Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Game Interface to Study Semantic Grounding in Text-Based Models
Paper and Code
Aug 17, 2021
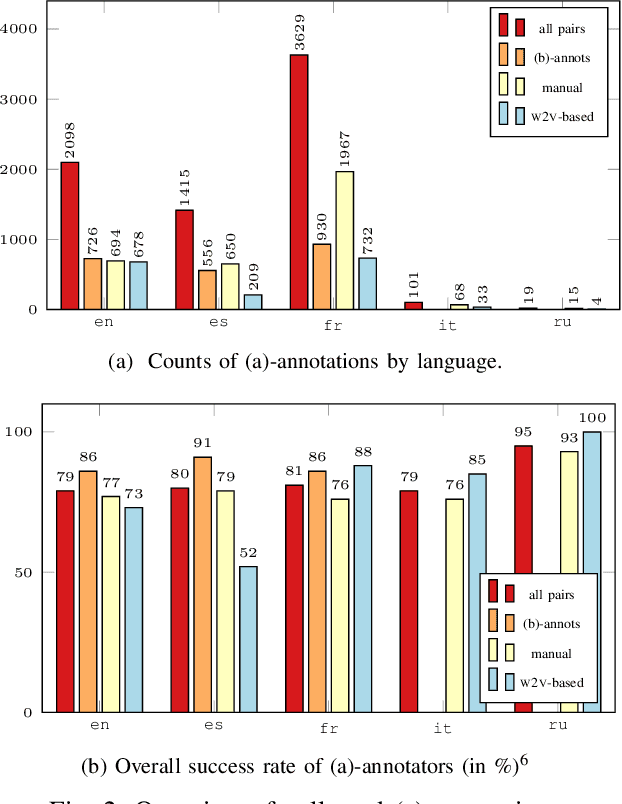
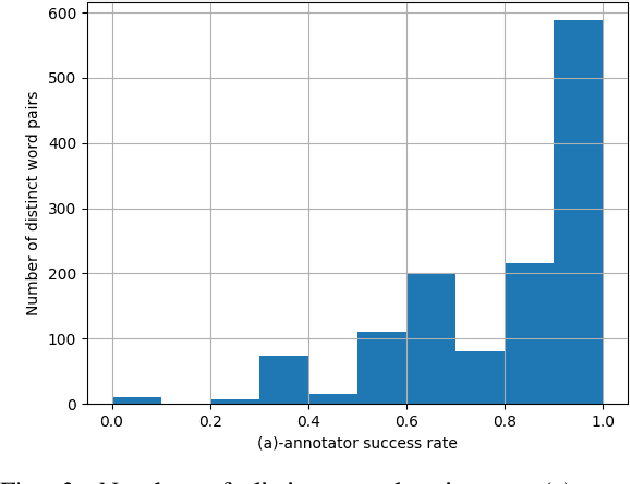
Can language models learn grounded representations from text distribution alone? This question is both central and recurrent in natural language processing; authors generally agree that grounding requires more than textual distribution. We propose to experimentally test this claim: if any two words have different meanings and yet cannot be distinguished from distribution alone, then grounding is out of the reach of text-based models. To that end, we present early work on an online game for the collection of human judgments on the distributional similarity of word pairs in five languages. We further report early results of our data collection campaign.
View paper on