 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNominal Class Assignment in Swahili: A Computational Account
Oct 16, 2024



We discuss the open question of the relation between semantics and nominal class assignment in Swahili. We approach the problem from a computational perspective, aiming first to quantify the extent of this relation, and then to explicate its nature, taking extra care to suppress morphosyntactic confounds. Our results are the first of their kind, providing a quantitative evaluation of the semantic cohesion of each nominal class, as well as a nuanced taxonomic description of its semantic content.
On Tables with Numbers, with Numbers
Aug 14, 2024



This paper is a critical reflection on the epistemic culture of contemporary computational linguistics, framed in the context of its growing obsession with tables with numbers. We argue against tables with numbers on the basis of their epistemic irrelevance, their environmental impact, their role in enabling and exacerbating social inequalities, and their deep ties to commercial applications and profit-driven research. We substantiate our arguments with empirical evidence drawn from a meta-analysis of computational linguistics research over the last decade.
Learning Structure-Aware Representations of Dependent Types
Feb 03, 2024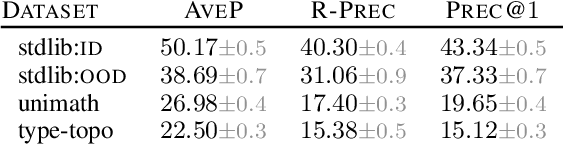
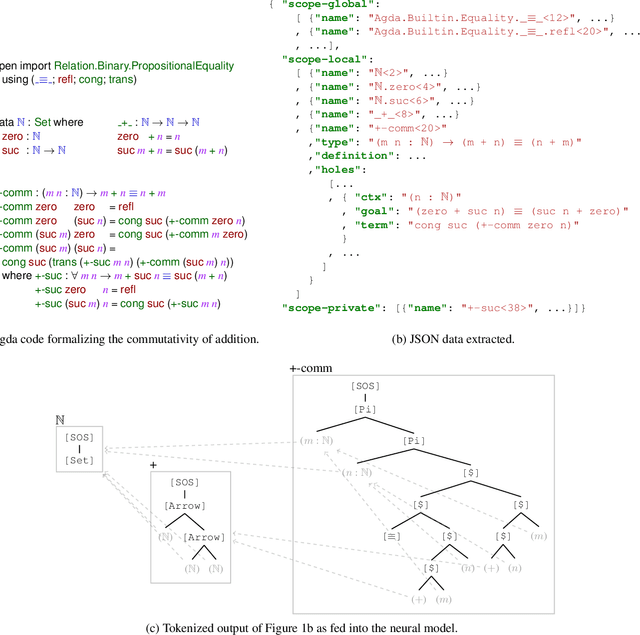

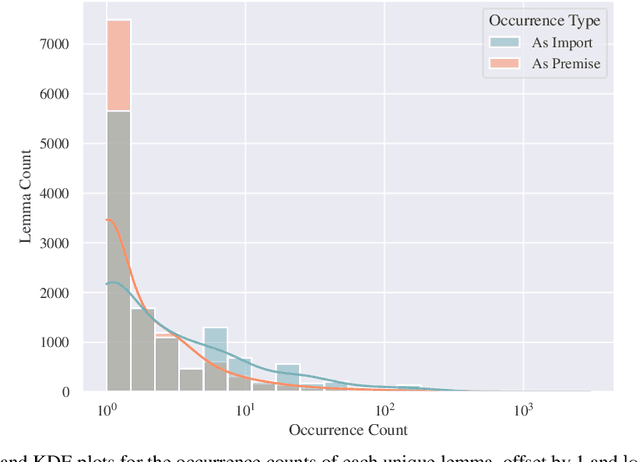
Agda is a dependently-typed programming language and a proof assistant, pivotal in proof formalization and programming language theory. This paper extends the Agda ecosystem into machine learning territory, and, vice versa, makes Agda-related resources available to machine learning practitioners. We introduce and release a novel dataset of Agda program-proofs that is elaborate and extensive enough to support various machine learning applications -- the first of its kind. Leveraging the dataset's ultra-high resolution, detailing proof states at the sub-type level, we propose a novel neural architecture targeted at faithfully representing dependently-typed programs on the basis of structural rather than nominal principles. We instantiate and evaluate our architecture in a premise selection setup, where it achieves strong initial results.
Algebraic Positional Encodings
Dec 26, 2023

