 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Descriptions: Improving Code LLMs for VHDL Code Generation and Summarization
Jul 16, 2025Large Language Models (LLMs) have become widely used across diverse NLP tasks and domains, demonstrating their adaptability and effectiveness. In the realm of Electronic Design Automation (EDA), LLMs show promise for tasks like Register-Transfer Level (RTL) code generation and summarization. However, despite the proliferation of LLMs for general code-related tasks, there's a dearth of research focused on evaluating and refining these models for hardware description languages (HDLs), notably VHDL. In this study, we evaluate the performance of existing code LLMs for VHDL code generation and summarization using various metrics and two datasets -- VHDL-Eval and VHDL-Xform. The latter, an in-house dataset, aims to gauge LLMs' understanding of functionally equivalent code. Our findings reveal consistent underperformance of these models across different metrics, underscoring a significant gap in their suitability for this domain. To address this challenge, we propose Chain-of-Descriptions (CoDes), a novel approach to enhance the performance of LLMs for VHDL code generation and summarization tasks. CoDes involves generating a series of intermediate descriptive steps based on: (i) the problem statement for code generation, and (ii) the VHDL code for summarization. These steps are then integrated with the original input prompt (problem statement or code) and provided as input to the LLMs to generate the final output. Our experiments demonstrate that the CoDes approach significantly surpasses the standard prompting strategy across various metrics on both datasets. This method not only improves the quality of VHDL code generation and summarization but also serves as a framework for future research aimed at enhancing code LLMs for VHDL.
Self-Regulated Data-Free Knowledge Amalgamation for Text Classification
Jun 16, 2024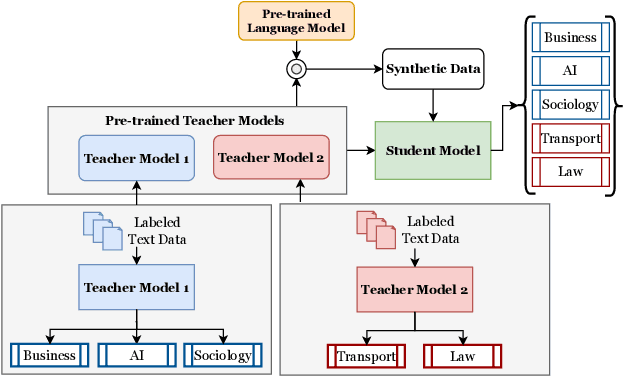
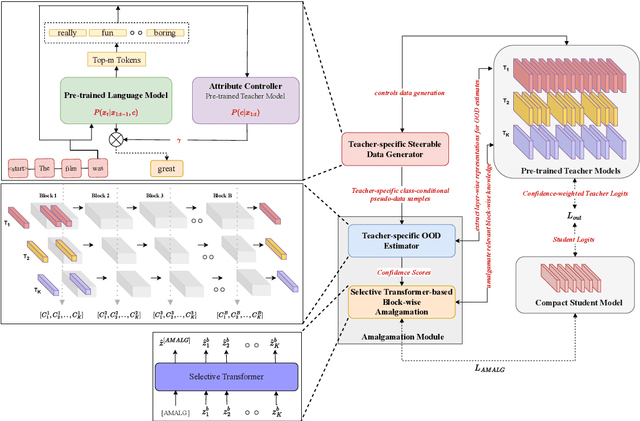
Recently, there has been a growing availability of pre-trained text models on various model repositories. These models greatly reduce the cost of training new models from scratch as they can be fine-tuned for specific tasks or trained on large datasets. However, these datasets may not be publicly accessible due to the privacy, security, or intellectual property issues. In this paper, we aim to develop a lightweight student network that can learn from multiple teacher models without accessing their original training data. Hence, we investigate Data-Free Knowledge Amalgamation (DFKA), a knowledge-transfer task that combines insights from multiple pre-trained teacher models and transfers them effectively to a compact student network. To accomplish this, we propose STRATANET, a modeling framework comprising: (a) a steerable data generator that produces text data tailored to each teacher and (b) an amalgamation module that implements a self-regulative strategy using confidence estimates from the teachers' different layers to selectively integrate their knowledge and train a versatile student. We evaluate our method on three benchmark text classification datasets with varying labels or domains. Empirically, we demonstrate that the student model learned using our STRATANET outperforms several baselines significantly under data-driven and data-free constraints.
