 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-WIN: Building Chest Radiograph World Model via Predictive Sensing
Nov 18, 2025Chest X-ray radiography (CXR) is an essential medical imaging technique for disease diagnosis. However, as 2D projectional images, CXRs are limited by structural superposition and hence fail to capture 3D anatomies. This limitation makes representation learning and disease diagnosis challenging. To address this challenge, we propose a novel CXR world model named X-WIN, which distills volumetric knowledge from chest computed tomography (CT) by learning to predict its 2D projections in latent space. The core idea is that a world model with internalized knowledge of 3D anatomical structure can predict CXRs under various transformations in 3D space. During projection prediction, we introduce an affinity-guided contrastive alignment loss that leverages mutual similarities to capture rich, correlated information across projections from the same volume. To improve model adaptability, we incorporate real CXRs into training through masked image modeling and employ a domain classifier to encourage statistically similar representations for real and simulated CXRs. Comprehensive experiments show that X-WIN outperforms existing foundation models on diverse downstream tasks using linear probing and few-shot fine-tuning. X-WIN also demonstrates the ability to render 2D projections for reconstructing a 3D CT volume.
More Samples or More Prompt Inputs? Exploring Effective In-Context Sampling for LLM Few-Shot Prompt Engineering
Nov 16, 2023
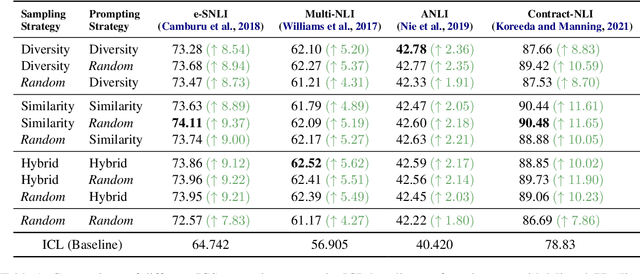
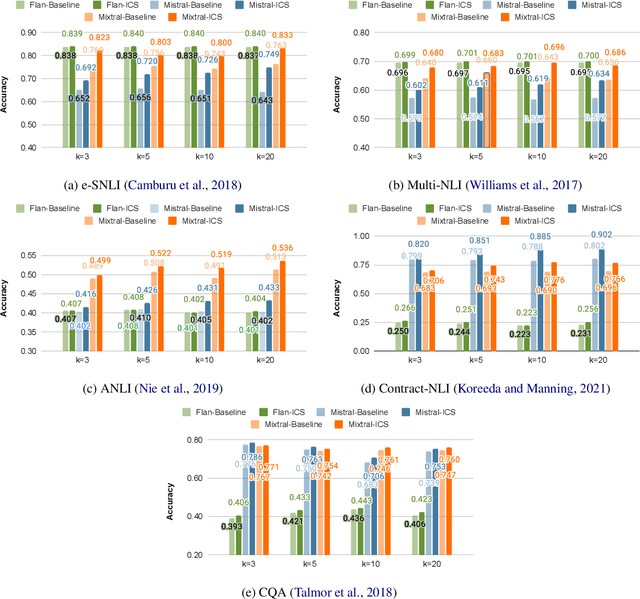
While most existing works on LLM prompt-engineering focus only on how to select a better set of data samples inside one single prompt input (In-Context Learning or ICL), why can't we design and leverage multiple prompt inputs together to further improve the LLM performance? In this work, we propose In-Context Sampling (ICS), a low-resource LLM prompt-engineering technique to produce the most confident prediction results by optimizing the construction of multiple ICL prompt inputs. Extensive experiments with two SOTA LLMs (FlanT5-XL and Mistral-7B) on three NLI datasets (e-SNLI, Multi-NLI, and ANLI) illustrate that ICS can consistently enhance LLM's prediction performance and confidence. An ablation study suggests that a diversity-based ICS strategy may further improve LLM's performance, which sheds light on a new yet promising future research direction.
Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
Aug 16, 2023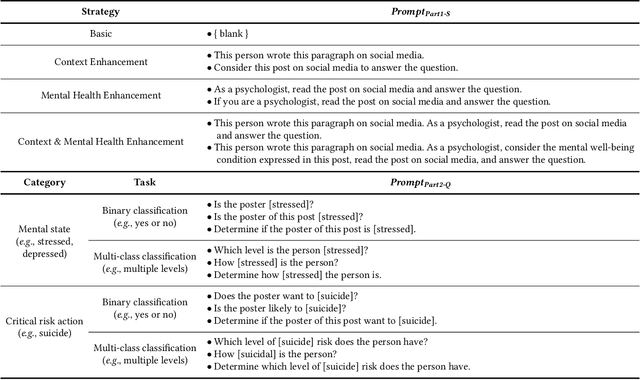



Advances in large language models (LLMs) have empowered a variety of applications. However, there is still a significant gap in research when it comes to understanding and enhancing the capabilities of LLMs in the field of mental health. In this work, we present the first comprehensive evaluation of multiple LLMs, including Alpaca, Alpaca-LoRA, FLAN-T5, GPT-3.5, and GPT-4, on various mental health prediction tasks via online text data. We conduct a broad range of experiments, covering zero-shot prompting, few-shot prompting, and instruction fine-tuning. The results indicate a promising yet limited performance of LLMs with zero-shot and few-shot prompt designs for the mental health tasks. More importantly, our experiments show that instruction finetuning can significantly boost the performance of LLMs for all tasks simultaneously. Our best-finetuned models, Mental-Alpaca and Mental-FLAN-T5, outperform the best prompt design of GPT-3.5 (25 and 15 times bigger) by 10.9% on balanced accuracy and the best of GPT-4 (250 and 150 times bigger) by 4.8%. They further perform on par with the state-of-the-art task-specific language model. We also conduct an exploratory case study on LLMs' capability on the mental health reasoning tasks, illustrating the promising capability of certain models such as GPT-4. We summarize our findings into a set of action guidelines for potential methods to enhance LLMs' capability for mental health tasks. Meanwhile, we also emphasize the important limitations before achieving deployability in real-world mental health settings, such as known racial and gender bias. We highlight the important ethical risks accompanying this line of research.
Beyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
May 22, 2023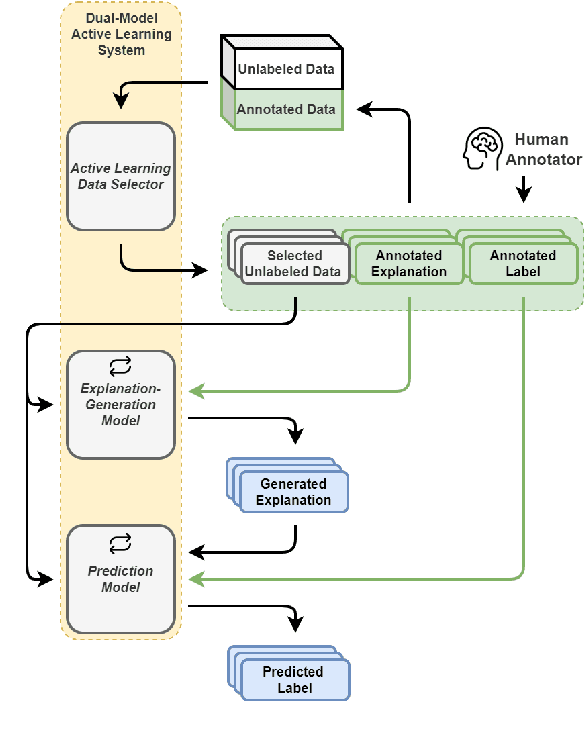
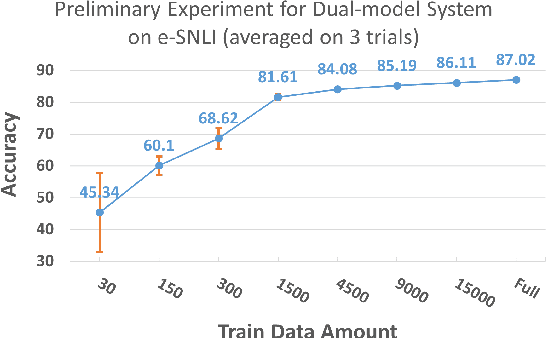

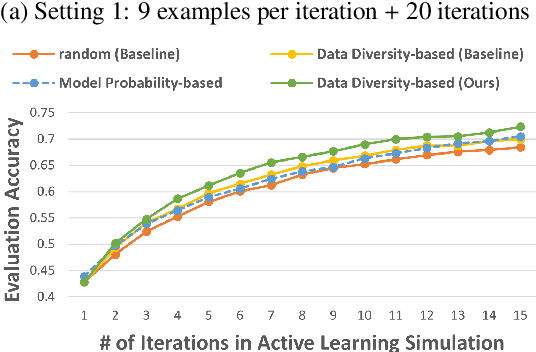
Data annotation is a costly task; thus, researchers have proposed low-scenario learning techniques like Active-Learning (AL) to support human annotators; Yet, existing AL works focus only on the label, but overlook the natural language explanation of a data point, despite that real-world humans (e.g., doctors) often need both the labels and the corresponding explanations at the same time. This work proposes a novel AL architecture to support and reduce human annotations of both labels and explanations in low-resource scenarios. Our AL architecture incorporates an explanation-generation model that can explicitly generate natural language explanations for the prediction model and for assisting humans' decision-making in real-world. For our AL framework, we design a data diversity-based AL data selection strategy that leverages the explanation annotations. The automated AL simulation evaluations demonstrate that our data selection strategy consistently outperforms traditional data diversity-based strategy; furthermore, human evaluation demonstrates that humans prefer our generated explanations to the SOTA explanation-generation system.
