 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprisal reveals diversity gaps in image captioning and different scorers change the story
Nov 06, 2025We quantify linguistic diversity in image captioning with surprisal variance - the spread of token-level negative log-probabilities within a caption set. On the MSCOCO test set, we compare five state-of-the-art vision-and-language LLMs, decoded with greedy and nucleus sampling, to human captions. Measured with a caption-trained n-gram LM, humans display roughly twice the surprisal variance of models, but rescoring the same captions with a general-language model reverses the pattern. Our analysis introduces the surprisal-based diversity metric for image captioning. We show that relying on a single scorer can completely invert conclusions, thus, robust diversity evaluation must report surprisal under several scorers.
Grandma Karl is 27 years old -- research agenda for pseudonymization of research data
Aug 30, 2023

Accessibility of research data is critical for advances in many research fields, but textual data often cannot be shared due to the personal and sensitive information which it contains, e.g names or political opinions. General Data Protection Regulation (GDPR) suggests pseudonymization as a solution to secure open access to research data, but we need to learn more about pseudonymization as an approach before adopting it for manipulation of research data. This paper outlines a research agenda within pseudonymization, namely need of studies into the effects of pseudonymization on unstructured data in relation to e.g. readability and language assessment, as well as the effectiveness of pseudonymization as a way of protecting writer identity, while also exploring different ways of developing context-sensitive algorithms for detection, labelling and replacement of personal information in unstructured data. The recently granted project on pseudonymization Grandma Karl is 27 years old addresses exactly those challenges.
Multi-task recommendation system for scientific papers with high-way networks
Apr 21, 2022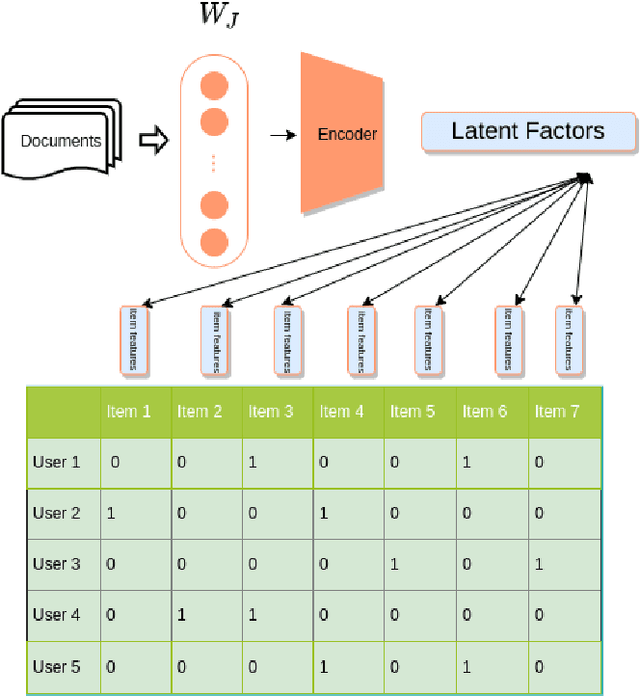
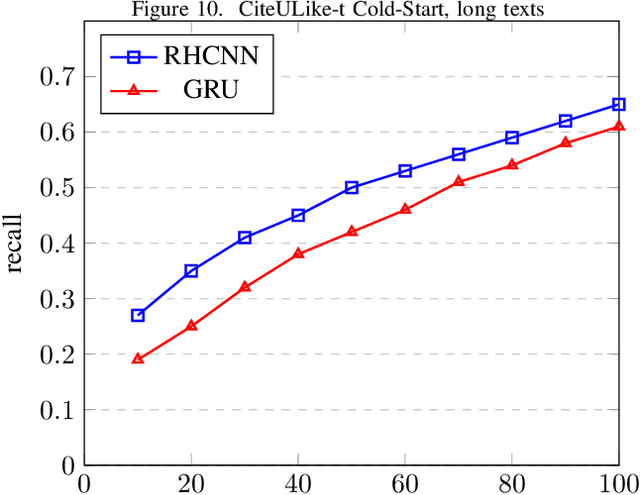
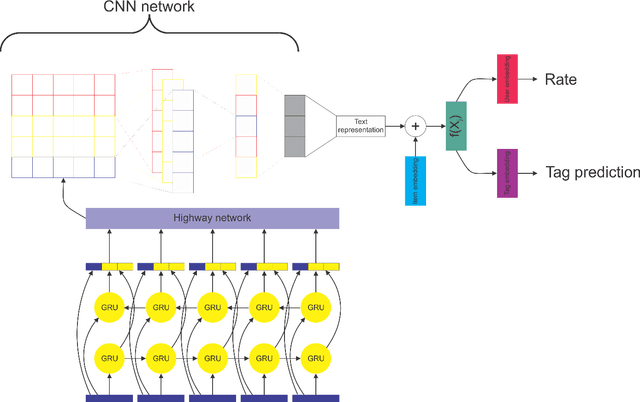
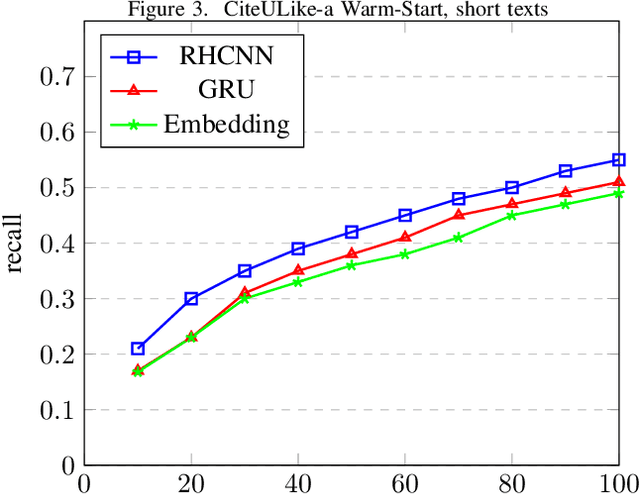
Finding and selecting the most relevant scientific papers from a large number of papers written in a research community is one of the key challenges for researchers these days. As we know, much information around research interest for scholars and academicians belongs to papers they read. Analysis and extracting contextual features from these papers could help us to suggest the most related paper to them. In this paper, we present a multi-task recommendation system (RS) that predicts a paper recommendation and generates its meta-data such as keywords. The system is implemented as a three-stage deep neural network encoder that tries to maps longer sequences of text to an embedding vector and learns simultaneously to predict the recommendation rate for a particular user and the paper's keywords. The motivation behind this approach is that the paper's topics expressed as keywords are a useful predictor of preferences of researchers. To achieve this goal, we use a system combination of RNNs, Highway and Convolutional Neural Networks to train end-to-end a context-aware collaborative matrix. Our application uses Highway networks to train the system very deep, combine the benefits of RNN and CNN to find the most important factor and make latent representation. Highway Networks allow us to enhance the traditional RNN and CNN pipeline by learning more sophisticated semantic structural representations. Using this method we can also overcome the cold start problem and learn latent features over large sequences of text.
