 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmunoFOMO: Are Language Models missing what oncologists see?
Jun 13, 2025Language models (LMs) capabilities have grown with a fast pace over the past decade leading researchers in various disciplines, such as biomedical research, to increasingly explore the utility of LMs in their day-to-day applications. Domain specific language models have already been in use for biomedical natural language processing (NLP) applications. Recently however, the interest has grown towards medical language models and their understanding capabilities. In this paper, we investigate the medical conceptual grounding of various language models against expert clinicians for identification of hallmarks of immunotherapy in breast cancer abstracts. Our results show that pre-trained language models have potential to outperform large language models in identifying very specific (low-level) concepts.
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Jul 17, 2024

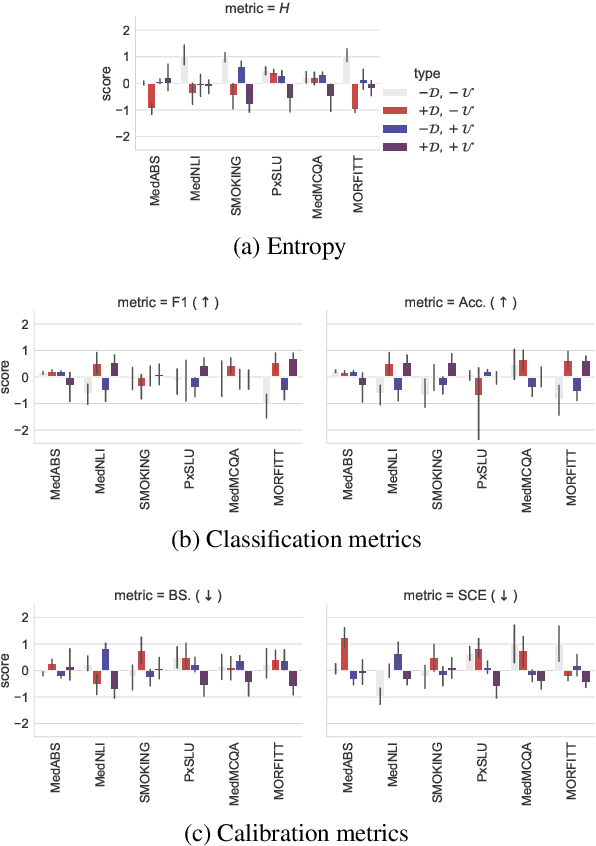
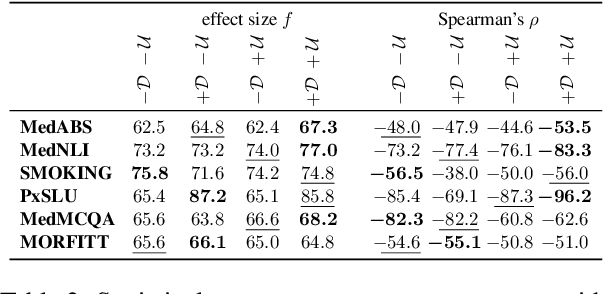
The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023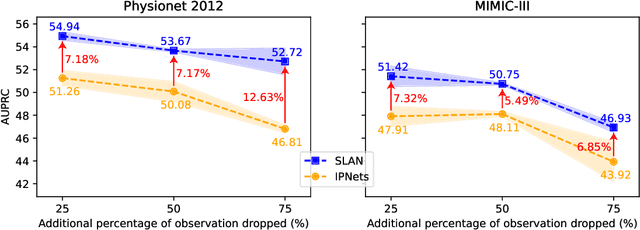
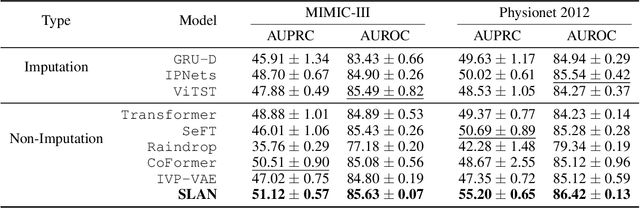
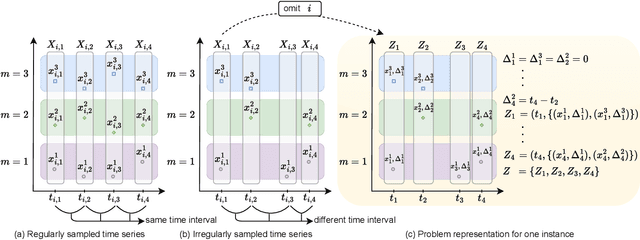
