 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans vs Vision-Language Models: A Unified Measure of Narrative Coherence
Mar 26, 2026We study narrative coherence in visually grounded stories by comparing human-written narratives with those generated by vision-language models (VLMs) on the Visual Writing Prompts corpus. Using a set of metrics that capture different aspects of narrative coherence, including coreference, discourse relation types, topic continuity, character persistence, and multimodal character grounding, we compute a narrative coherence score. We find that VLMs show broadly similar coherence profiles that differ systematically from those of humans. In addition, differences for individual measures are often subtle, but they become clearer when considered jointly. Overall, our results indicate that, despite human-like surface fluency, model narratives exhibit systematic differences from those of humans in how they organise discourse across a visually grounded story. Our code is available at https://github.com/GU-CLASP/coherence-driven-humans.
Coreference as an indicator of context scope in multimodal narrative
Mar 07, 2025We demonstrate that large multimodal language models differ substantially from humans in the distribution of coreferential expressions in a visual storytelling task. We introduce a number of metrics to quantify the characteristics of coreferential patterns in both human- and machine-written texts. Humans distribute coreferential expressions in a way that maintains consistency across texts and images, interleaving references to different entities in a highly varied way. Machines are less able to track mixed references, despite achieving perceived improvements in generation quality.
A surprisal oracle for when every layer counts
Dec 04, 2024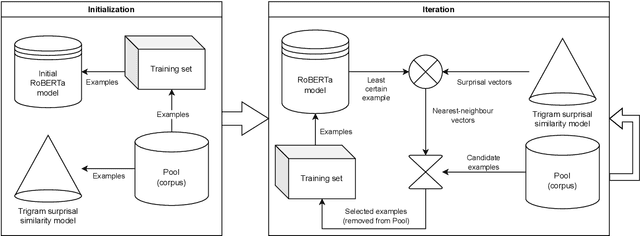
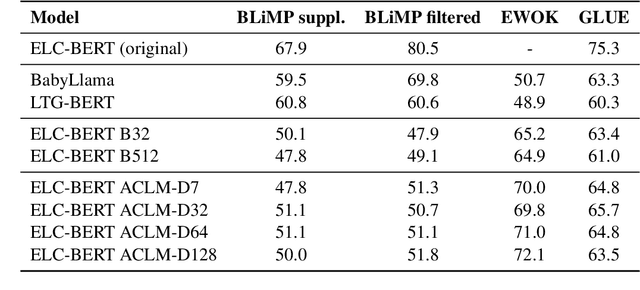
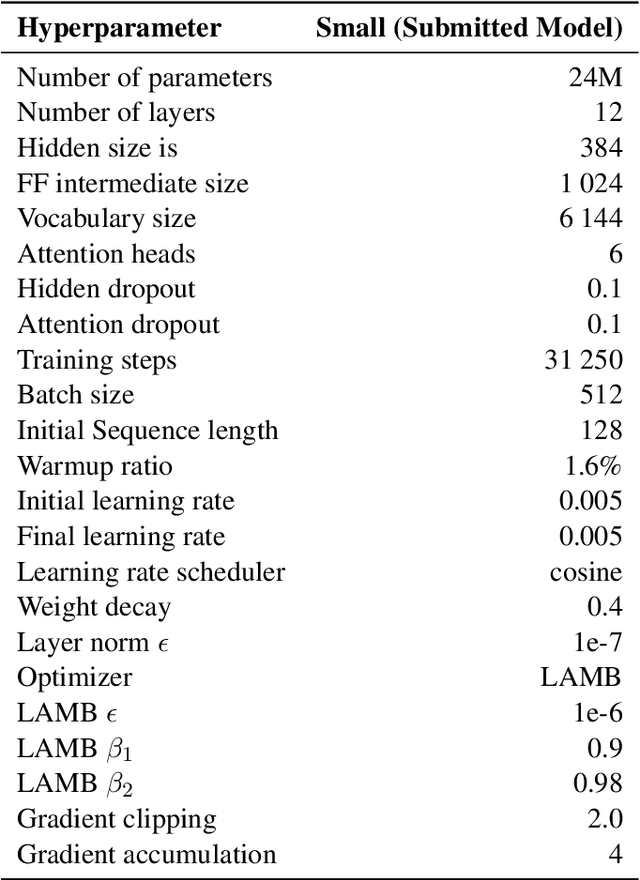
Active Curriculum Language Modeling (ACLM; Hong et al., 2023) is a learner directed approach to training a language model. We proposed the original version of this process in our submission to the BabyLM 2023 task, and now we propose an updated ACLM process for the BabyLM 2024 task. ACLM involves an iteratively- and dynamically-constructed curriculum informed over the training process by a model of uncertainty; other training items that are similarly uncertain to a least certain candidate item are prioritized. Our new process improves the similarity model so that it is more dynamic, and we run ACLM over the most successful model from the BabyLM 2023 task: ELC-BERT (Charpentier and Samuel, 2023). We find that while our models underperform on fine-grained grammatical inferences, they outperform the BabyLM 2024 official base-lines on common-sense and world-knowledge tasks. We make our code available at https: //github.com/asayeed/ActiveBaby.
Visual Writing Prompts: Character-Grounded Story Generation with Curated Image Sequences
Jan 20, 2023Current work on image-based story generation suffers from the fact that the existing image sequence collections do not have coherent plots behind them. We improve visual story generation by producing a new image-grounded dataset, Visual Writing Prompts (VWP). VWP contains almost 2K selected sequences of movie shots, each including 5-10 images. The image sequences are aligned with a total of 12K stories which were collected via crowdsourcing given the image sequences and a set of grounded characters from the corresponding image sequence. Our new image sequence collection and filtering process has allowed us to obtain stories that are more coherent and have more narrativity compared to previous work. We also propose a character-based story generation model driven by coherence as a strong baseline. Evaluations show that our generated stories are more coherent, visually grounded, and have more narrativity than stories generated with the current state-of-the-art model.
