratic complexity in the image size especially in 3D. To avoid the out-of-memory error during training, input size reduction is usually required for 3D segmentation, but the accuracy can be suboptimal when the trained models are applied on the original image size. To address this limitation, inspired by the Fourier neural operator (FNO), we introduce the HartleyMHA model which is robust to training image resolution with efficient self-attention. FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We modify the FNO by using the Hartley transform with shared parameters to reduce the model size by orders of magnitude, and this allows us to further apply self-attention in the frequency domain for more expressive high-order feature combination with improved efficiency. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
FNOSeg3D: Resolution-Robust 3D Image Segmentation with Fourier Neural Operator
Oct 05, 2023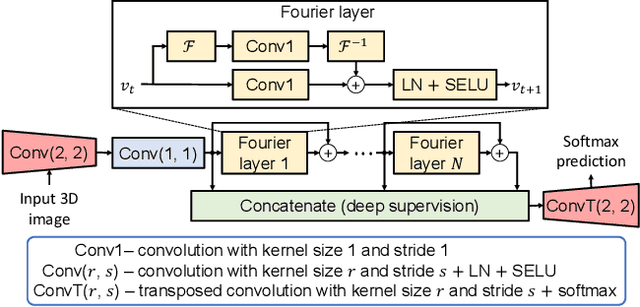
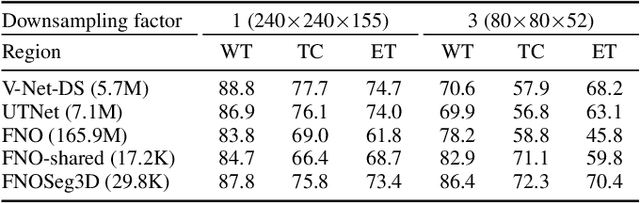
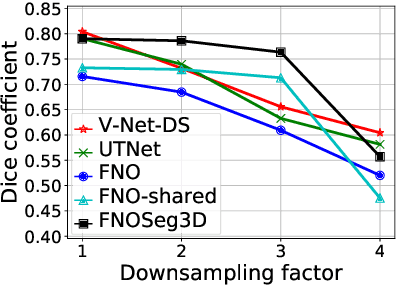

Due to the computational complexity of 3D medical image segmentation, training with downsampled images is a common remedy for out-of-memory errors in deep learning. Nevertheless, as standard spatial convolution is sensitive to variations in image resolution, the accuracy of a convolutional neural network trained with downsampled images can be suboptimal when applied on the original resolution. To address this limitation, we introduce FNOSeg3D, a 3D segmentation model robust to training image resolution based on the Fourier neural operator (FNO). The FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We improve the FNO by reducing its parameter requirement and enhancing its learning capability through residual connections and deep supervision, and these result in our FNOSeg3D model which is parameter efficient and resolution robust. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
MaxCorrMGNN: A Multi-Graph Neural Network Framework for Generalized Multimodal Fusion of Medical Data for Outcome Prediction
Jul 13, 2023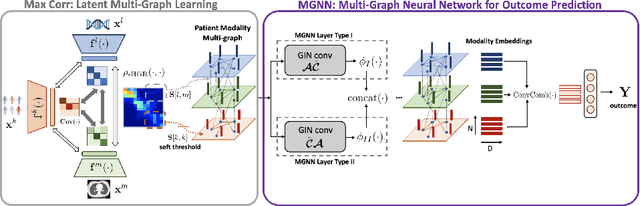
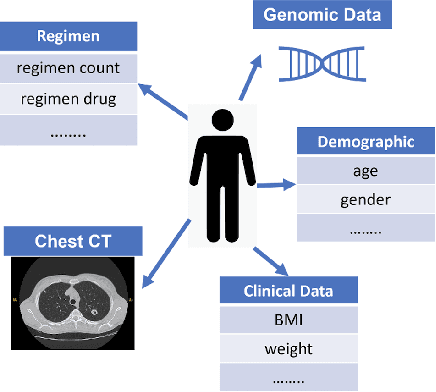
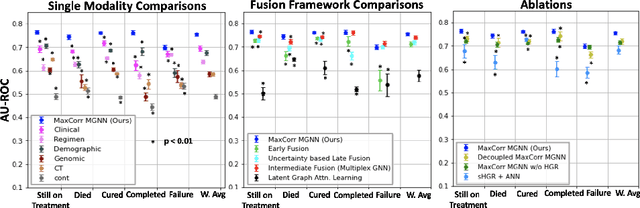
With the emergence of multimodal electronic health records, the evidence for an outcome may be captured across multiple modalities ranging from clinical to imaging and genomic data. Predicting outcomes effectively requires fusion frameworks capable of modeling fine-grained and multi-faceted complex interactions between modality features within and across patients. We develop an innovative fusion approach called MaxCorr MGNN that models non-linear modality correlations within and across patients through Hirschfeld-Gebelein-Renyi maximal correlation (MaxCorr) embeddings, resulting in a multi-layered graph that preserves the identities of the modalities and patients. We then design, for the first time, a generalized multi-layered graph neural network (MGNN) for task-informed reasoning in multi-layered graphs, that learns the parameters defining patient-modality graph connectivity and message passing in an end-to-end fashion. We evaluate our model an outcome prediction task on a Tuberculosis (TB) dataset consistently outperforming several state-of-the-art neural, graph-based and traditional fusion techniques.
