 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Automated Radiology Report Quality through Fine-Grained Phrasal Grounding of Clinical Findings
Dec 02, 2024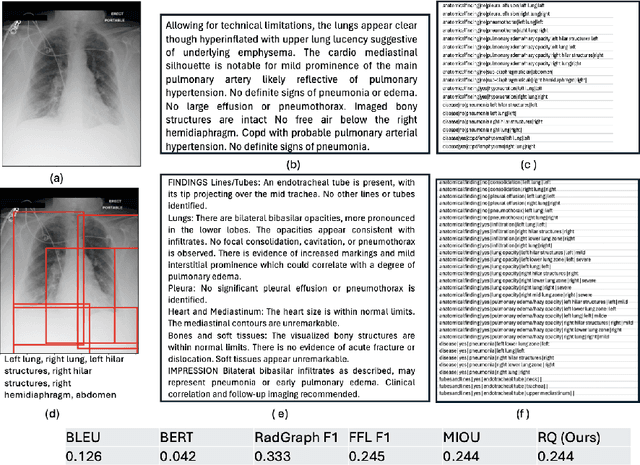
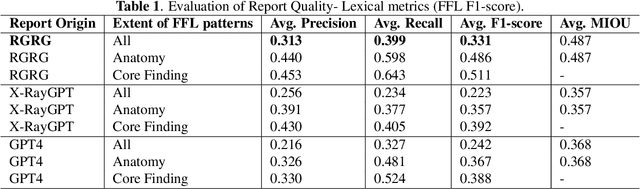
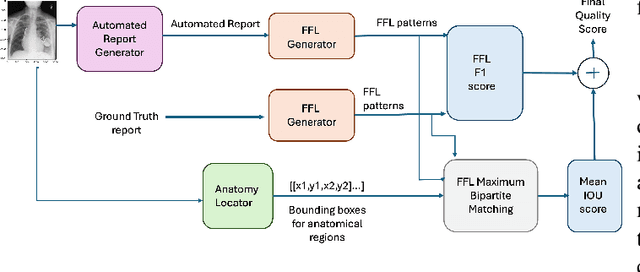

Several evaluation metrics have been developed recently to automatically assess the quality of generative AI reports for chest radiographs based only on textual information using lexical, semantic, or clinical named entity recognition methods. In this paper, we develop a new method of report quality evaluation by first extracting fine-grained finding patterns capturing the location, laterality, and severity of a large number of clinical findings. We then performed phrasal grounding to localize their associated anatomical regions on chest radiograph images. The textual and visual measures are then combined to rate the quality of the generated reports. We present results that compare this evaluation metric with other textual metrics on a gold standard dataset derived from the MIMIC collection and show its robustness and sensitivity to factual errors.
Multimodal Neurodegenerative Disease Subtyping Explained by ChatGPT
Jan 31, 2024Alzheimer's disease (AD) is the most prevalent neurodegenerative disease; yet its currently available treatments are limited to stopping disease progression. Moreover, effectiveness of these treatments is not guaranteed due to the heterogenetiy of the disease. Therefore, it is essential to be able to identify the disease subtypes at a very early stage. Current data driven approaches are able to classify the subtypes at later stages of AD or related disorders, but struggle when predicting at the asymptomatic or prodromal stage. Moreover, most existing models either lack explainability behind the classification or only use a single modality for the assessment, limiting scope of its analysis. Thus, we propose a multimodal framework that uses early-stage indicators such as imaging, genetics and clinical assessments to classify AD patients into subtypes at early stages. Similarly, we build prompts and use large language models, such as ChatGPT, to interpret the findings of our model. In our framework, we propose a tri-modal co-attention mechanism (Tri-COAT) to explicitly learn the cross-modal feature associations. Our proposed model outperforms baseline models and provides insight into key cross-modal feature associations supported by known biological mechanisms.