 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structure-Aware Representations of Dependent Types
Feb 03, 2024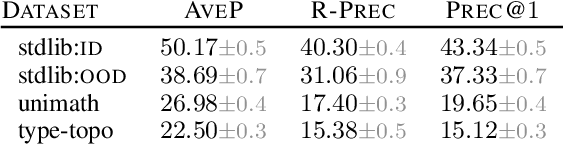
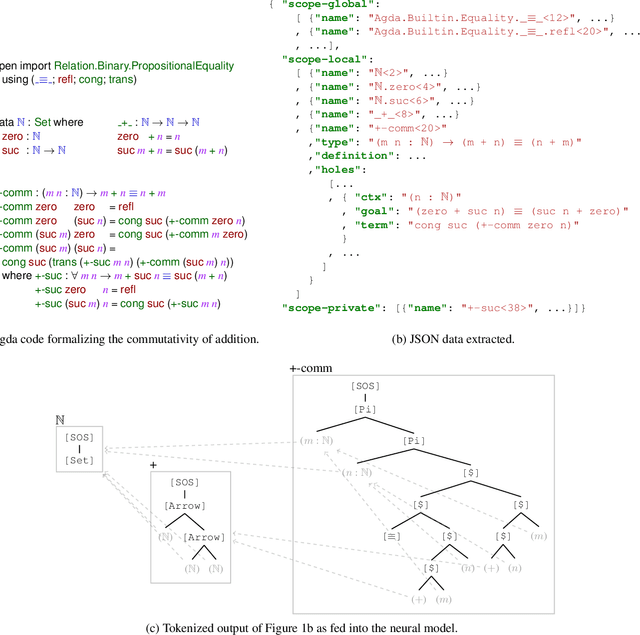

Agda is a dependently-typed programming language and a proof assistant, pivotal in proof formalization and programming language theory. This paper extends the Agda ecosystem into machine learning territory, and, vice versa, makes Agda-related resources available to machine learning practitioners. We introduce and release a novel dataset of Agda program-proofs that is elaborate and extensive enough to support various machine learning applications -- the first of its kind. Leveraging the dataset's ultra-high resolution, detailing proof states at the sub-type level, we propose a novel neural architecture targeted at faithfully representing dependently-typed programs on the basis of structural rather than nominal principles. We instantiate and evaluate our architecture in a premise selection setup, where it achieves strong initial results.
Algebraic Positional Encodings
Dec 26, 2023

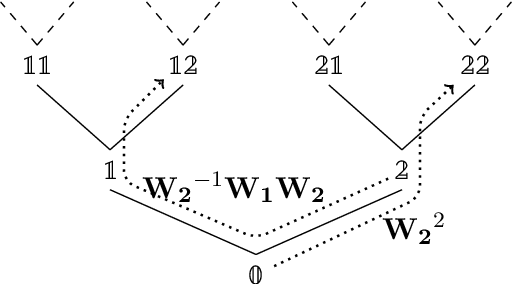

We introduce a novel positional encoding strategy for Transformer-style models, addressing the shortcomings of existing, often ad hoc, approaches. Our framework provides a flexible mapping from the algebraic specification of a domain to an interpretation as orthogonal operators. This design preserves the algebraic characteristics of the source domain, ensuring that the model upholds the desired structural properties. Our scheme can accommodate various structures, including sequences, grids and trees, as well as their compositions. We conduct a series of experiments to demonstrate the practical applicability of our approach. Results suggest performance on par with or surpassing the current state-of-the-art, without hyperparameter optimizations or ``task search'' of any kind. Code will be made available at \url{github.com/konstantinosKokos/UnitaryPE}.
Assessing the Unitary RNN as an End-to-End Compositional Model of Syntax
Aug 11, 2022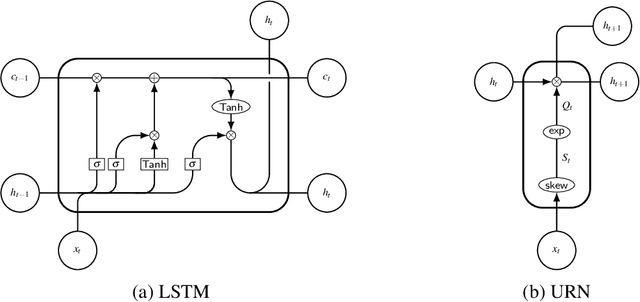