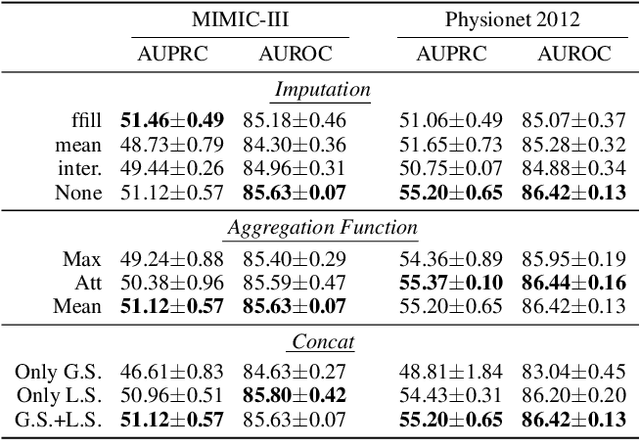
Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
Improving robustness of jet tagging algorithms with adversarial training
Mar 25, 2022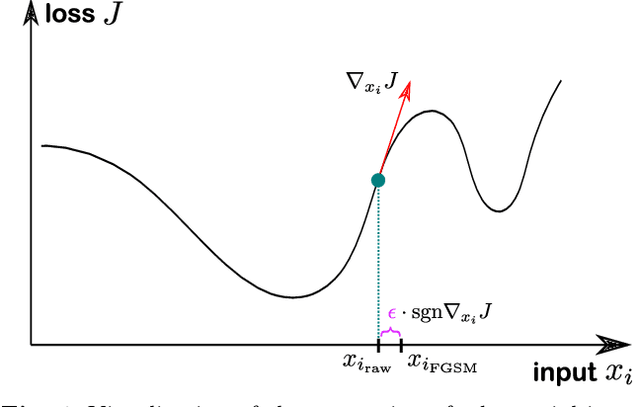

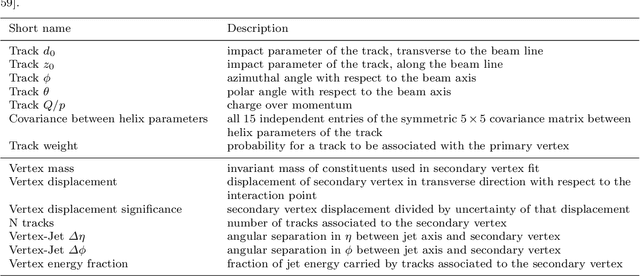
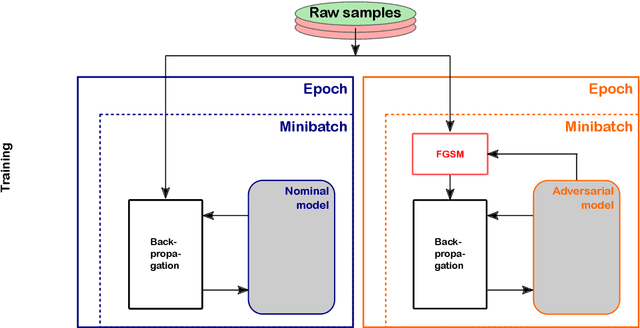
Deep learning is a standard tool in the field of high-energy physics, facilitating considerable sensitivity enhancements for numerous analysis strategies. In particular, in identification of physics objects, such as jet flavor tagging, complex neural network architectures play a major role. However, these methods are reliant on accurate simulations. Mismodeling can lead to non-negligible differences in performance in data that need to be measured and calibrated against. We investigate the classifier response to input data with injected mismodelings and probe the vulnerability of flavor tagging algorithms via application of adversarial attacks. Subsequently, we present an adversarial training strategy that mitigates the impact of such simulated attacks and improves the classifier robustness. We examine the relationship between performance and vulnerability and show that this method constitutes a promising approach to reduce the vulnerability to poor modeling.