 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSUM-MCTS: Monte Carlo Tree Search-Inspired HDL Code Summarization with Structural Rewards
Jun 06, 2026Large language models (LLMs) have shown promise in code summarization, yet their effectiveness for Hardware Description Languages (HDLs) like VHDL and Verilog remains underexplored. We propose ROSUM-MCTS, an LLM-guided approach inspired by Monte Carlo Tree Search (MCTS) that refines summaries through structured exploration and reinforcement-driven optimization. Our method integrates both local and global context via a hierarchical candidate expansion mechanism and optimizes summaries using a composite reward function balancing functional correctness (FC), local content adequacy (LCA), and fluency. We evaluate ROSUM-MCTS on the VHDL-eval and Verilog-eval datasets, demonstrating its consistent outperformance over baseline methods by leveraging structured bottom-up refinement and reinforcement-based optimization. Ablation studies confirm the necessity of both local and global expansion strategies, as well as the importance of balancing FC and LCA for optimal performance. Furthermore, ROSUM-MCTS proves robust against superficial modifications, such as variable renaming, maintaining summary quality where baselines degrade. These results establish ROSUM-MCTS as an effective and robust HDL summarization framework, paving the way for further research into reinforcement-enhanced code summarization.
* 7 pages
SYMDIREC: A Neuro-Symbolic Divide-Retrieve-Conquer Framework for Enhanced RTL Synthesis and Summarization
Mar 17, 2026Register-Transfer Level (RTL) synthesis and summarization are central to hardware design automation but remain challenging for Large Language Models (LLMs) due to rigid HDL syntax, limited supervision, and weak alignment with natural language. Existing prompting and retrieval-augmented generation (RAG) methods have not incorporated symbolic planning, limiting their structural precision. We introduce SYMDIREC, a neuro-symbolic framework that decomposes RTL tasks into symbolic subgoals, retrieves relevant code via a fine-tuned retriever, and assembles verified outputs through LLM reasoning. Supporting both Verilog and VHDL without LLM fine-tuning, SYMDIREC achieves ~20% higher Pass@1 rates for synthesis and 15-20% ROUGE-L improvements for summarization over prompting and RAG baselines, demonstrating the benefits of symbolic guidance in RTL tasks.
Chain-of-Descriptions: Improving Code LLMs for VHDL Code Generation and Summarization
Jul 16, 2025Large Language Models (LLMs) have become widely used across diverse NLP tasks and domains, demonstrating their adaptability and effectiveness. In the realm of Electronic Design Automation (EDA), LLMs show promise for tasks like Register-Transfer Level (RTL) code generation and summarization. However, despite the proliferation of LLMs for general code-related tasks, there's a dearth of research focused on evaluating and refining these models for hardware description languages (HDLs), notably VHDL. In this study, we evaluate the performance of existing code LLMs for VHDL code generation and summarization using various metrics and two datasets -- VHDL-Eval and VHDL-Xform. The latter, an in-house dataset, aims to gauge LLMs' understanding of functionally equivalent code. Our findings reveal consistent underperformance of these models across different metrics, underscoring a significant gap in their suitability for this domain. To address this challenge, we propose Chain-of-Descriptions (CoDes), a novel approach to enhance the performance of LLMs for VHDL code generation and summarization tasks. CoDes involves generating a series of intermediate descriptive steps based on: (i) the problem statement for code generation, and (ii) the VHDL code for summarization. These steps are then integrated with the original input prompt (problem statement or code) and provided as input to the LLMs to generate the final output. Our experiments demonstrate that the CoDes approach significantly surpasses the standard prompting strategy across various metrics on both datasets. This method not only improves the quality of VHDL code generation and summarization but also serves as a framework for future research aimed at enhancing code LLMs for VHDL.
