 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRF: A Generalizable Dynamic Persona Refinement Framework for Optimizing Behavior Alignment Between Personalized LLM Role-Playing Agents and Humans
Oct 16, 2025The emerging large language model role-playing agents (LLM RPAs) aim to simulate individual human behaviors, but the persona fidelity is often undermined by manually-created profiles (e.g., cherry-picked information and personality characteristics) without validating the alignment with the target individuals. To address this limitation, our work introduces the Dynamic Persona Refinement Framework (DPRF).DPRF aims to optimize the alignment of LLM RPAs' behaviors with those of target individuals by iteratively identifying the cognitive divergence, either through free-form or theory-grounded, structured analysis, between generated behaviors and human ground truth, and refining the persona profile to mitigate these divergences.We evaluate DPRF with five LLMs on four diverse behavior-prediction scenarios: formal debates, social media posts with mental health issues, public interviews, and movie reviews.DPRF can consistently improve behavioral alignment considerably over baseline personas and generalizes across models and scenarios.Our work provides a robust methodology for creating high-fidelity persona profiles and enhancing the validity of downstream applications, such as user simulation, social studies, and personalized AI.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025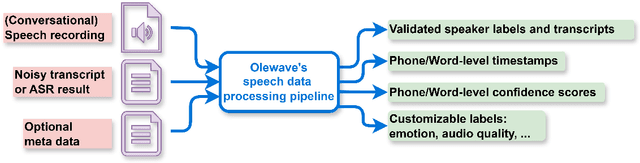
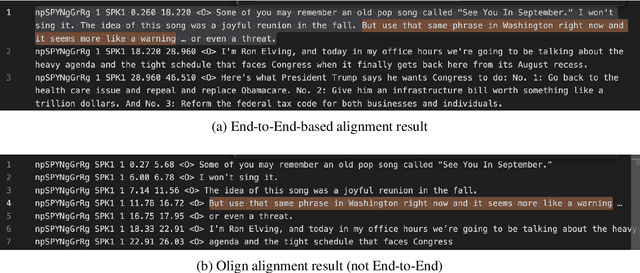
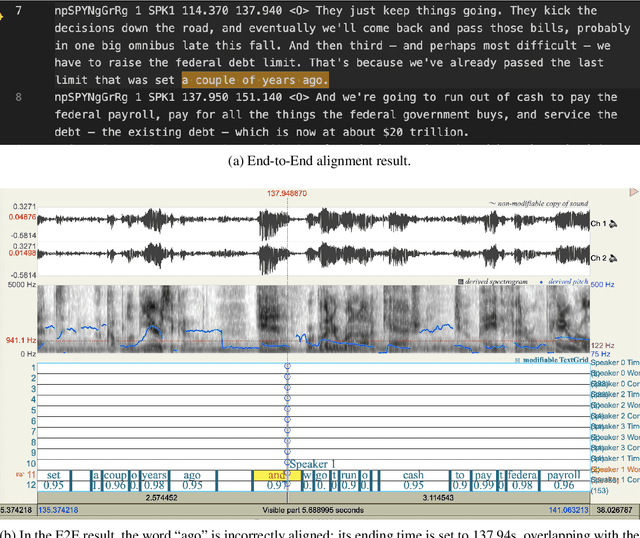
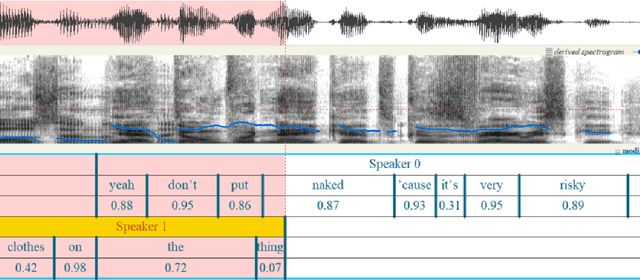
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
WatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025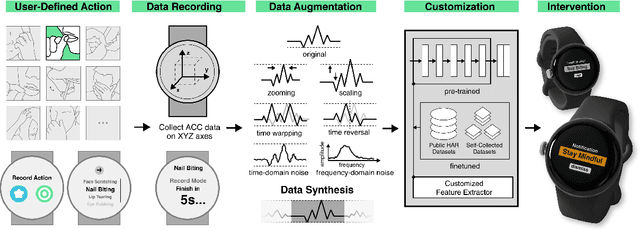
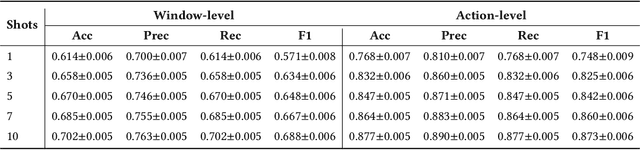
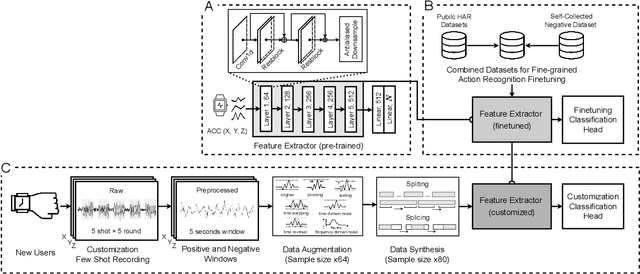
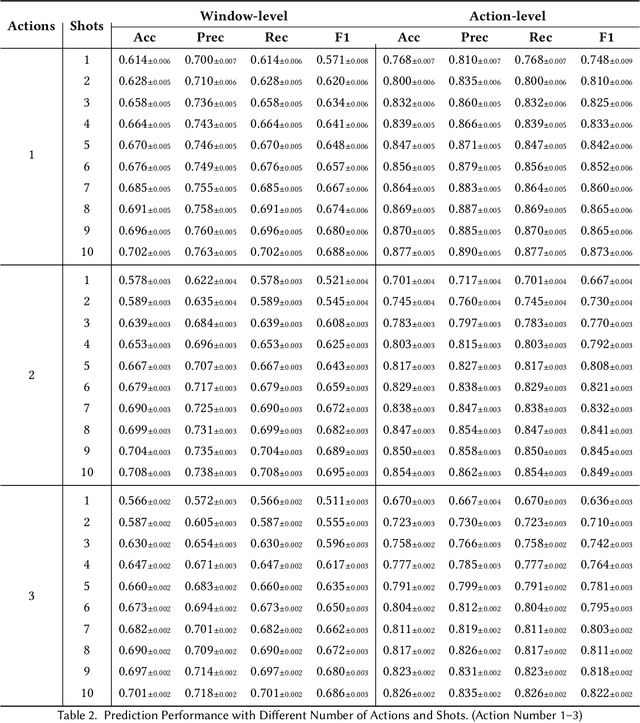
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
FairytaleCQA: Integrating a Commonsense Knowledge Graph into Children's Storybook Narratives
Nov 16, 2023
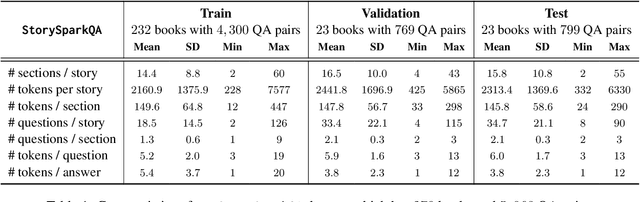
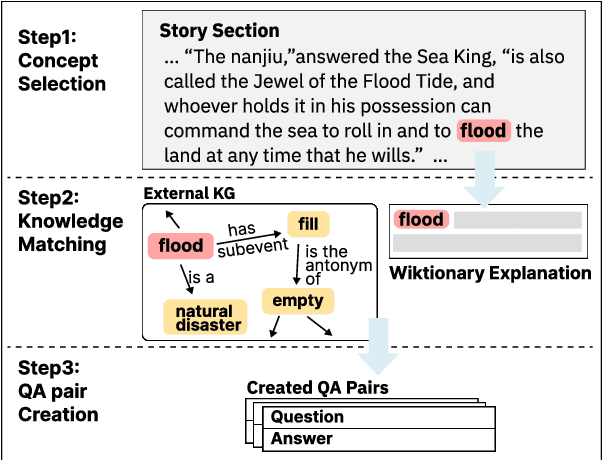
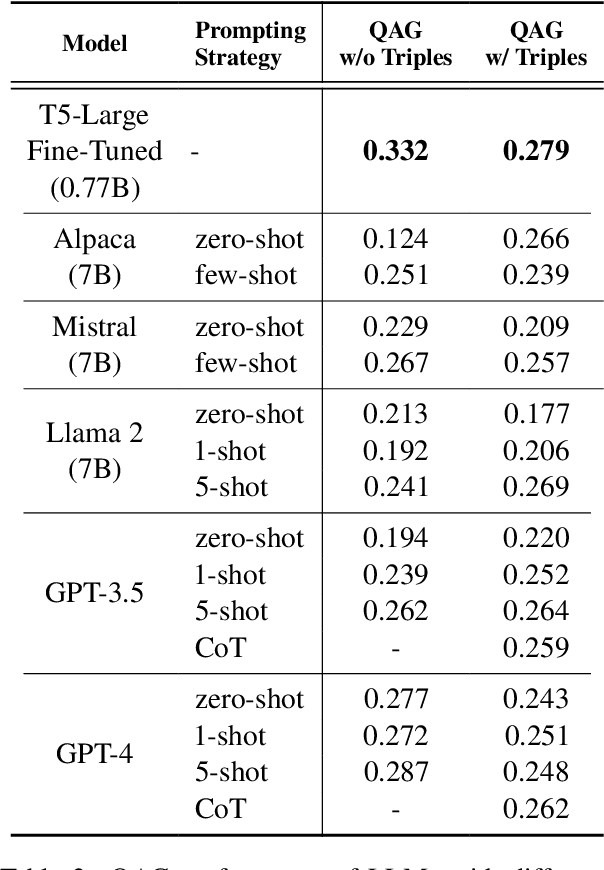
AI models (including LLM) often rely on narrative question-answering (QA) datasets to provide customized QA functionalities to support downstream children education applications; however, existing datasets only include QA pairs that are grounded within the given storybook content, but children can learn more when teachers refer the storybook content to real-world knowledge (e.g., commonsense knowledge). We introduce the FairytaleCQA dataset, which is annotated by children education experts, to supplement 278 storybook narratives with educationally appropriate commonsense knowledge. The dataset has 5,868 QA pairs that not only originate from the storybook narrative but also contain the commonsense knowledge grounded by an external knowledge graph (i.e., ConceptNet). A follow-up experiment shows that a smaller model (T5-large) fine-tuned with FairytaleCQA reliably outperforms much larger prompt-engineered LLM (e.g., GPT-4) in this new QA-pair generation task (QAG). This result suggests that: 1) our dataset brings novel challenges to existing LLMs, and 2) human experts' data annotation are still critical as they have much nuanced knowledge that LLMs do not know in the children educational domain.
Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
