 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating image captions with external encyclopedic knowledge
Oct 10, 2022


Accurately reporting what objects are depicted in an image is largely a solved problem in automatic caption generation. The next big challenge on the way to truly humanlike captioning is being able to incorporate the context of the image and related real world knowledge. We tackle this challenge by creating an end-to-end caption generation system that makes extensive use of image-specific encyclopedic data. Our approach includes a novel way of using image location to identify relevant open-domain facts in an external knowledge base, with their subsequent integration into the captioning pipeline at both the encoding and decoding stages. Our system is trained and tested on a new dataset with naturally produced knowledge-rich captions, and achieves significant improvements over multiple baselines. We empirically demonstrate that our approach is effective for generating contextualized captions with encyclopedic knowledge that is both factually accurate and relevant to the image.
Constructive Type-Logical Supertagging with Self-Attention Networks
May 31, 2019
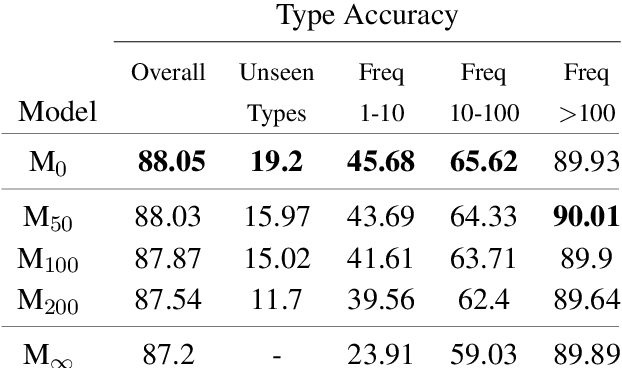
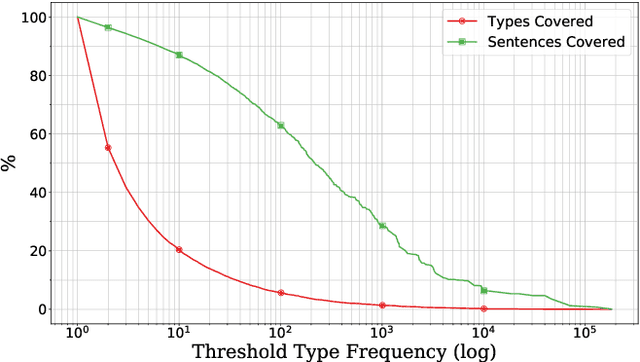
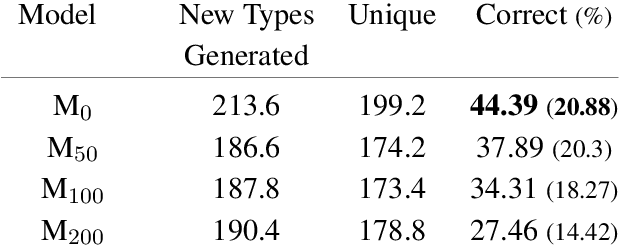
We propose a novel application of self-attention networks towards grammar induction. We present an attention-based supertagger for a refined type-logical grammar, trained on constructing types inductively. In addition to achieving a high overall type accuracy, our model is able to learn the syntax of the grammar's type system along with its denotational semantics. This lifts the closed world assumption commonly made by lexicalized grammar supertaggers, greatly enhancing its generalization potential. This is evidenced both by its adequate accuracy over sparse word types and its ability to correctly construct complex types never seen during training, which, to the best of our knowledge, was as of yet unaccomplished.