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
May 04, 2023Human-annotated labels and explanations are critical for training explainable NLP models. However, unlike human-annotated labels whose quality is easier to calibrate (e.g., with a majority vote), human-crafted free-form explanations can be quite subjective, as some recent works have discussed. Before blindly using them as ground truth to train ML models, a vital question needs to be asked: How do we evaluate a human-annotated explanation's quality? In this paper, we build on the view that the quality of a human-annotated explanation can be measured based on its helpfulness (or impairment) to the ML models' performance for the desired NLP tasks for which the annotations were collected. In comparison to the commonly used Simulatability score, we define a new metric that can take into consideration the helpfulness of an explanation for model performance at both fine-tuning and inference. With the help of a unified dataset format, we evaluated the proposed metric on five datasets (e.g., e-SNLI) against two model architectures (T5 and BART), and the results show that our proposed metric can objectively evaluate the quality of human-annotated explanations, while Simulatability falls short.
End-to-End Table Question Answering via Retrieval-Augmented Generation
Mar 30, 2022
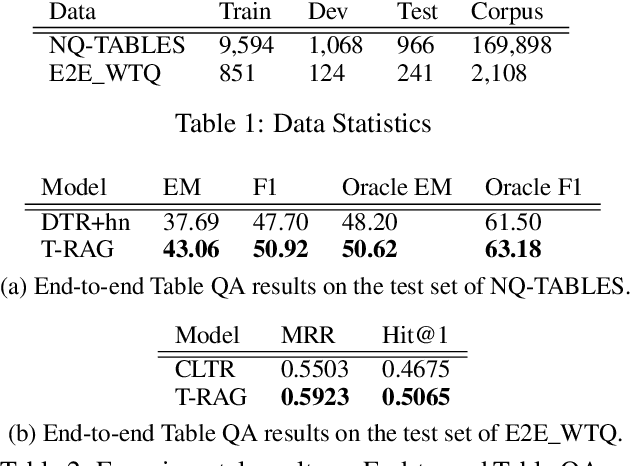
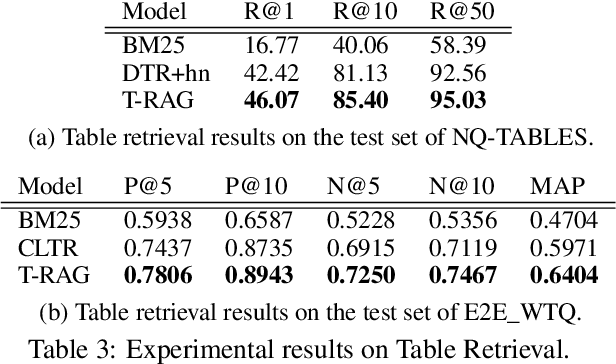
Most existing end-to-end Table Question Answering (Table QA) models consist of a two-stage framework with a retriever to select relevant table candidates from a corpus and a reader to locate the correct answers from table candidates. Even though the accuracy of the reader models is significantly improved with the recent transformer-based approaches, the overall performance of such frameworks still suffers from the poor accuracy of using traditional information retrieval techniques as retrievers. To alleviate this problem, we introduce T-RAG, an end-to-end Table QA model, where a non-parametric dense vector index is fine-tuned jointly with BART, a parametric sequence-to-sequence model to generate answer tokens. Given any natural language question, T-RAG utilizes a unified pipeline to automatically search through a table corpus to directly locate the correct answer from the table cells. We apply T-RAG to recent open-domain Table QA benchmarks and demonstrate that the fine-tuned T-RAG model is able to achieve state-of-the-art performance in both the end-to-end Table QA and the table retrieval tasks.