Self-Regulated Data-Free Knowledge Amalgamation for Text Classification
Jun 16, 2024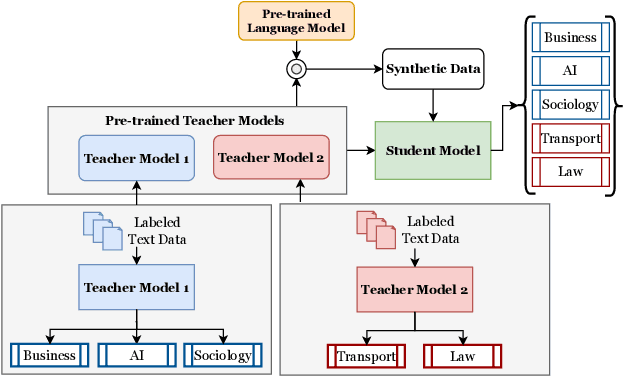
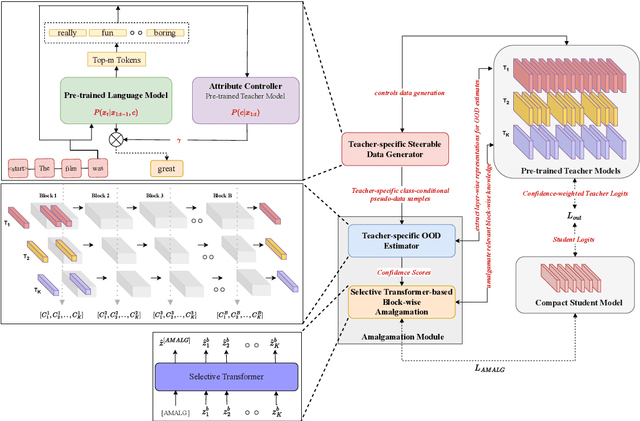
Recently, there has been a growing availability of pre-trained text models on various model repositories. These models greatly reduce the cost of training new models from scratch as they can be fine-tuned for specific tasks or trained on large datasets. However, these datasets may not be publicly accessible due to the privacy, security, or intellectual property issues. In this paper, we aim to develop a lightweight student network that can learn from multiple teacher models without accessing their original training data. Hence, we investigate Data-Free Knowledge Amalgamation (DFKA), a knowledge-transfer task that combines insights from multiple pre-trained teacher models and transfers them effectively to a compact student network. To accomplish this, we propose STRATANET, a modeling framework comprising: (a) a steerable data generator that produces text data tailored to each teacher and (b) an amalgamation module that implements a self-regulative strategy using confidence estimates from the teachers' different layers to selectively integrate their knowledge and train a versatile student. We evaluate our method on three benchmark text classification datasets with varying labels or domains. Empirically, we demonstrate that the student model learned using our STRATANET outperforms several baselines significantly under data-driven and data-free constraints.
VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation
Jun 06, 2024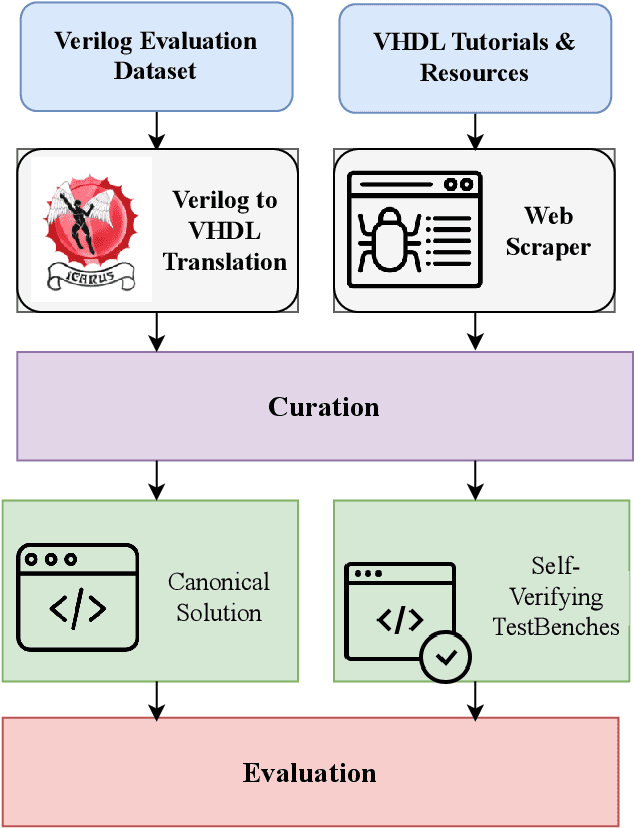


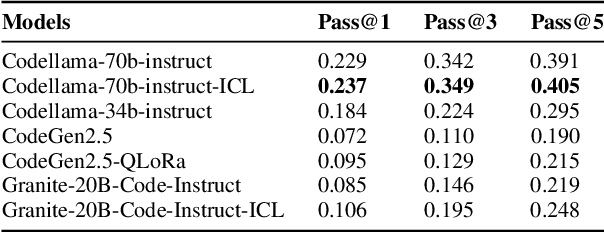
With the unprecedented advancements in Large Language Models (LLMs), their application domains have expanded to include code generation tasks across various programming languages. While significant progress has been made in enhancing LLMs for popular programming languages, there exists a notable gap in comprehensive evaluation frameworks tailored for Hardware Description Languages (HDLs), particularly VHDL. This paper addresses this gap by introducing a comprehensive evaluation framework designed specifically for assessing LLM performance in VHDL code generation task. We construct a dataset for evaluating LLMs on VHDL code generation task. This dataset is constructed by translating a collection of Verilog evaluation problems to VHDL and aggregating publicly available VHDL problems, resulting in a total of 202 problems. To assess the functional correctness of the generated VHDL code, we utilize a curated set of self-verifying testbenches specifically designed for those aggregated VHDL problem set. We conduct an initial evaluation of different LLMs and their variants, including zero-shot code generation, in-context learning (ICL), and Parameter-efficient fine-tuning (PEFT) methods. Our findings underscore the considerable challenges faced by existing LLMs in VHDL code generation, revealing significant scope for improvement. This study emphasizes the necessity of supervised fine-tuning code generation models specifically for VHDL, offering potential benefits to VHDL designers seeking efficient code generation solutions.
Creation and Validation of a Chest X-Ray Dataset with Eye-tracking and Report Dictation for AI Development
Oct 08, 2020
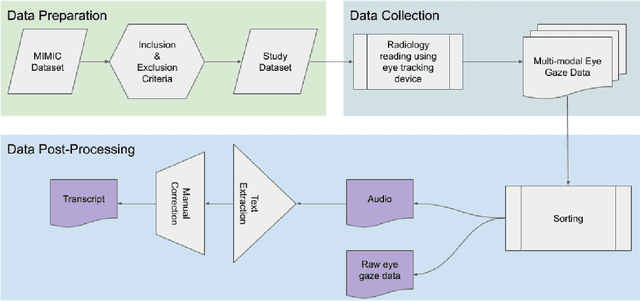
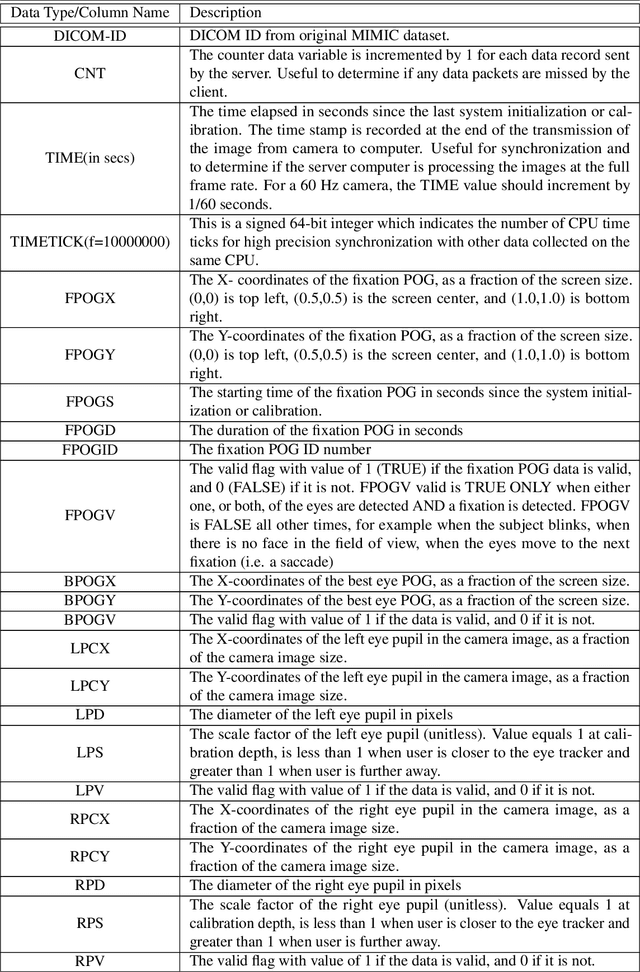
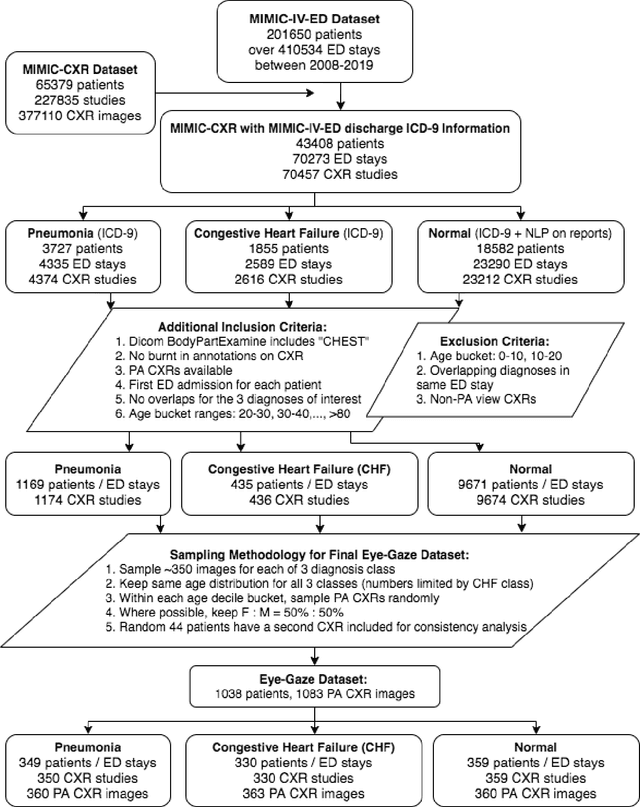
We developed a rich dataset of Chest X-Ray (CXR) images to assist investigators in artificial intelligence. The data were collected using an eye tracking system while a radiologist reviewed and reported on 1,083 CXR images. The dataset contains the following aligned data: CXR image, transcribed radiology report text, radiologist's dictation audio and eye gaze coordinates data. We hope this dataset can contribute to various areas of research particularly towards explainable and multimodal deep learning / machine learning methods. Furthermore, investigators in disease classification and localization, automated radiology report generation, and human-machine interaction can benefit from these data. We report deep learning experiments that utilize the attention maps produced by eye gaze dataset to show the potential utility of this data.