Medical visual question answering using joint self-supervised learning
Feb 25, 2023



Visual Question Answering (VQA) becomes one of the most active research problems in the medical imaging domain. A well-known VQA challenge is the intrinsic diversity between the image and text modalities, and in the medical VQA task, there is another critical problem relying on the limited size of labelled image-question-answer data. In this study we propose an encoder-decoder framework that leverages the image-text joint representation learned from large-scaled medical image-caption data and adapted to the small-sized medical VQA task. The encoder embeds across the image-text dual modalities with self-attention mechanism and is independently pre-trained on the large-scaled medical image-caption dataset by multiple self-supervised learning tasks. Then the decoder is connected to the top of the encoder and fine-tuned using the small-sized medical VQA dataset. The experiment results present that our proposed method achieves better performance comparing with the baseline and SOTA methods.
Unsupervised ensemble-based phenotyping helps enhance the discoverability of genes related to heart morphology
Jan 07, 2023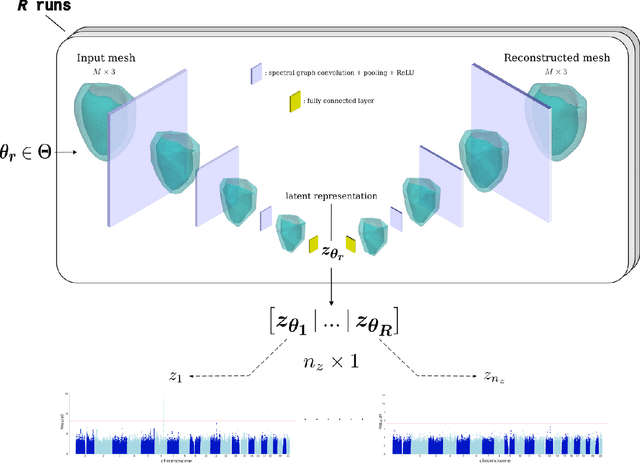
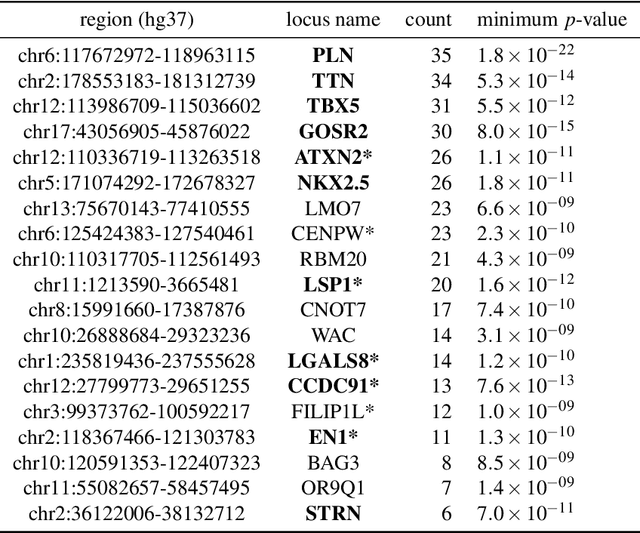
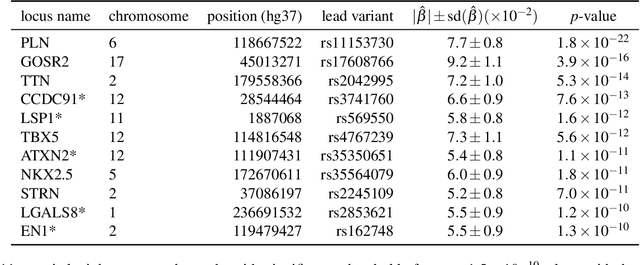
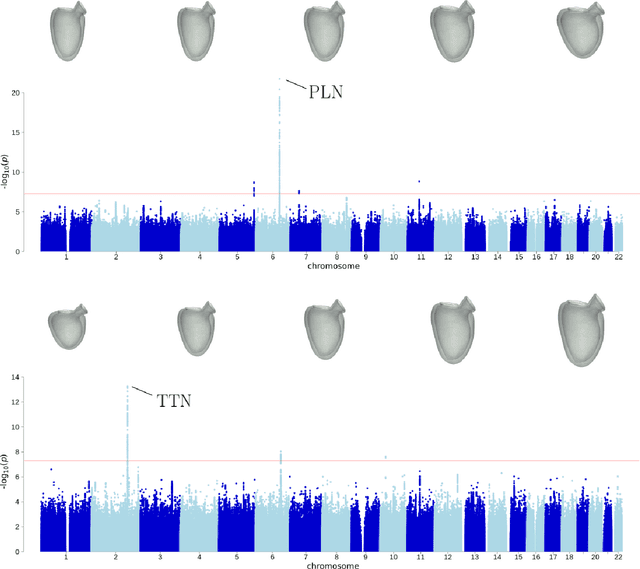
Recent genome-wide association studies (GWAS) have been successful in identifying associations between genetic variants and simple cardiac parameters derived from cardiac magnetic resonance (CMR) images. However, the emergence of big databases including genetic data linked to CMR, facilitates investigation of more nuanced patterns of shape variability. Here, we propose a new framework for gene discovery entitled Unsupervised Phenotype Ensembles (UPE). UPE builds a redundant yet highly expressive representation by pooling a set of phenotypes learned