AnaXNet: Anatomy Aware Multi-label Finding Classification in Chest X-ray
May 20, 2021
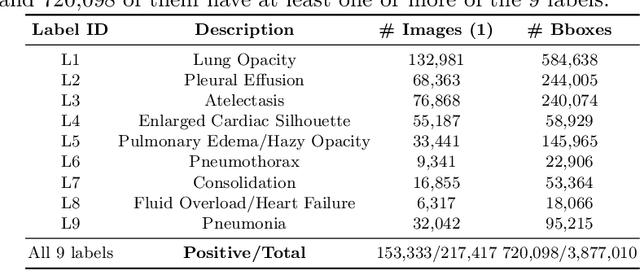
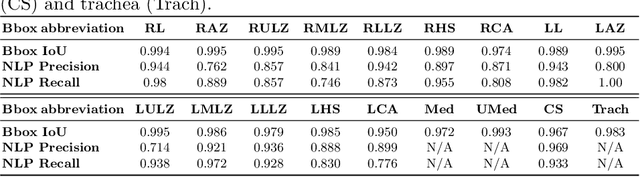
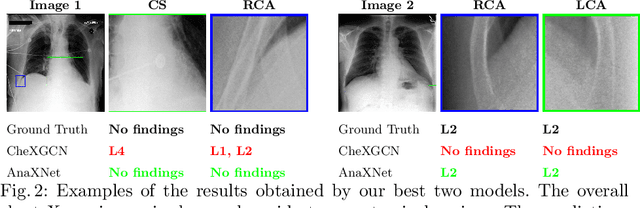
Radiologists usually observe anatomical regions of chest X-ray images as well as the overall image before making a decision. However, most existing deep learning models only look at the entire X-ray image for classification, failing to utilize important anatomical information. In this paper, we propose a novel multi-label chest X-ray classification model that accurately classifies the image finding and also localizes the findings to their correct anatomical regions. Specifically, our model consists of two modules, the detection module and the anatomical dependency module. The latter utilizes graph convolutional networks, which enable our model to learn not only the label dependency but also the relationship between the anatomical regions in the chest X-ray. We further utilize a method to efficiently create an adjacency matrix for the anatomical regions using the correlation of the label across the different regions. Detailed experiments and analysis of our results show the effectiveness of our method when compared to the current state-of-the-art multi-label chest X-ray image classification methods while also providing accurate location information.