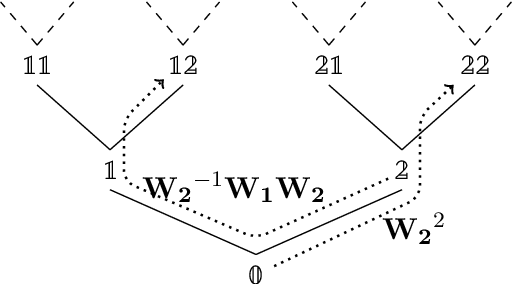

We introduce a novel positional encoding strategy for Transformer-style models, addressing the shortcomings of existing, often ad hoc, approaches. Our framework provides a flexible mapping from the algebraic specification of a domain to an interpretation as orthogonal operators. This design preserves the algebraic characteristics of the source domain, ensuring that the model upholds the desired structural properties. Our scheme can accommodate various structures, including sequences, grids and trees, as well as their compositions. We conduct a series of experiments to demonstrate the practical applicability of our approach. Results suggest performance on par with or surpassing the current state-of-the-art, without hyperparameter optimizations or ``task search'' of any kind. Code will be made available at \url{github.com/konstantinosKokos/UnitaryPE}.
OYXOY: A Modern NLP Test Suite for Modern Greek
Sep 13, 2023



This paper serves as a foundational step towards the development of a linguistically motivated and technically relevant evaluation suite for Greek NLP. We initiate this endeavor by introducing four expert-verified evaluation tasks, specifically targeted at natural language inference, word sense disambiguation (through example comparison or sense selection) and metaphor detection. More than language-adapted replicas of existing tasks, we contribute two innovations which will resonate with the broader resource and evaluation community. Firstly, our inference dataset is the first of its kind, marking not just \textit{one}, but rather \textit{all} possible inference labels, accounting for possible shifts due to e.g. ambiguity or polysemy. Secondly, we demonstrate a cost-efficient method to obtain datasets for under-resourced languages. Using ChatGPT as a language-neutral parser, we transform the Dictionary of Standard Modern Greek into a structured format, from which we derive the other three tasks through simple projections. Alongside each task, we conduct experiments using currently available state of the art machinery. Our experimental baselines affirm the challenging nature of our tasks and highlight the need for expedited progress in order for the Greek NLP ecosystem to keep pace with contemporary mainstream research.
SPINDLE: Spinning Raw Text into Lambda Terms with Graph Attention
Feb 23, 2023