Representing Knowledge by Spans: A Knowledge-Enhanced Model for Information Extraction
Aug 20, 2022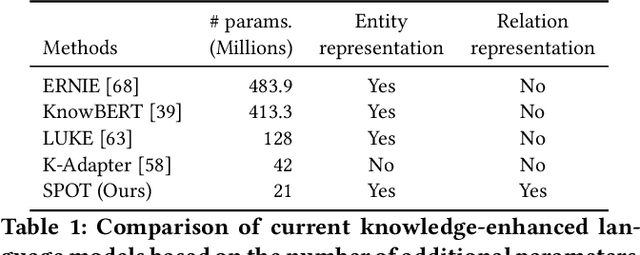
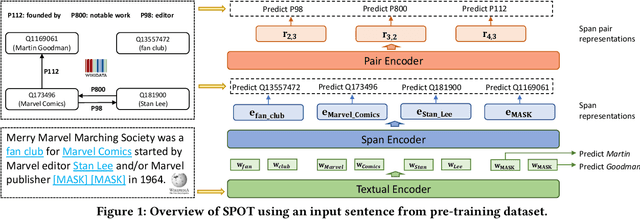
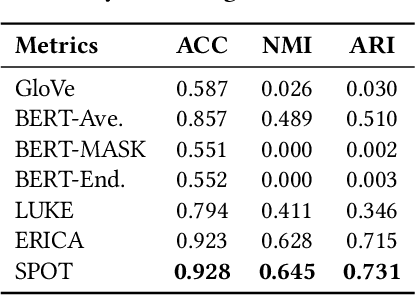
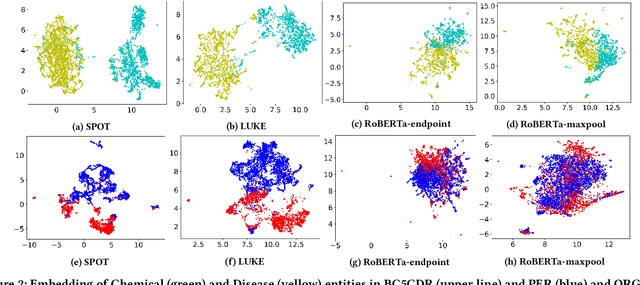
Knowledge-enhanced pre-trained models for language representation have been shown to be more effective in knowledge base construction tasks (i.e.,~relation extraction) than language models such as BERT. These knowledge-enhanced language models incorporate knowledge into pre-training to generate representations of entities or relationships. However, existing methods typically represent each entity with a separate embedding. As a result, these methods struggle to represent out-of-vocabulary entities and a large amount of parameters, on top of their underlying token models (i.e.,~the transformer), must be used and the number of entities that can be handled is limited in practice due to memory constraints. Moreover, existing models still struggle to represent entities and relationships simultaneously. To address these problems, we propose a new pre-trained model that learns representations of both entities and relationships from token spans and span pairs in the text respectively. By encoding spans efficiently with span modules, our model can represent both entities and their relationships but requires fewer parameters than existing models. We pre-trained our model with the knowledge graph extracted from Wikipedia and test it on a broad range of supervised and unsupervised information extraction tasks. Results show that our model learns better representations for both entities and relationships than baselines, while in supervised settings, fine-tuning our model outperforms RoBERTa consistently and achieves competitive results on information extraction tasks.
