 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeetUp! A Corpus of Joint Activity Dialogues in a Visual Environment
Paper and Code

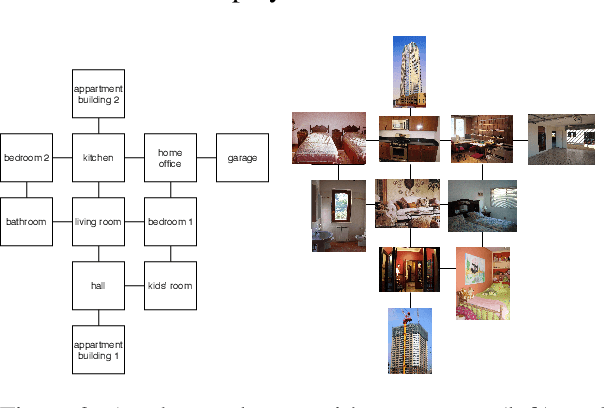
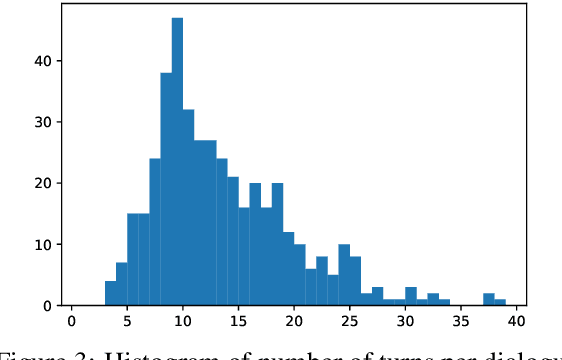
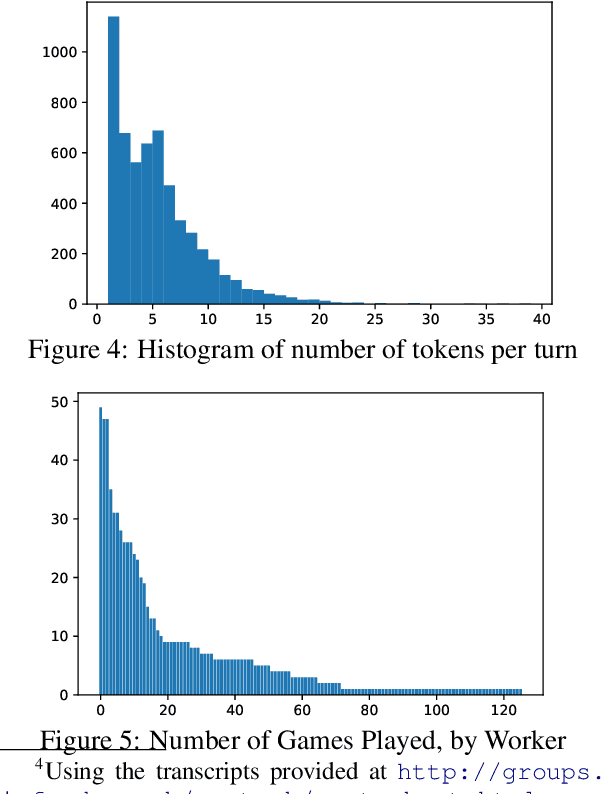
Building computer systems that can converse about their visual environment is one of the oldest concerns of research in Artificial Intelligence and Computational Linguistics (see, for example, Winograd's 1972 SHRDLU system). Only recently, however, have methods from computer vision and natural language processing become powerful enough to make this vision seem more attainable. Pushed especially by developments in computer vision, many data sets and collection environments have recently been published that bring together verbal interaction and visual processing. Here, we argue that these datasets tend to oversimplify the dialogue part, and we propose a task---MeetUp!---that requires both visual and conversational grounding, and that makes stronger demands on representations of the discourse. MeetUp! is a two-player coordination game where players move in a visual environment, with the objective of finding each other. To do so, they must talk about what they see, and achieve mutual understanding. We describe a data collection and show that the resulting dialogues indeed exhibit the dialogue phenomena of interest, while also challenging the language & vision aspect.