Aug 16, 2023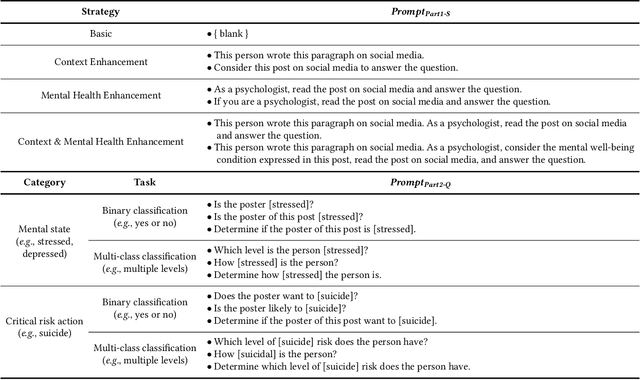



Advances in large language models (LLMs) have empowered a variety of applications. However, there is still a significant gap in research when it comes to understanding and enhancing the capabilities of LLMs in the field of mental health. In this work, we present the first comprehensive evaluation of multiple LLMs, including Alpaca, Alpaca-LoRA, FLAN-T5, GPT-3.5, and GPT-4, on various mental health prediction tasks via online text data. We conduct a broad range of experiments, covering zero-shot prompting, few-shot prompting, and instruction fine-tuning. The results indicate a promising yet limited performance of LLMs with zero-shot and few-shot prompt designs for the mental health tasks. More importantly, our experiments show that instruction finetuning can significantly boost the performance of LLMs for all tasks simultaneously. Our best-finetuned models, Mental-Alpaca and Mental-FLAN-T5, outperform the best prompt design of GPT-3.5 (25 and 15 times bigger) by 10.9% on balanced accuracy and the best of GPT-4 (250 and 150 times bigger) by 4.8%. They further perform on par with the state-of-the-art task-specific language model. We also conduct an exploratory case study on LLMs' capability on the mental health reasoning tasks, illustrating the promising capability of certain models such as GPT-4. We summarize our findings into a set of action guidelines for potential methods to enhance LLMs' capability for mental health tasks. Meanwhile, we also emphasize the important limitations before achieving deployability in real-world mental health settings, such as known racial and gender bias. We highlight the important ethical risks accompanying this line of research.