 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Got Rhythm? Hybrid Phonological Filtering for Greek Poetry Rhyme Detection and Generation
Jan 14, 2026Large Language Models (LLMs), despite their remarkable capabilities across NLP tasks, struggle with phonologically-grounded phenomena like rhyme detection and generation. This is even more evident in lower-resource languages such as Modern Greek. In this paper, we present a hybrid system that combines LLMs with deterministic phonological algorithms to achieve accurate rhyme identification/analysis and generation. Our approach implements a comprehensive taxonomy of Greek rhyme types, including Pure, Rich, Imperfect, Mosaic, and Identical Pre-rhyme Vowel (IDV) patterns, and employs an agentic generation pipeline with phonological verification. We evaluate multiple prompting strategies (zero-shot, few-shot, Chain-of-Thought, and RAG-augmented) across several LLMs including Claude 3.7 and 4.5, GPT-4o, Gemini 2.0 and open-weight models like Llama 3.1 8B and 70B and Mistral Large. Results reveal a significant "Reasoning Gap": while native-like models (Claude 3.7) perform intuitively (40\% accuracy in identification), reasoning-heavy models (Claude 4.5) achieve state-of-the-art performance (54\%) only when prompted with Chain-of-Thought. Most critically, pure LLM generation fails catastrophically (under 4\% valid poems), while our hybrid verification loop restores performance to 73.1\%. We release our system and a crucial, rigorously cleaned corpus of 40,000+ rhymes, derived from the Anemoskala and Interwar Poetry corpora, to support future research.
Reverse-engineering NLI: A study of the meta-inferential properties of Natural Language Inference
Jan 08, 2026Natural Language Inference (NLI) has been an important task for evaluating language models for Natural Language Understanding, but the logical properties of the task are poorly understood and often mischaracterized. Understanding the notion of inference captured by NLI is key to interpreting model performance on the task. In this paper we formulate three possible readings of the NLI label set and perform a comprehensive analysis of the meta-inferential properties they entail. Focusing on the SNLI dataset, we exploit (1) NLI items with shared premises and (2) items generated by LLMs to evaluate models trained on SNLI for meta-inferential consistency and derive insights into which reading of the logical relations is encoded by the dataset.
GRDD+: An Extended Greek Dialectal Dataset with Cross-Architecture Fine-tuning Evaluation
Nov 08, 2025

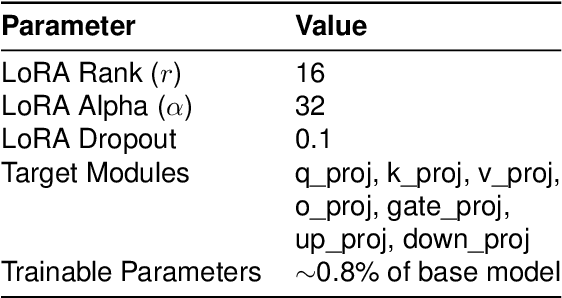

We present an extended Greek Dialectal Dataset (GRDD+) 1that complements the existing GRDD dataset with more data from Cretan, Cypriot, Pontic and Northern Greek, while we add six new varieties: Greco-Corsican, Griko (Southern Italian Greek), Maniot, Heptanesian, Tsakonian, and Katharevusa Greek. The result is a dataset with total size 6,374,939 words and 10 varieties. This is the first dataset with such variation and size to date. We conduct a number of fine-tuning experiments to see the effect of good quality dialectal data on a number of LLMs. We fine-tune three model architectures (Llama-3-8B, Llama-3.1-8B, Krikri-8B) and compare the results to frontier models (Claude-3.7-Sonnet, Gemini-2.5, ChatGPT-5).
Reasoning with RAGged events: RAG-Enhanced Event Knowledge Base Construction and reasoning with proof-assistants
Jun 08, 2025Extracting structured computational representations of historical events from narrative text remains computationally expensive when constructed manually. While RDF/OWL reasoners enable graph-based reasoning, they are limited to fragments of first-order logic, preventing deeper temporal and semantic analysis. This paper addresses both challenges by developing automatic historical event extraction models using multiple LLMs (GPT-4, Claude, Llama 3.2) with three enhancement strategies: pure base generation, knowledge graph enhancement, and Retrieval-Augmented Generation (RAG). We conducted comprehensive evaluations using historical texts from Thucydides. Our findings reveal that enhancement strategies optimize different performance dimensions rather than providing universal improvements. For coverage and historical breadth, base generation achieves optimal performance with Claude and GPT-4 extracting comprehensive events. However, for precision, RAG enhancement improves coordinate accuracy and metadata completeness. Model architecture fundamentally determines enhancement sensitivity: larger models demonstrate robust baseline performance with incremental RAG improvements, while Llama 3.2 shows extreme variance from competitive performance to complete failure. We then developed an automated translation pipeline converting extracted RDF representations into Coq proof assistant specifications, enabling higher-order reasoning beyond RDF capabilities including multi-step causal verification, temporal arithmetic with BC dates, and formal proofs about historical causation. The Coq formalization validates that RAG-discovered event types represent legitimate domain-specific semantic structures rather than ontological violations.
On Tables with Numbers, with Numbers
Aug 14, 2024



