 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Enhance the Performance of Semantic Search in Bengali using Neural Net and other Classification Techniques
Paper and Code
Nov 04, 2019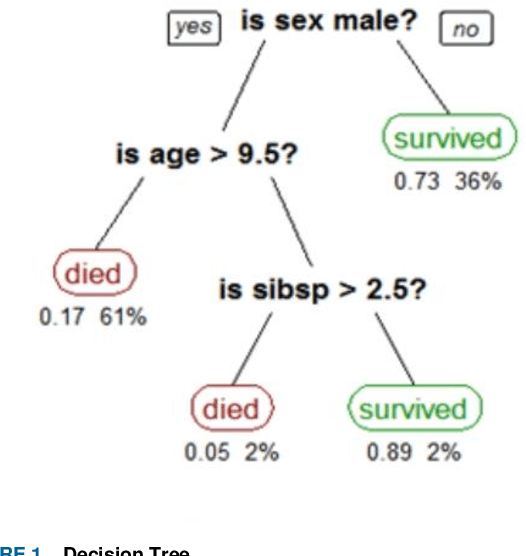
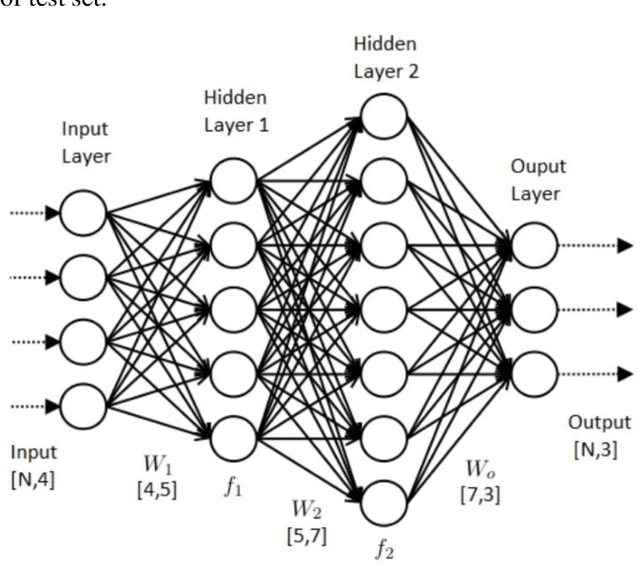

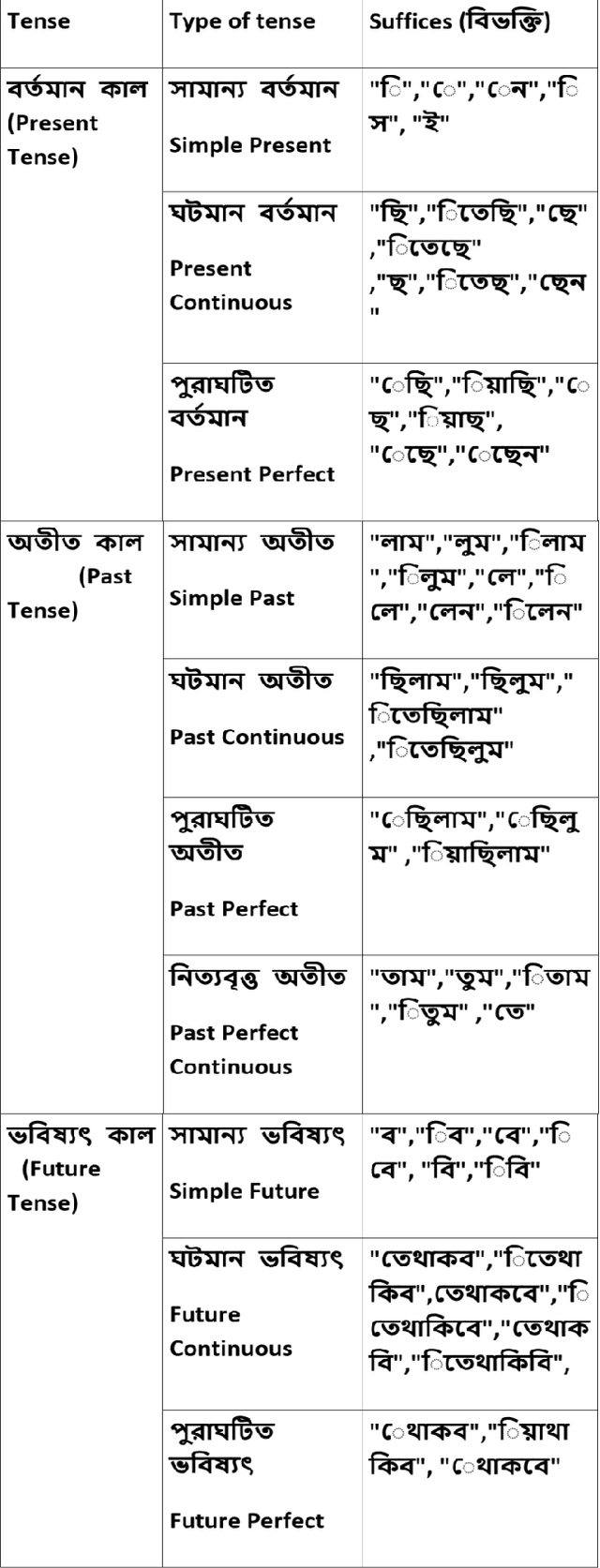
Search has for a long time been an important tool for users to retrieve information. Syntactic search is matching documents or objects containing specific keywords like user-history, location, preference etc. to improve the results. However, it is often possible that the query and the best answer have no term or very less number of terms in common and syntactic search can not perform properly in such cases. Semantic search, on the other hand, resolves these issues but suffers from lack of annotation, absence of WordNet in case of low resource languages. In this work, we have demonstrated an end to end procedure to improve the performance of semantic search using semi-supervised and unsupervised learning algorithms. An available Bengali repository was chosen to have seven types of semantic properties primarily to develop the system. Performance has been tested using Support Vector Machine, Naive Bayes, Decision Tree and Artificial Neural Network (ANN). Our system has achieved the efficiency to predict the correct semantics using knowledge base over the time of learning. A repository containing around a million sentences, a product of TDIL project of Govt. of India, was used to test our system at first instance. Then the testing has been done for other languages. Being a cognitive system it may be very useful for improving user satisfaction in e-Governance or m-Governance in the multilingual environment and also for other applications.