 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans vs Vision-Language Models: A Unified Measure of Narrative Coherence
Mar 26, 2026We study narrative coherence in visually grounded stories by comparing human-written narratives with those generated by vision-language models (VLMs) on the Visual Writing Prompts corpus. Using a set of metrics that capture different aspects of narrative coherence, including coreference, discourse relation types, topic continuity, character persistence, and multimodal character grounding, we compute a narrative coherence score. We find that VLMs show broadly similar coherence profiles that differ systematically from those of humans. In addition, differences for individual measures are often subtle, but they become clearer when considered jointly. Overall, our results indicate that, despite human-like surface fluency, model narratives exhibit systematic differences from those of humans in how they organise discourse across a visually grounded story. Our code is available at https://github.com/GU-CLASP/coherence-driven-humans.
Predicting Sentence Acceptability Judgments in Multimodal Contexts
Feb 24, 2026Previous work has examined the capacity of deep neural networks (DNNs), particularly transformers, to predict human sentence acceptability judgments, both independently of context, and in document contexts. We consider the effect of prior exposure to visual images (i.e., visual context) on these judgments for humans and large language models (LLMs). Our results suggest that, in contrast to textual context, visual images appear to have little if any impact on human acceptability ratings. However, LLMs display the compression effect seen in previous work on human judgments in document contexts. Different sorts of LLMs are able to predict human acceptability judgments to a high degree of accuracy, but in general, their performance is slightly better when visual contexts are removed. Moreover, the distribution of LLM judgments varies among models, with Qwen resembling human patterns, and others diverging from them. LLM-generated predictions on sentence acceptability are highly correlated with their normalised log probabilities in general. However, the correlations decrease when visual contexts are present, suggesting that a higher gap exists between the internal representations of LLMs and their generated predictions in the presence of visual contexts. Our experimental work suggests interesting points of similarity and of difference between human and LLM processing of sentences in multimodal contexts.
Surprisal reveals diversity gaps in image captioning and different scorers change the story
Nov 06, 2025We quantify linguistic diversity in image captioning with surprisal variance - the spread of token-level negative log-probabilities within a caption set. On the MSCOCO test set, we compare five state-of-the-art vision-and-language LLMs, decoded with greedy and nucleus sampling, to human captions. Measured with a caption-trained n-gram LM, humans display roughly twice the surprisal variance of models, but rescoring the same captions with a general-language model reverses the pattern. Our analysis introduces the surprisal-based diversity metric for image captioning. We show that relying on a single scorer can completely invert conclusions, thus, robust diversity evaluation must report surprisal under several scorers.
Coreference as an indicator of context scope in multimodal narrative
Mar 07, 2025We demonstrate that large multimodal language models differ substantially from humans in the distribution of coreferential expressions in a visual storytelling task. We introduce a number of metrics to quantify the characteristics of coreferential patterns in both human- and machine-written texts. Humans distribute coreferential expressions in a way that maintains consistency across texts and images, interleaving references to different entities in a highly varied way. Machines are less able to track mixed references, despite achieving perceived improvements in generation quality.
Describe me an Aucklet: Generating Grounded Perceptual Category Descriptions
Mar 08, 2023Human language users can generate descriptions of perceptual concepts beyond instance-level representations and also use such descriptions to learn provisional class-level representations. However, the ability of computational models to learn and operate with class representations is under-investigated in the language-and-vision field. In this paper, we train separate neural networks to generate and interpret class-level descriptions. We then use the zero-shot classification performance of the interpretation model as a measure of communicative success and class-level conceptual grounding. We investigate the performance of prototype- and exemplar-based neural representations grounded category description. Finally, we show that communicative success reveals performance issues in the generation model that are not captured by traditional intrinsic NLG evaluation metrics, and argue that these issues can be traced to a failure to properly ground language in vision at the class level. We observe that the interpretation model performs better with descriptions that are low in diversity on the class level, possibly indicating a strong reliance on frequently occurring features.
We went to look for meaning and all we got were these lousy representations: aspects of meaning representation for computational semantics
Sep 10, 2021In this paper we examine different meaning representations that are commonly used in different natural language applications today and discuss their limits, both in terms of the aspects of the natural language meaning they are modelling and in terms of the aspects of the application for which they are used.