Automatic Diagnosis of Pulmonary Embolism Using an Attention-guided Framework: A Large-scale Study
May 29, 2020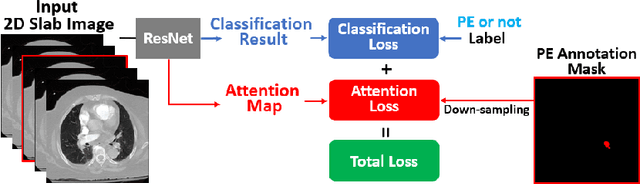
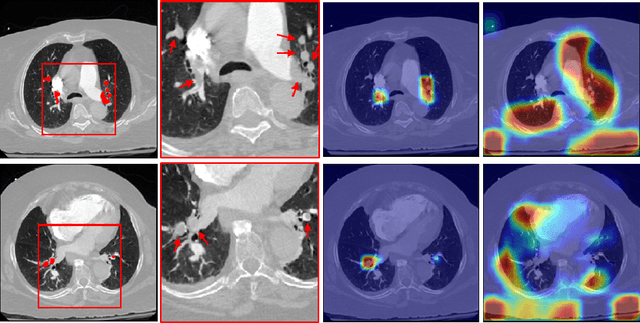
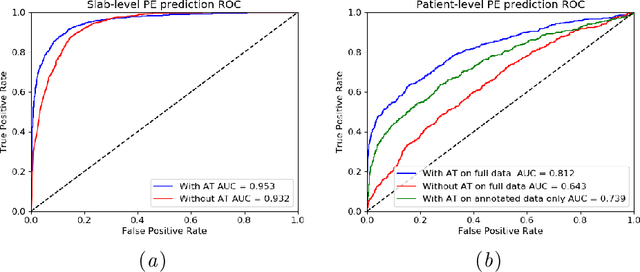
Pulmonary Embolism (PE) is a life-threatening disorder associated with high mortality and morbidity. Prompt diagnosis and immediate initiation of therapeutic action is important. We explored a deep learning model to detect PE on volumetric contrast-enhanced chest CT scans using a 2-stage training strategy. First, a residual convolutional neural network (ResNet) was trained using annotated 2D images. In addition to the classification loss, an attention loss was added during training to help the network focus attention on PE. Next, a recurrent network was used to scan sequentially through the features provided by the pre-trained ResNet to detect PE. This combination allows the network to be trained using both a limited and sparse set of pixel-level annotated images and a large number of easily obtainable patient-level image-label pairs. We used 1,670 sparsely annotated studies and more than 10,000 labeled studies in our training. On a test set with 2,160 patient studies, the proposed method achieved an area under the ROC curve (AUC) of 0.812. The proposed framework is also able to provide localized attention maps that indicate possible PE lesions, which could potentially help radiologists accelerate the diagnostic process.
Pi-PE: A Pipeline for Pulmonary Embolism Detection using Sparsely Annotated 3D CT Images
Oct 21, 2019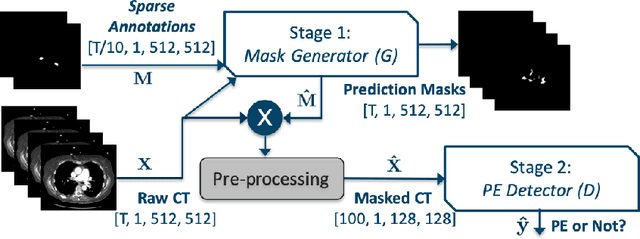

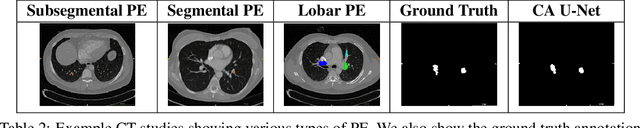
Pulmonary embolisms (PE) are known to be one of the leading causes for cardiac-related mortality. Due to inherent variabilities in how PE manifests and the cumbersome nature of manual diagnosis, there is growing interest in leveraging AI tools for detecting PE. In this paper, we build a two-stage detection pipeline that is accurate, computationally efficient, robust to variations in PE types and kernels used for CT reconstruction, and most importantly, does not require dense annotations. Given the challenges in acquiring expert annotations in large-scale datasets, our approach produces state-of-the-art results with very sparse emboli contours (at 10mm slice spacing), while using models with significantly lower number of parameters. We achieve AUC scores of 0.94 on the validation set and 0.85 on the test set of highly severe PEs. Using a large, real-world dataset characterized by complex PE types and patients from multiple hospitals, we present an elaborate empirical study and provide guidelines for designing highly generalizable pipelines.