This paper describes SPINDLE - an open source Python module implementing an efficient and accurate parser for written Dutch that transforms raw text input to programs for meaning composition, expressed as {\lambda} terms. The parser integrates a number of breakthrough advances made in recent years. Its output consists of hi-res derivations of a multimodal type-logical grammar, capturing two orthogonal axes of syntax, namely deep function-argument structures and dependency relations. These are produced by three interdependent systems: a static type-checker asserting the well-formedness of grammatical analyses, a state-of-the-art, structurally-aware supertagger based on heterogeneous graph convolutions, and a massively parallel proof search component based on Sinkhorn iterations. Packed in the software are also handy utilities and extras for proof visualization and inference, intended to facilitate end-user utilization.
Geometry-Aware Supertagging with Heterogeneous Dynamic Convolutions
Mar 23, 2022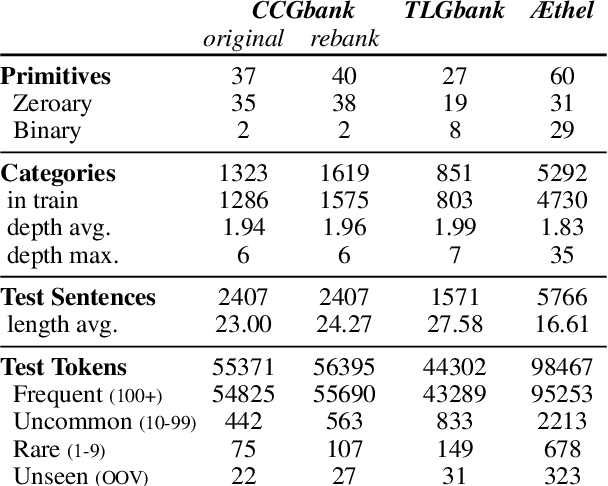
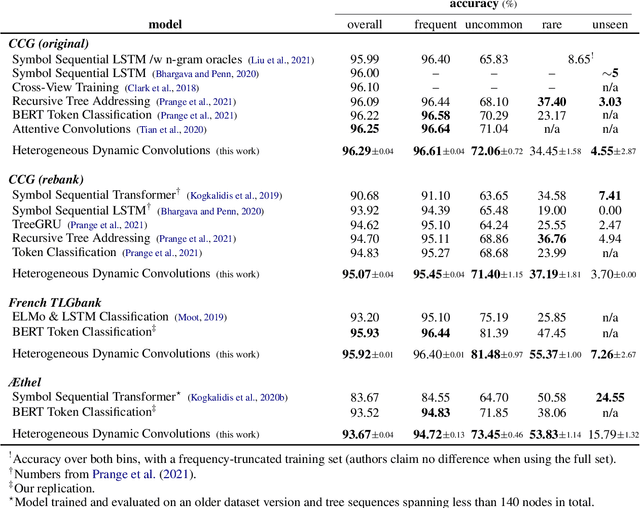
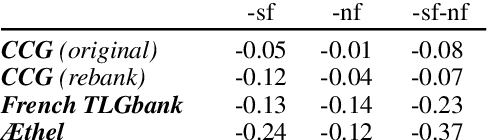
The syntactic categories of categorial grammar formalisms are structured units made of smaller, indivisible primitives, bound together by the underlying grammar's category formation rules. In the trending approach of constructive supertagging, neural models are increasingly made aware of the internal category structure, which in turn enables them to more reliably predict rare and out-of-vocabulary categories, with significant implications for grammars previously deemed too complex to find practical use. In this work, we revisit constructive supertagging from a graph-theoretic perspective, and propose a framework based on heterogeneous dynamic graph convolutions aimed at exploiting the distinctive structure of a supertagger's output space. We test our approach on a number of categorial grammar datasets spanning different languages and grammar formalisms, achieving substantial improvements over previous state of the art scores. Code will be made available at https://github.com/konstantinosKokos/dynamic-graph-supertagging
Discontinuous Constituency and BERT: A Case Study of Dutch
Mar 08, 2022
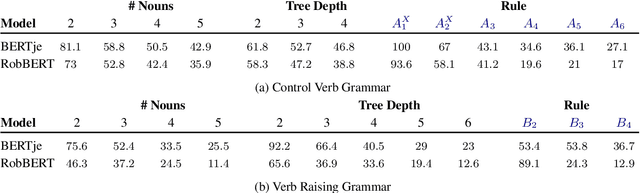
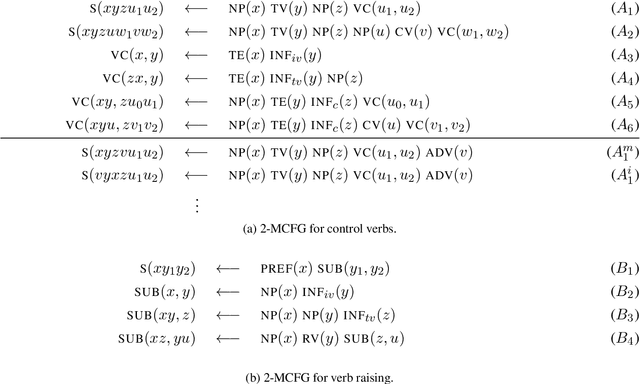
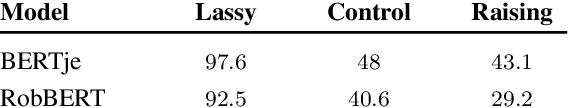
In this paper, we set out to quantify the syntactic capacity of BERT in the evaluation regime of non-context free patterns, as occurring in Dutch. We devise a test suite based on a mildly context-sensitive formalism, from which we derive grammars that capture the linguistic phenomena of control verb nesting and verb raising. The grammars, paired with a small lexicon, provide us with a large collection of naturalistic utterances, annotated with verb-subject pairings, that serve as the evaluation test bed for an attention-based span selection probe. Our results, backed by extensive analysis, suggest that the models investigated fail in the implicit acquisition of the dependencies examined.
