 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans vs Vision-Language Models: A Unified Measure of Narrative Coherence
Mar 26, 2026We study narrative coherence in visually grounded stories by comparing human-written narratives with those generated by vision-language models (VLMs) on the Visual Writing Prompts corpus. Using a set of metrics that capture different aspects of narrative coherence, including coreference, discourse relation types, topic continuity, character persistence, and multimodal character grounding, we compute a narrative coherence score. We find that VLMs show broadly similar coherence profiles that differ systematically from those of humans. In addition, differences for individual measures are often subtle, but they become clearer when considered jointly. Overall, our results indicate that, despite human-like surface fluency, model narratives exhibit systematic differences from those of humans in how they organise discourse across a visually grounded story. Our code is available at https://github.com/GU-CLASP/coherence-driven-humans.
Predicting Sentence Acceptability Judgments in Multimodal Contexts
Feb 24, 2026Previous work has examined the capacity of deep neural networks (DNNs), particularly transformers, to predict human sentence acceptability judgments, both independently of context, and in document contexts. We consider the effect of prior exposure to visual images (i.e., visual context) on these judgments for humans and large language models (LLMs). Our results suggest that, in contrast to textual context, visual images appear to have little if any impact on human acceptability ratings. However, LLMs display the compression effect seen in previous work on human judgments in document contexts. Different sorts of LLMs are able to predict human acceptability judgments to a high degree of accuracy, but in general, their performance is slightly better when visual contexts are removed. Moreover, the distribution of LLM judgments varies among models, with Qwen resembling human patterns, and others diverging from them. LLM-generated predictions on sentence acceptability are highly correlated with their normalised log probabilities in general. However, the correlations decrease when visual contexts are present, suggesting that a higher gap exists between the internal representations of LLMs and their generated predictions in the presence of visual contexts. Our experimental work suggests interesting points of similarity and of difference between human and LLM processing of sentences in multimodal contexts.
Coreference as an indicator of context scope in multimodal narrative
Mar 07, 2025We demonstrate that large multimodal language models differ substantially from humans in the distribution of coreferential expressions in a visual storytelling task. We introduce a number of metrics to quantify the characteristics of coreferential patterns in both human- and machine-written texts. Humans distribute coreferential expressions in a way that maintains consistency across texts and images, interleaving references to different entities in a highly varied way. Machines are less able to track mixed references, despite achieving perceived improvements in generation quality.
Assessing the Unitary RNN as an End-to-End Compositional Model of Syntax
Aug 11, 2022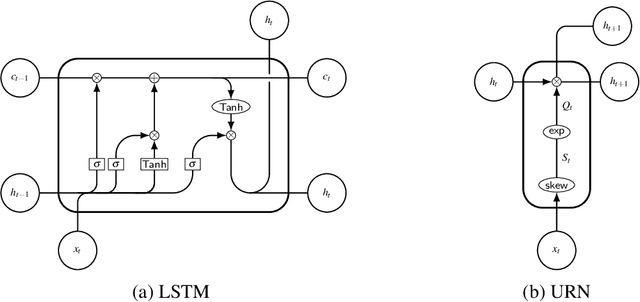

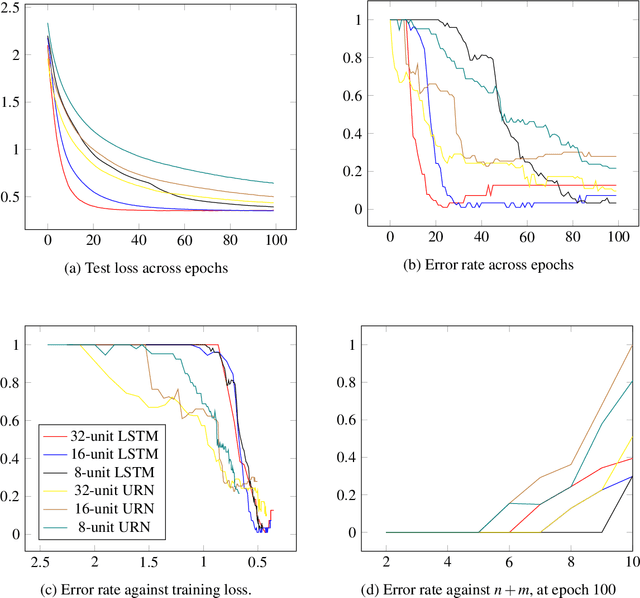

We show that both an LSTM and a unitary-evolution recurrent neural network (URN) can achieve encouraging accuracy on two types of syntactic patterns: context-free long distance agreement, and mildly context-sensitive cross serial dependencies. This work extends recent experiments on deeply nested context-free long distance dependencies, with similar results. URNs differ from LSTMs in that they avoid non-linear activation functions, and they apply matrix multiplication to word embeddings encoded as unitary matrices. This permits them to retain all information in the processing of an input string over arbitrary distances. It also causes them to satisfy strict compositionality. URNs constitute a significant advance in the search for explainable models in deep learning applied to NLP.