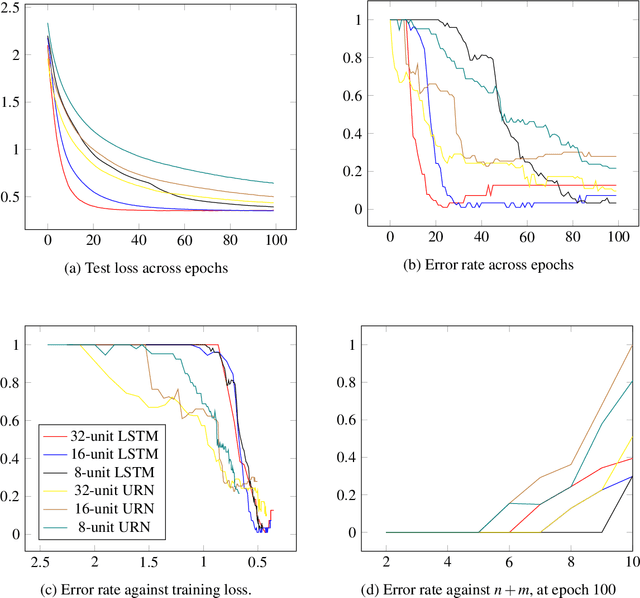

We show that both an LSTM and a unitary-evolution recurrent neural network (URN) can achieve encouraging accuracy on two types of syntactic patterns: context-free long distance agreement, and mildly context-sensitive cross serial dependencies. This work extends recent experiments on deeply nested context-free long distance dependencies, with similar results. URNs differ from LSTMs in that they avoid non-linear activation functions, and they apply matrix multiplication to word embeddings encoded as unitary matrices. This permits them to retain all information in the processing of an input string over arbitrary distances. It also causes them to satisfy strict compositionality. URNs constitute a significant advance in the search for explainable models in deep learning applied to NLP.
* In Proceedings E2ECOMPVEC, arXiv:2208.05313
UniMorph 4.0: Universal Morphology
May 10, 2022