in an unsupervised manner, using deep learning models trained with different hyperparameters. These phenotypes are then analyzed via (GWAS), retaining only highly confident and stable associations across the ensemble. We apply our approach to the UK Biobank database to extract left-ventricular (LV) geometric features from image-derived three-dimensional meshes. We demonstrate that our approach greatly improves the discoverability of genes influencing LV shape, identifying 11 loci with study-wide significance and 8 with suggestive significance. We argue that our approach would enable more extensive discovery of gene associations with image-derived phenotypes for other organs or image modalities.
Towards Automatic Prediction of Outcome in Treatment of Cerebral Aneurysms
Nov 18, 2022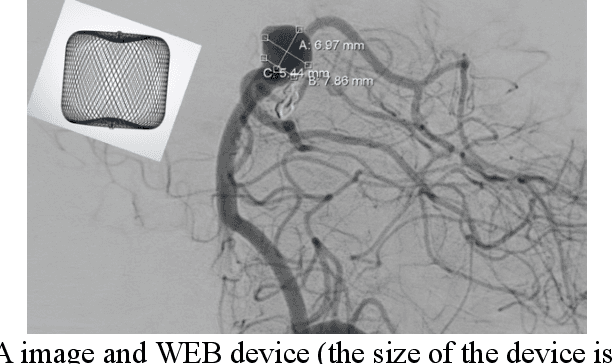
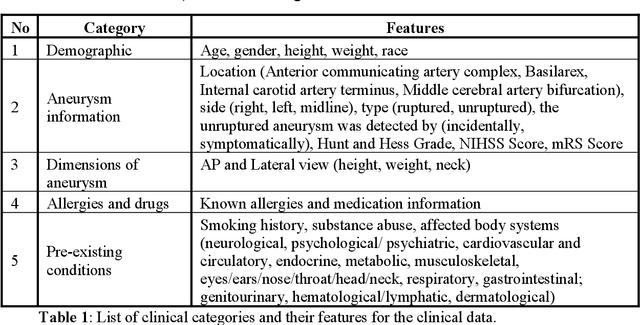
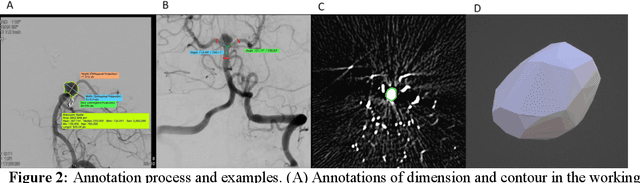
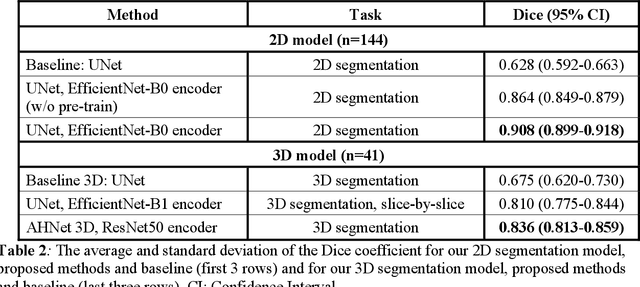
Intrasaccular flow disruptors treat cerebral aneurysms by diverting the blood flow from the aneurysm sac. Residual flow into the sac after the intervention is a failure that could be due to the use of an undersized device, or to vascular anatomy and clinical condition of the patient. We report a machine learning model based on over 100 clinical and imaging features that predict the outcome of wide-neck bifurcation aneurysm treatment with an intravascular embolization device. We combine clinical features with a diverse set of common and novel imaging measurements within a random forest model. We also develop neural network segmentation algorithms in 2D and 3D to contour the sac in angiographic images and automatically calculate the imaging features. These deliver 90% overlap with manual contouring in 2D and 83% in 3D. Our predictive model classifies complete vs. partial occlusion outcomes with an accuracy of 75.31%, and weighted F1-score of 0.74.
* 10 pages