This paper is a critical reflection on the epistemic culture of contemporary computational linguistics, framed in the context of its growing obsession with tables with numbers. We argue against tables with numbers on the basis of their epistemic irrelevance, their environmental impact, their role in enabling and exacerbating social inequalities, and their deep ties to commercial applications and profit-driven research. We substantiate our arguments with empirical evidence drawn from a meta-analysis of computational linguistics research over the last decade.
OYXOY: A Modern NLP Test Suite for Modern Greek
Sep 13, 2023



This paper serves as a foundational step towards the development of a linguistically motivated and technically relevant evaluation suite for Greek NLP. We initiate this endeavor by introducing four expert-verified evaluation tasks, specifically targeted at natural language inference, word sense disambiguation (through example comparison or sense selection) and metaphor detection. More than language-adapted replicas of existing tasks, we contribute two innovations which will resonate with the broader resource and evaluation community. Firstly, our inference dataset is the first of its kind, marking not just \textit{one}, but rather \textit{all} possible inference labels, accounting for possible shifts due to e.g. ambiguity or polysemy. Secondly, we demonstrate a cost-efficient method to obtain datasets for under-resourced languages. Using ChatGPT as a language-neutral parser, we transform the Dictionary of Standard Modern Greek into a structured format, from which we derive the other three tasks through simple projections. Alongside each task, we conduct experiments using currently available state of the art machinery. Our experimental baselines affirm the challenging nature of our tasks and highlight the need for expedited progress in order for the Greek NLP ecosystem to keep pace with contemporary mainstream research.
GRDD: A Dataset for Greek Dialectal NLP
Aug 01, 2023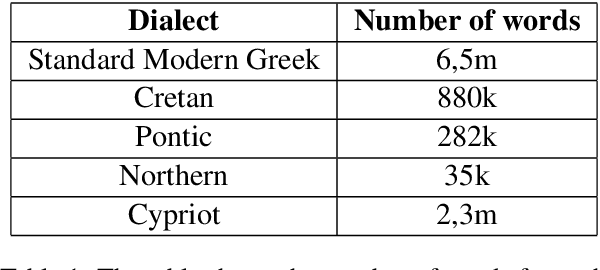
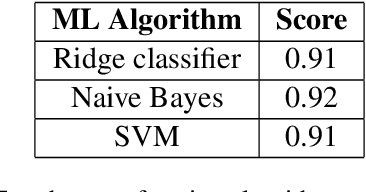
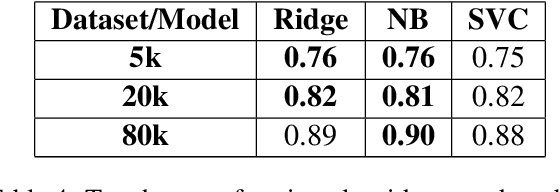
In this paper, we present a dataset for the computational study of a number of Modern Greek dialects. It consists of raw text data from four dialects of Modern Greek, Cretan, Pontic, Northern Greek and Cypriot Greek. The dataset is of considerable size, albeit imbalanced, and presents the first attempt to create large scale dialectal resources of this type for Modern Greek dialects. We then use the dataset to perform dialect idefntification. We experiment with traditional ML algorithms, as well as simple DL architectures. The results show very good performance on the task, potentially revealing that the dialects in question have distinct enough characteristics allowing even simple ML models to perform well on the task. Error analysis is performed for the top performing algorithms showing that in a number of cases the errors are due to insufficient dataset cleaning.
How Does Data Corruption Affect Natural Language Understanding Models? A Study on GLUE datasets
Jan 12, 2022
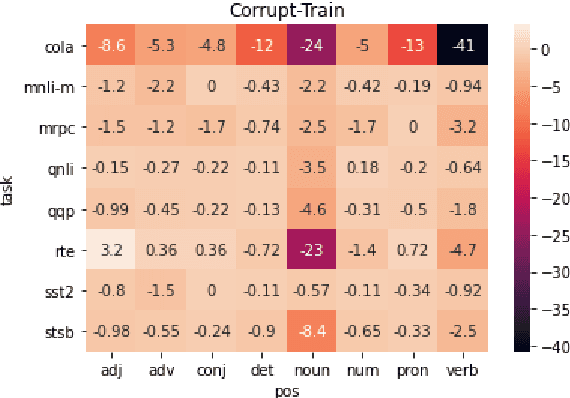