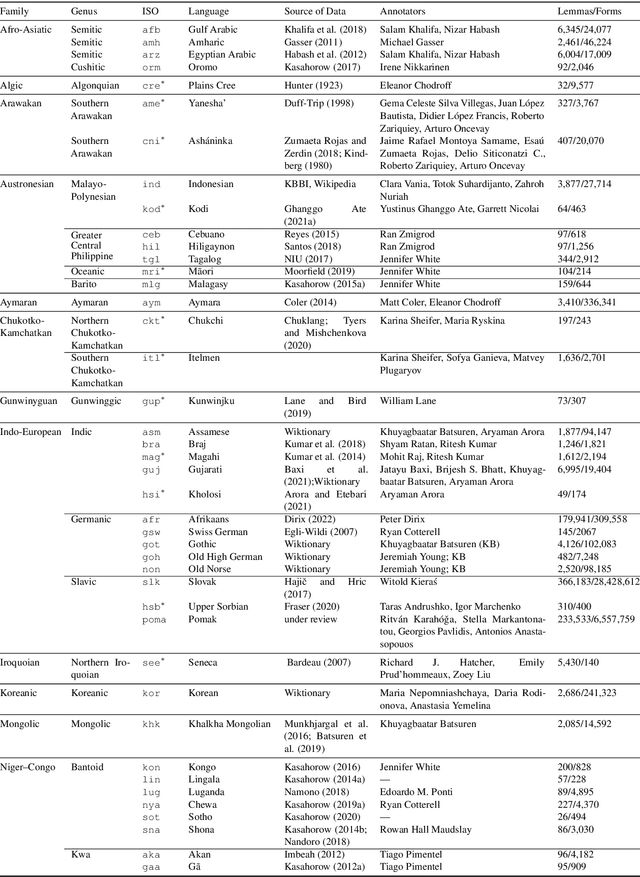
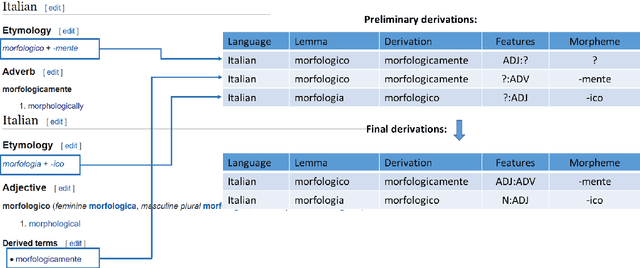
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
FraCaS: Temporal Analysis
Dec 19, 2020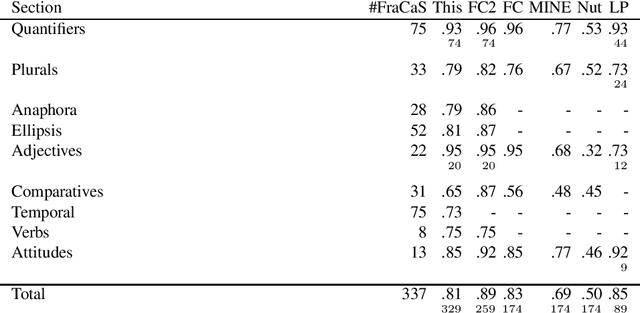
In this paper, we propose an implementation of temporal semantics which is suitable for inference problems. This implementation translates syntax trees to logical formulas, suitable for consumption by the Coq proof assistant. We support several phenomena including: temporal references, temporal adverbs, aspectual classes and progressives. We apply these semantics to the complete FraCaS testsuite. We obtain an accuracy of 81 percent overall and 73 percent for problems explicitly marked as related to temporal reference.
A corpus of precise natural textual entailment problems
Dec 14, 2018
In this paper, we present a new corpus of entailment problems. This corpus combines the following characteristics: 1. it is precise (does not leave out implicit hypotheses) 2. it is based on "real-world" texts (i.e. most of the premises were written for purposes other than testing textual entailment). 3. its size is 150. The corpus was constructed by taking problems from the Real Text Entailment and discovering missing hypotheses using a crowd of experts. We believe that this corpus constitutes a first step towards wide-coverage testing of precise natural-language inference systems.
Modelling prosodic structure using Artificial Neural Networks
Jun 15, 2017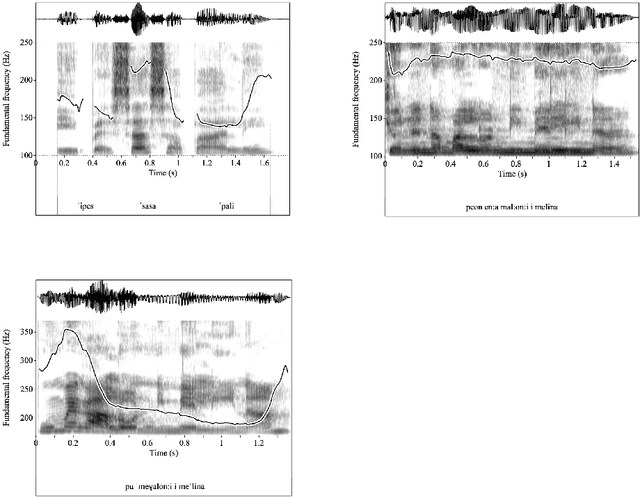
The ability to accurately perceive whether a speaker is asking a question or is making a statement is crucial for any successful interaction. However, learning and classifying tonal patterns has been a challenging task for automatic speech recognition and for models of tonal representation, as tonal contours are characterized by significant variation. This paper provides a classification model of Cypriot Greek questions and statements. We evaluate two state-of-the-art network architectures: a Long Short-Term Memory (LSTM) network and a convolutional network (ConvNet). The ConvNet outperforms the LSTM in the classification task and exhibited an excellent performance with 95% classification accuracy.