Generalization Studies of Neural Network Models for Cardiac Disease Detection Using Limited Channel ECG
Jan 05, 2019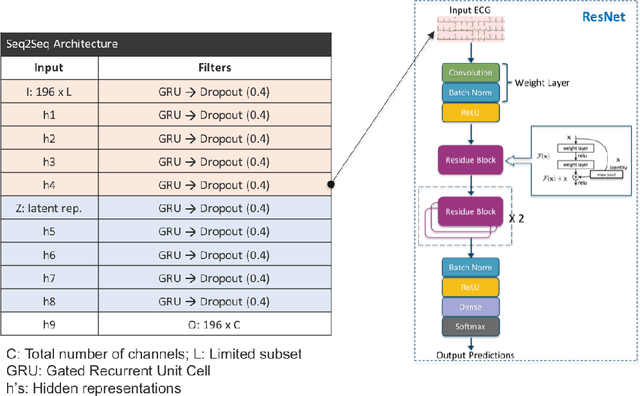

Acceleration of machine learning research in healthcare is challenged by lack of large annotated and balanced datasets. Furthermore, dealing with measurement inaccuracies and exploiting unsupervised data are considered to be central to improving existing solutions. In particular, a primary objective in predictive modeling is to generalize well to both unseen variations within the observed classes, and unseen classes. In this work, we consider such a challenging problem in machine learning driven diagnosis: detecting a gamut of cardiovascular conditions (e.g. infarction, dysrhythmia etc.) from limited channel ECG measurements. Though deep neural networks have achieved unprecedented success in predictive modeling, they rely solely on discriminative models that can generalize poorly to unseen classes. We argue that unsupervised learning can be utilized to construct effective latent spaces that facilitate better generalization. This work extensively compares the generalization of our proposed approach against a state-of-the-art deep learning solution. Our results show significant improvements in F1-scores.
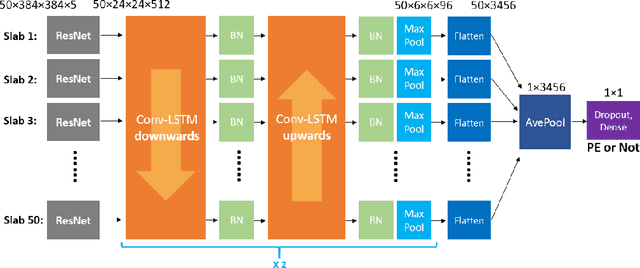
Disease Detection in Weakly Annotated Volumetric Medical Images using a Convolutional LSTM Network
Dec 03, 2018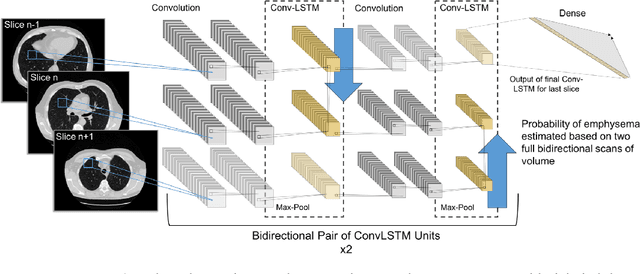
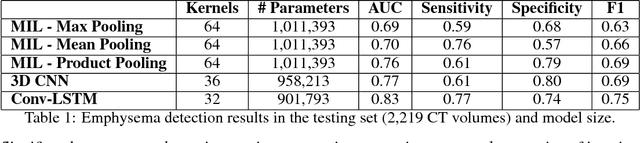
We explore a solution for learning disease signatures from weakly, yet easily obtainable, annotated volumetric medical imaging data by analyzing 3D volumes as a sequence of 2D images. We demonstrate the performance of our solution in the detection of emphysema in lung cancer screening low-dose CT images. Our approach utilizes convolutional long short-term memory (LSTM) to "scan" sequentially through an imaging volume for the presence of disease in a portion of scanned region. This framework allowed effective learning given only volumetric images and binary disease labels, thus enabling training from a large dataset of 6,631 un-annotated image volumes from 4,486 patients. When evaluated in a testing set of 2,163 volumes from 2,163 patients, our model distinguished emphysema with area under the receiver operating characteristic curve (AUC) of .83. This approach was found to outperform 2D convolutional neural networks (CNN) implemented with various multiple-instance learning schemes (AUC=0.69-0.76) and a 3D CNN (AUC=.77).