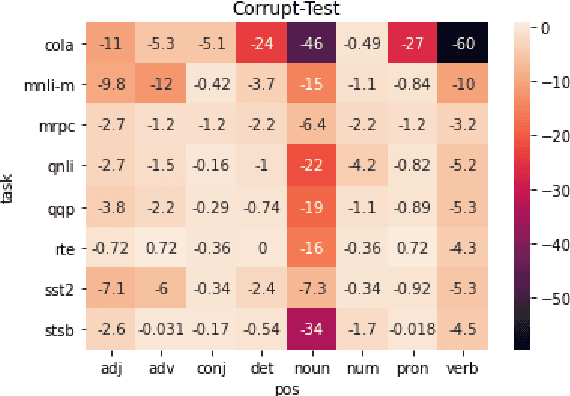
A central question in natural language understanding (NLU) research is whether high performance demonstrates the models' strong reasoning capabilities. We present an extensive series of controlled experiments where pre-trained language models are exposed to data that have undergone specific corruption transformations. The transformations involve removing instances of specific word classes and often lead to non-sensical sentences. Our results show that performance remains high for most GLUE tasks when the models are fine-tuned or tested on corrupted data, suggesting that the models leverage other cues for prediction even in non-sensical contexts. Our proposed data transformations can be used as a diagnostic tool for assessing the extent to which a specific dataset constitutes a proper testbed for evaluating models' language understanding capabilities.
NLI Data Sanity Check: Assessing the Effect of Data Corruption on Model Performance
Apr 10, 2021
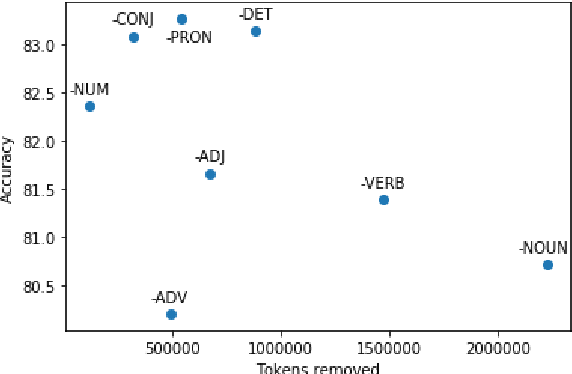

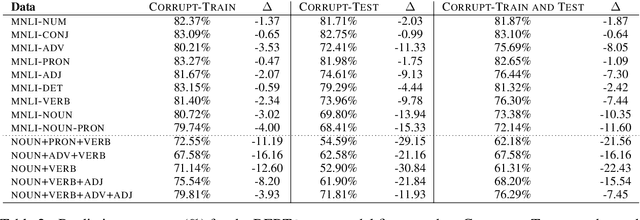
Pre-trained neural language models give high performance on natural language inference (NLI) tasks. But whether they actually understand the meaning of the processed sequences remains unclear. We propose a new diagnostics test suite which allows to assess whether a dataset constitutes a good testbed for evaluating the models' meaning understanding capabilities. We specifically apply controlled corruption transformations to widely used benchmarks (MNLI and ANLI), which involve removing entire word classes and often lead to non-sensical sentence pairs. If model accuracy on the corrupted data remains high, then the dataset is likely to contain statistical biases and artefacts that guide prediction. Inversely, a large decrease in model accuracy indicates that the original dataset provides a proper challenge to the models' reasoning capabilities. Hence, our proposed controls can serve as a crash test for developing high quality data for NLI tasks.
FraCaS: Temporal Analysis
Dec 19, 2020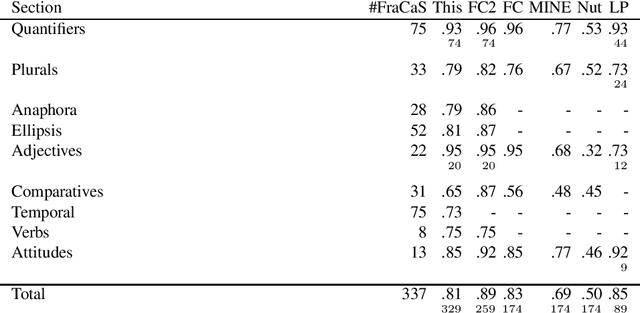
In this paper, we propose an implementation of temporal semantics which is suitable for inference problems. This implementation translates syntax trees to logical formulas, suitable for consumption by the Coq proof assistant. We support several phenomena including: temporal references, temporal adverbs, aspectual classes and progressives. We apply these semantics to the complete FraCaS testsuite. We obtain an accuracy of 81 percent overall and 73 percent for problems explicitly marked as related to temporal reference.