Practical Skills Demand Forecasting via Representation Learning of Temporal Dynamics
May 18, 2022
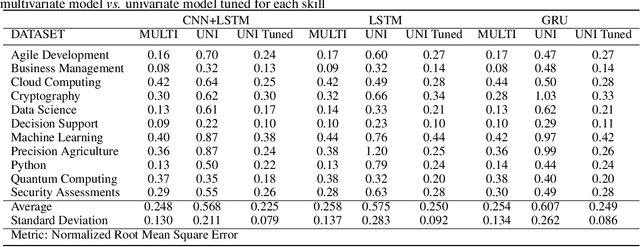
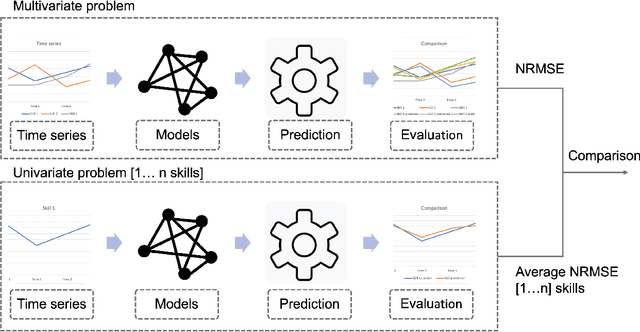
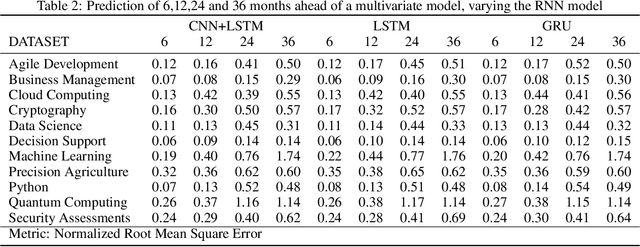
Rapid technological innovation threatens to leave much of the global workforce behind. Today's economy juxtaposes white-hot demand for skilled labor against stagnant employment prospects for workers unprepared to participate in a digital economy. It is a moment of peril and opportunity for every country, with outcomes measured in long-term capital allocation and the life satisfaction of billions of workers. To meet the moment, governments and markets must find ways to quicken the rate at which the supply of skills reacts to changes in demand. More fully and quickly understanding labor market intelligence is one route. In this work, we explore the utility of time series forecasts to enhance the value of skill demand data gathered from online job advertisements. This paper presents a pipeline which makes one-shot multi-step forecasts into the future using a decade of monthly skill demand observations based on a set of recurrent neural network methods. We compare the performance of a multivariate model versus a univariate one, analyze how correlation between skills can influence multivariate model results, and present predictions of demand for a selection of skills practiced by workers in the information technology industry.
Abstractified Multi-instance Learning (AMIL) for Biomedical Relation Extraction
Oct 24, 2021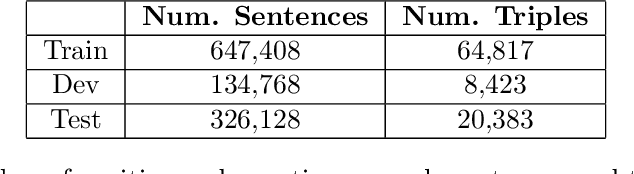

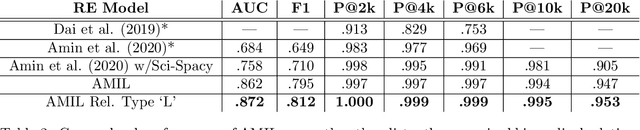
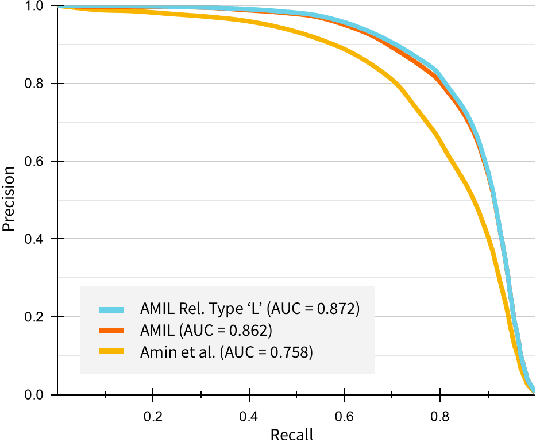
Relation extraction in the biomedical domain is a challenging task due to a lack of labeled data and a long-tail distribution of fact triples. Many works leverage distant supervision which automatically generates labeled data by pairing a knowledge graph with raw textual data. Distant supervision produces noisy labels and requires additional techniques, such as multi-instance learning (MIL), to denoise the training signal. However, MIL requires multiple instances of data and struggles with very long-tail datasets such as those found in the biomedical domain. In this work, we propose a novel reformulation of MIL for biomedical relation extraction that abstractifies biomedical entities into their corresponding semantic types. By grouping entities by types, we are better able to take advantage of the benefits of MIL and further denoise the training signal. We show this reformulation, which we refer to as abstractified multi-instance learning (AMIL), improves performance in biomedical relationship extraction. We also propose a novel relationship embedding architecture that further improves model performance.
* 14 pages, 3 figures, submitted to Automated Knowledge Base Construction (2021)