 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Video Captioning: A Survey of Techniques, Datasets and Evaluation Protocols
Nov 05, 2023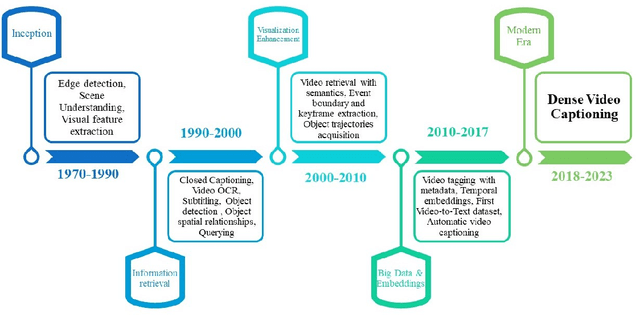
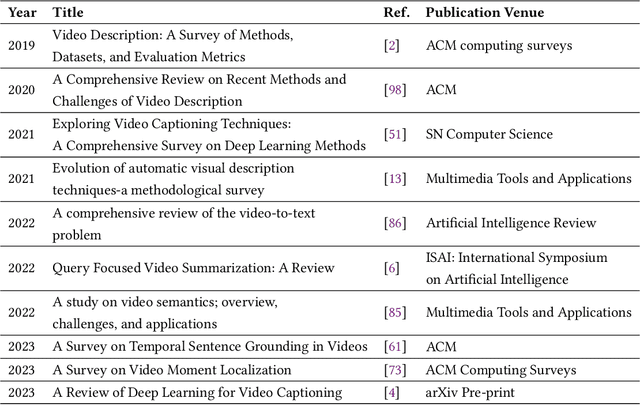
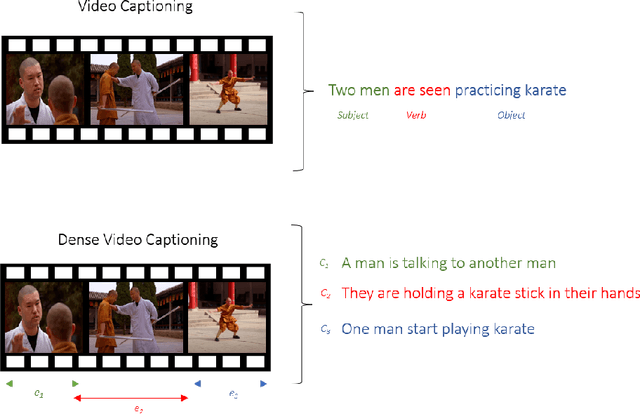

Untrimmed videos have interrelated events, dependencies, context, overlapping events, object-object interactions, domain specificity, and other semantics that are worth highlighting while describing a video in natural language. Owing to such a vast diversity, a single sentence can only correctly describe a portion of the video. Dense Video Captioning (DVC) aims at detecting and describing different events in a given video. The term DVC originated in the 2017 ActivityNet challenge, after which considerable effort has been made to address the challenge. Dense Video Captioning is divided into three sub-tasks: (1) Video Feature Extraction (VFE), (2) Temporal Event Localization (TEL), and (3) Dense Caption Generation (DCG). This review aims to discuss all the studies that claim to perform DVC along with its sub-tasks and summarize their results. We also discuss all the datasets that have been used for DVC. Lastly, we highlight some emerging challenges and future trends in the field.