Explainable Deep RDFS Reasoner
Feb 10, 2020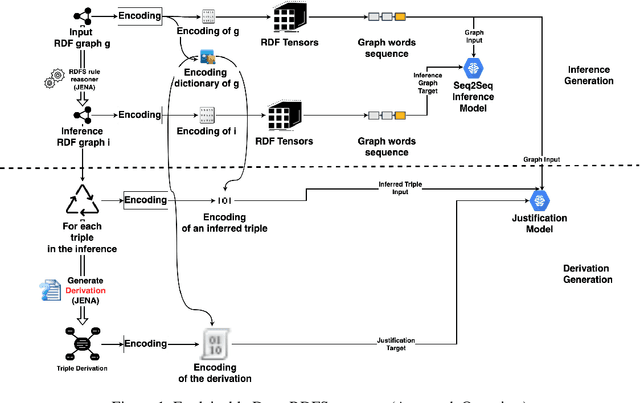
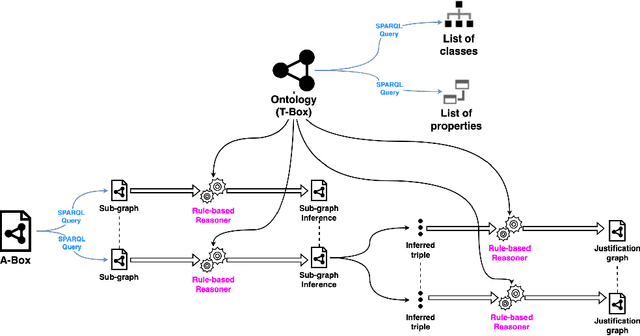

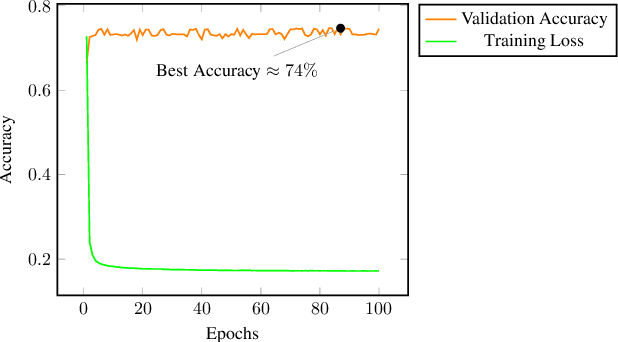
Recent research efforts aiming to bridge the Neural-Symbolic gap for RDFS reasoning proved empirically that deep learning techniques can be used to learn RDFS inference rules. However, one of their main deficiencies compared to rule-based reasoners is the lack of derivations for the inferred triples (i.e. explainability in AI terms). In this paper, we build on these approaches to provide not only the inferred graph but also explain how these triples were inferred. In the graph words approach, RDF graphs are represented as a sequence of graph words where inference can be achieved through neural machine translation. To achieve explainability in RDFS reasoning, we revisit this approach and introduce a new neural network model that gets the input graph--as a sequence of graph words-- as well as the encoding of the inferred triple and outputs the derivation for the inferred triple. We evaluated our justification model on two datasets: a synthetic dataset-- LUBM benchmark-- and a real-world dataset --ScholarlyData about conferences-- where the lowest validation accuracy approached 96%.
Exploiting Class Learnability in Noisy Data
Nov 15, 2018
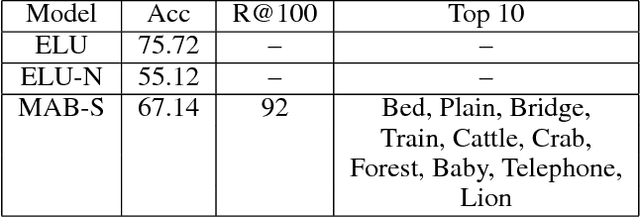
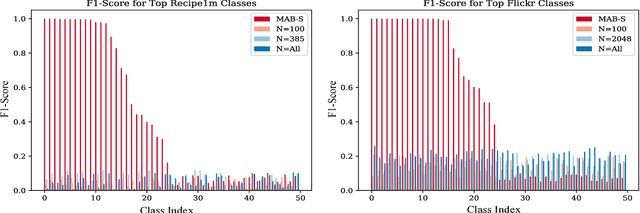

In many domains, collecting sufficient labeled training data for supervised machine learning requires easily accessible but noisy sources, such as crowdsourcing services or tagged Web data. Noisy labels occur frequently in data sets harvested via these means, sometimes resulting in entire classes of data on which learned classifiers generalize poorly. For real world applications, we argue that it can be beneficial to avoid training on such classes entirely. In this work, we aim to explore the classes in a given data set, and guide supervised training to spend time on a class proportional to its learnability. By focusing the training process, we aim to improve model generalization on classes with a strong signal. To that end, we develop an online algorithm that works in conjunction with classifier and training algorithm, iteratively selecting training data for the classifier based on how well it appears to generalize on each class. Testing our approach on a variety of data sets, we show our algorithm learns to focus on classes for which the model has low generalization error relative to strong baselines, yielding a classifier with good performance on learnable classes.