* In Proceedings E2ECOMPVEC, arXiv:2208.05313
How Furiously Can Colourless Green Ideas Sleep? Sentence Acceptability in Context
Apr 02, 2020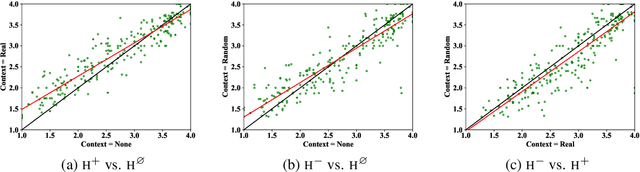
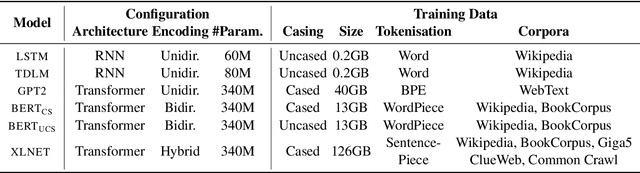

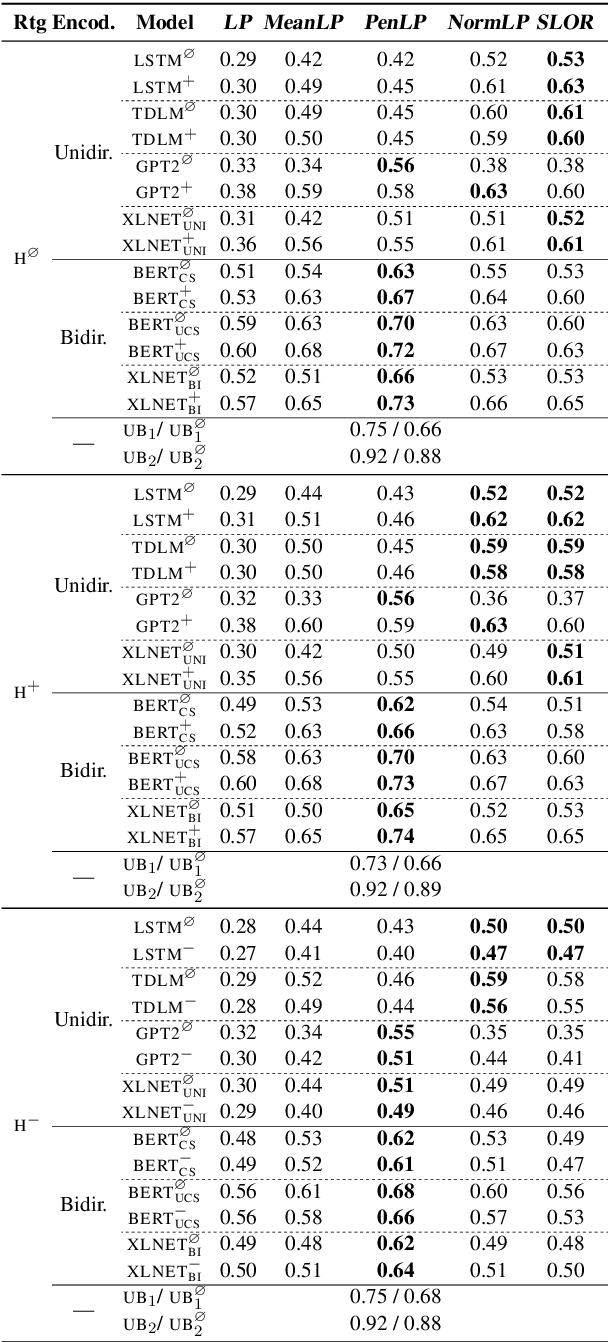
We study the influence of context on sentence acceptability. First we compare the acceptability ratings of sentences judged in isolation, with a relevant context, and with an irrelevant context. Our results show that context induces a cognitive load for humans, which compresses the distribution of ratings. Moreover, in relevant contexts we observe a discourse coherence effect which uniformly raises acceptability. Next, we test unidirectional and bidirectional language models in their ability to predict acceptability ratings. The bidirectional models show very promising results, with the best model achieving a new state-of-the-art for unsupervised acceptability prediction. The two sets of experiments provide insights into the cognitive aspects of sentence processing and central issues in the computational modelling of text and discourse.
The Effect of Context on Metaphor Paraphrase Aptness Judgments
Sep 04, 2018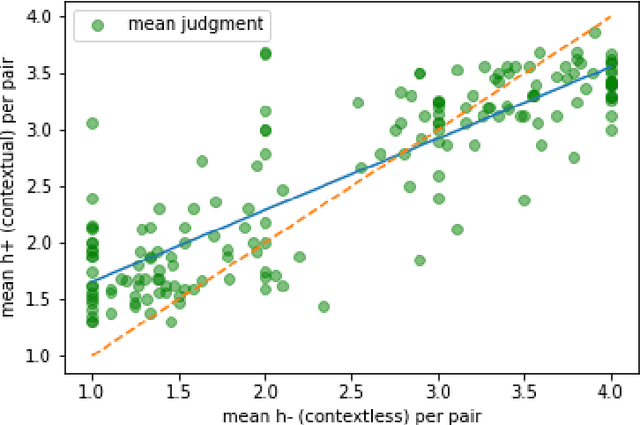



We conduct two experiments to study the effect of context on metaphor paraphrase aptness judgments. The first is an AMT crowd source task in which speakers rank metaphor paraphrase candidate sentence pairs in short document contexts for paraphrase aptness. In the second we train a composite DNN to predict these human judgments, first in binary classifier mode, and then as gradient ratings. We found that for both mean human judgments and our DNN's predictions, adding document context compresses the aptness scores towards the center of the scale, raising low out of context ratings and decreasing high out of context scores. We offer a provisional explanation for this compression effect.
Compositionality, Synonymy, and the Systematic Representation of Meaning
Jan 09, 2000In a recent issue of Linguistics and Philosophy Kasmi and Pelletier (1998) (K&P), and Westerstahl (1998) criticize Zadrozny's (1994) argument that any semantics can be represented compositionally. The argument is based upon Zadrozny's theorem that every meaning function m can be encoded by a function \mu such that (i) for any expression E of a specified language L, m(E) can be recovered from \mu(E), and (ii) \mu is a homomorphism from the syntactic structures of L to interpretations of L. In both cases, the primary motivation for the objections brought against Zadrozny's argument is the view that his encoding of the original meaning function does not properly reflect the synonymy relations posited for the language. In this paper, we argue that these technical criticisms do not go through. In particular, we prove that \mu properly encodes synonymy relations, i.e. if two expressions are synonymous, then their compositional meanings are identical. This corrects some misconceptions about the function \mu, e.g. Janssen (1997). We suggest that the reason that semanticists have been anxious to preserve compositionality as a significant constraint on semantic theory is that it has been mistakenly regarded as a condition that must be satisfied by any theory that sustains a systematic connection between the meaning of an expression and the meanings of its parts. Recent developments in formal and computational semantics show that systematic theories of meanings need not be compositional.