A Logic-Based Framework for Natural Language Inference in Dutch
Oct 08, 2021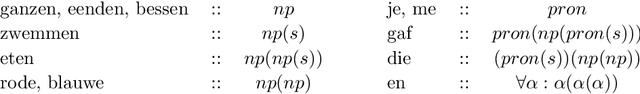
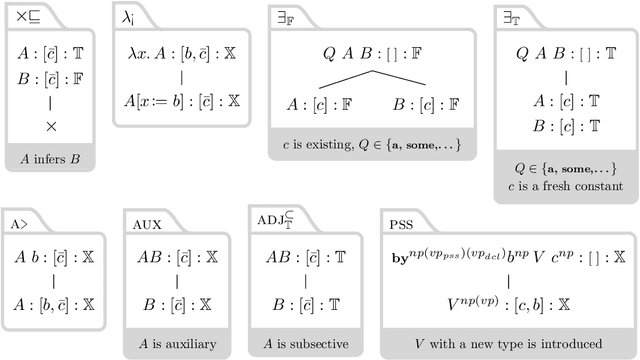
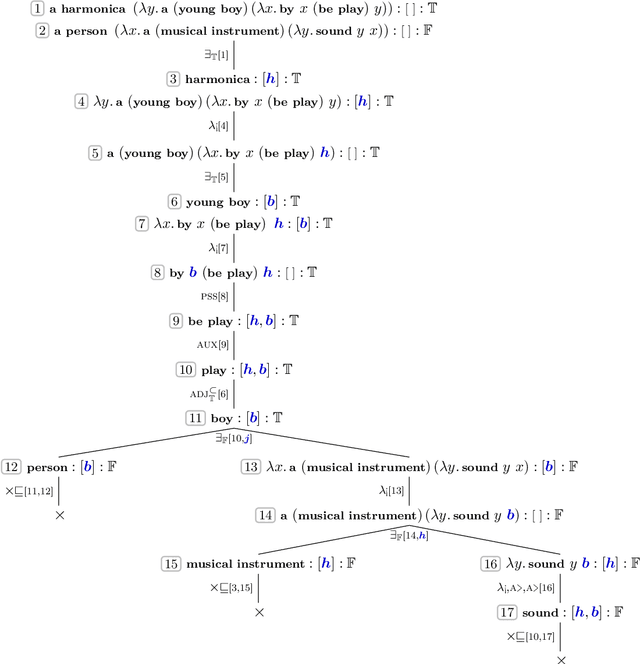
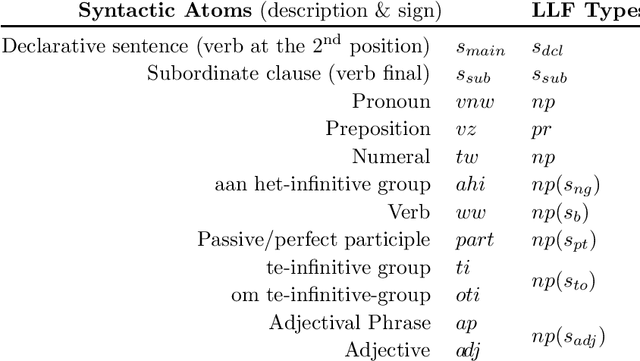
We present a framework for deriving inference relations between Dutch sentence pairs. The proposed framework relies on logic-based reasoning to produce inspectable proofs leading up to inference labels; its judgements are therefore transparent and formally verifiable. At its core, the system is powered by two ${\lambda}$-calculi, used as syntactic and semantic theories, respectively. Sentences are first converted to syntactic proofs and terms of the linear ${\lambda}$-calculus using a choice of two parsers: an Alpino-based pipeline, and Neural Proof Nets. The syntactic terms are then converted to semantic terms of the simply typed ${\lambda}$-calculus, via a set of hand designed type- and term-level transformations. Pairs of semantic terms are then fed to an automated theorem prover for natural logic which reasons with them while using lexical relations found in the Open Dutch WordNet. We evaluate the reasoning pipeline on the recently created Dutch natural language inference dataset, and achieve promising results, remaining only within a $1.1-3.2{\%}$ performance margin to strong neural baselines. To the best of our knowledge, the reasoning pipeline is the first logic-based system for Dutch.
Improving BERT Pretraining with Syntactic Supervision
Apr 21, 2021Bidirectional masked Transformers have become the core theme in the current NLP landscape. Despite their impressive benchmarks, a recurring theme in recent research has been to question such models' capacity for syntactic generalization. In this work, we seek to address this question by adding a supervised, token-level supertagging objective to standard unsupervised pretraining, enabling the explicit incorporation of syntactic biases into the network's training dynamics. Our approach is straightforward to implement, induces a marginal computational overhead and is general enough to adapt to a variety of settings. We apply our methodology on Lassy Large, an automatically annotated corpus of written Dutch. Our experiments suggest that our syntax-aware model performs on par with established baselines, despite Lassy Large being one order of magnitude smaller than commonly used corpora.