We went to look for meaning and all we got were these lousy representations: aspects of meaning representation for computational semantics
Sep 10, 2021In this paper we examine different meaning representations that are commonly used in different natural language applications today and discuss their limits, both in terms of the aspects of the natural language meaning they are modelling and in terms of the aspects of the application for which they are used.
What is not where: the challenge of integrating spatial representations into deep learning architectures
Jul 21, 2018
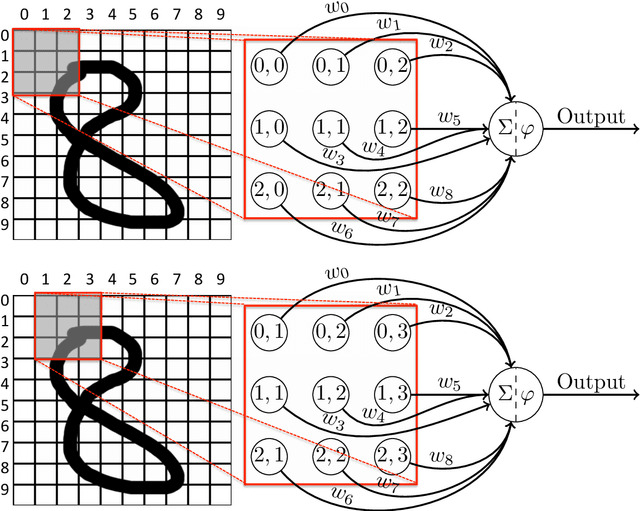
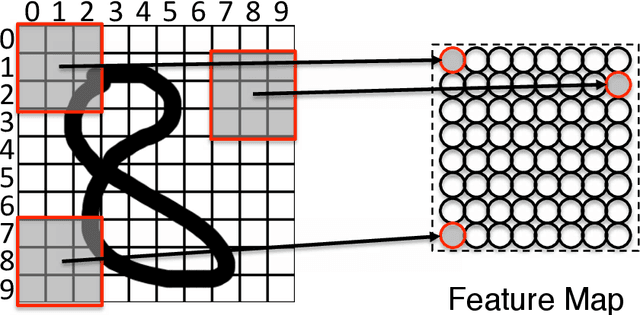
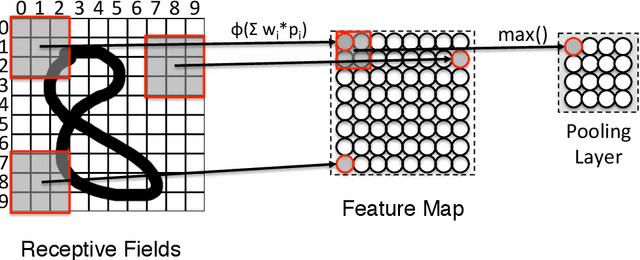
This paper examines to what degree current deep learning architectures for image caption generation capture spatial language. On the basis of the evaluation of examples of generated captions from the literature we argue that systems capture what objects are in the image data but not where these objects are located: the captions generated by these systems are the output of a language model conditioned on the output of an object detector that cannot capture fine-grained location information. Although language models provide useful knowledge for image captions, we argue that deep learning image captioning architectures should also model geometric relations between objects.
Modular Mechanistic Networks: On Bridging Mechanistic and Phenomenological Models with Deep Neural Networks in Natural Language Processing
Jul 21, 2018

Natural language processing (NLP) can be done using either top-down (theory driven) and bottom-up (data driven) approaches, which we call mechanistic and phenomenological respectively. The approaches are frequently considered to stand in opposition to each other. Examining some recent approaches in deep learning we argue that deep neural networks incorporate both perspectives and, furthermore, that leveraging this aspect of deep learning may help in solving complex problems within language technology, such as modelling language and perception in the domain of spatial cognition.
* 11 pages, 1 figure, Appears in CLASP Papers in Computational Linguistics Vol. 1: Proceedings of the Conference on Logic and Machine Learning in Natural Language (LaML 2017), pp. 1-11