MeetUp! A Corpus of Joint Activity Dialogues in a Visual Environment
Jul 11, 2019
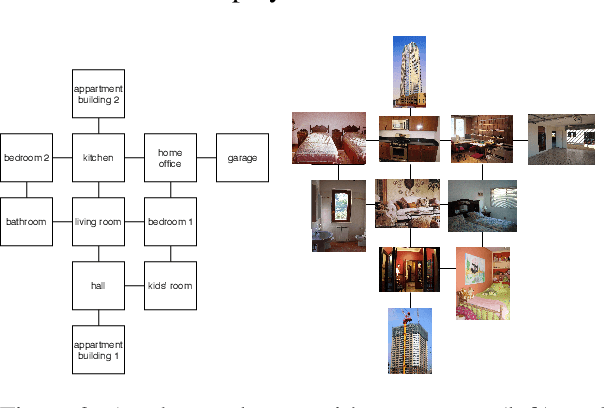
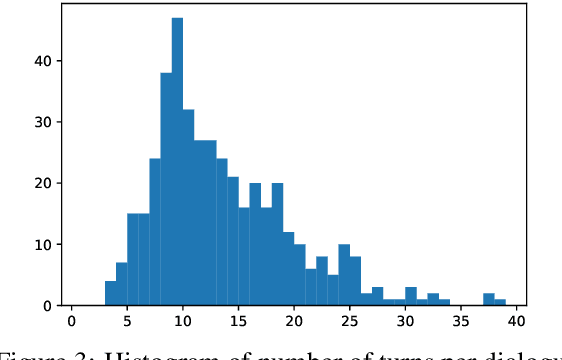
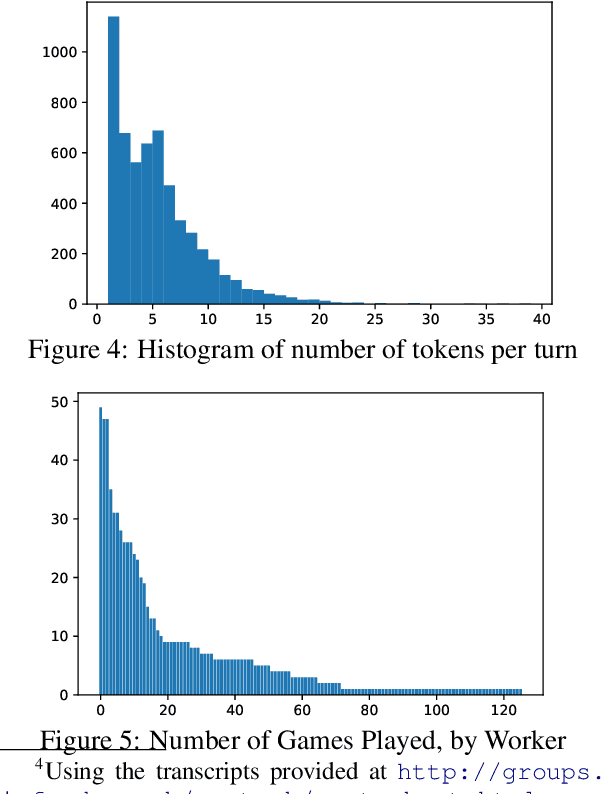
Building computer systems that can converse about their visual environment is one of the oldest concerns of research in Artificial Intelligence and Computational Linguistics (see, for example, Winograd's 1972 SHRDLU system). Only recently, however, have methods from computer vision and natural language processing become powerful enough to make this vision seem more attainable. Pushed especially by developments in computer vision, many data sets and collection environments have recently been published that bring together verbal interaction and visual processing. Here, we argue that these datasets tend to oversimplify the dialogue part, and we propose a task---MeetUp!---that requires both visual and conversational grounding, and that makes stronger demands on representations of the discourse. MeetUp! is a two-player coordination game where players move in a visual environment, with the objective of finding each other. To do so, they must talk about what they see, and achieve mutual understanding. We describe a data collection and show that the resulting dialogues indeed exhibit the dialogue phenomena of interest, while also challenging the language & vision aspect.