 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairytaleCQA: Integrating a Commonsense Knowledge Graph into Children's Storybook Narratives
Paper and Code

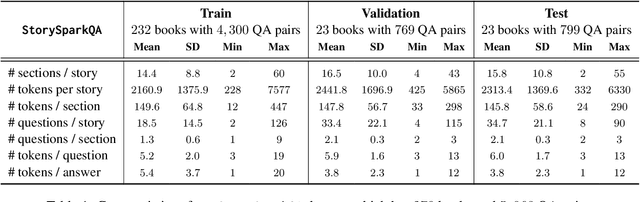
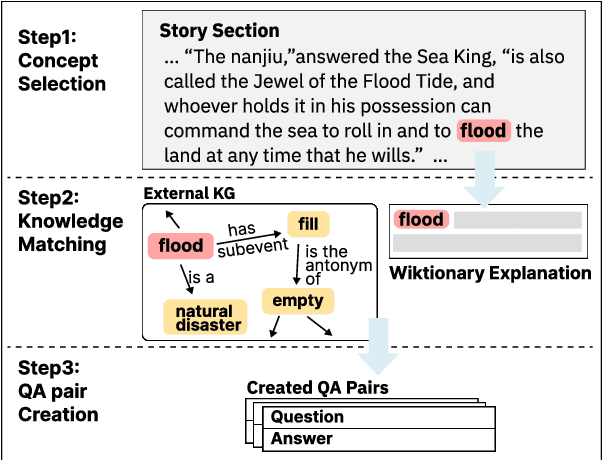
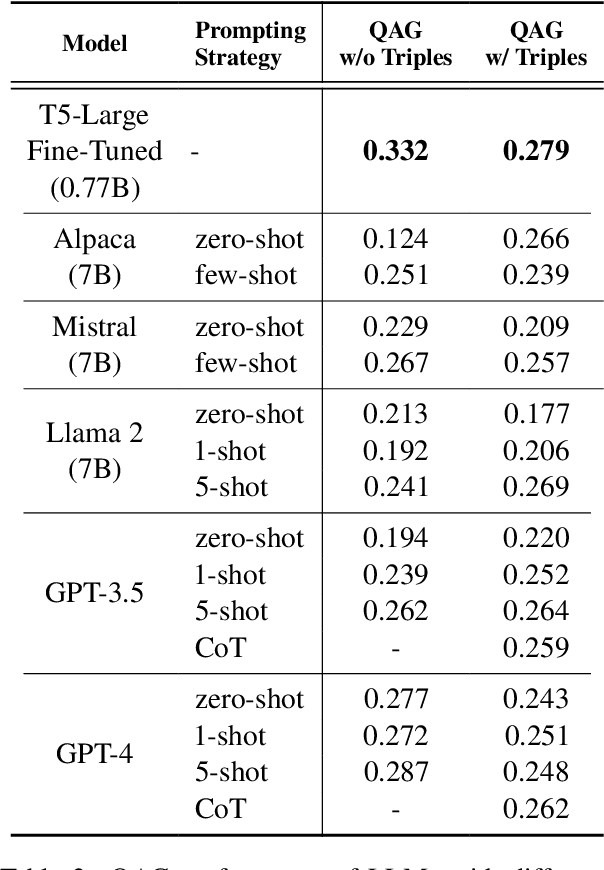
AI models (including LLM) often rely on narrative question-answering (QA) datasets to provide customized QA functionalities to support downstream children education applications; however, existing datasets only include QA pairs that are grounded within the given storybook content, but children can learn more when teachers refer the storybook content to real-world knowledge (e.g., commonsense knowledge). We introduce the FairytaleCQA dataset, which is annotated by children education experts, to supplement 278 storybook narratives with educationally appropriate commonsense knowledge. The dataset has 5,868 QA pairs that not only originate from the storybook narrative but also contain the commonsense knowledge grounded by an external knowledge graph (i.e., ConceptNet). A follow-up experiment shows that a smaller model (T5-large) fine-tuned with FairytaleCQA reliably outperforms much larger prompt-engineered LLM (e.g., GPT-4) in this new QA-pair generation task (QAG). This result suggests that: 1) our dataset brings novel challenges to existing LLMs, and 2) human experts' data annotation are still critical as they have much nuanced knowledge that LLMs do not know in the children educational domain.