Multi-Task Learning for Joint Semantic Role and Proto-Role Labeling
Oct 13, 2022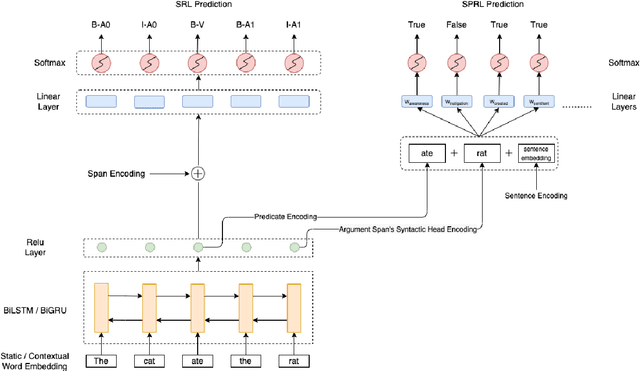
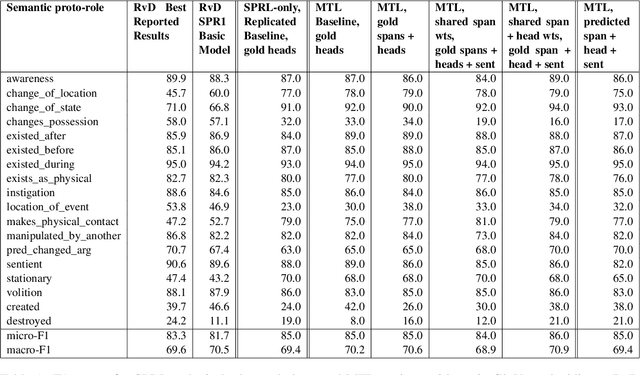
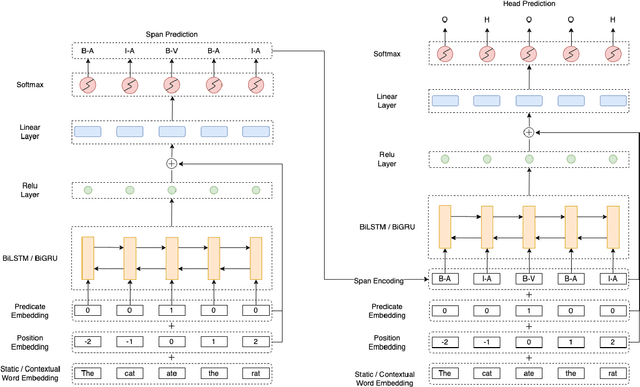
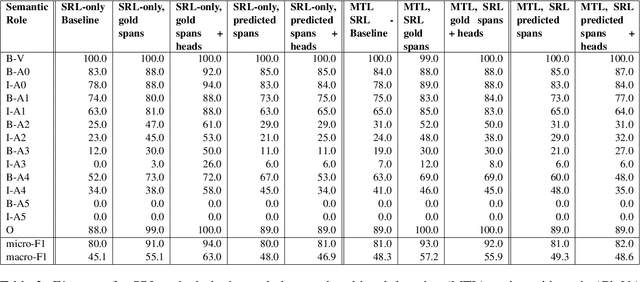
We put forward an end-to-end multi-step machine learning model which jointly labels semantic roles and the proto-roles of Dowty (1991), given a sentence and the predicates therein. Our best architecture first learns argument spans followed by learning the argument's syntactic heads. This information is shared with the next steps for predicting the semantic roles and proto-roles. We also experiment with transfer learning from argument and head prediction to role and proto-role labeling. We compare using static and contextual embeddings for words, arguments, and sentences. Unlike previous work, our model does not require pre-training or fine-tuning on additional tasks, beyond using off-the-shelf (static or contextual) embeddings and supervision. It also does not require argument spans, their semantic roles, and/or their gold syntactic heads as additional input, because it learns to predict all these during training. Our multi-task learning model raises the state-of-the-art predictions for most proto-roles.
Where's the Learning in Representation Learning for Compositional Semantics and the Case of Thematic Fit
Aug 09, 2022

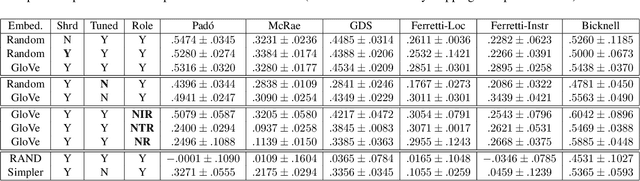
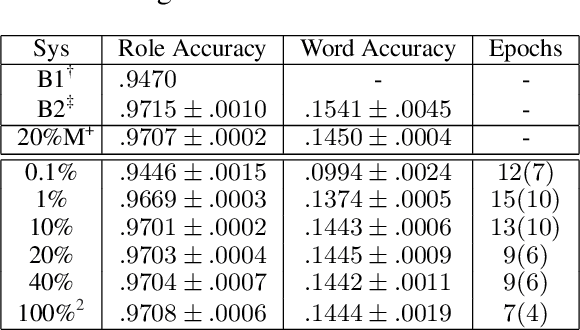
Observing that for certain NLP tasks, such as semantic role prediction or thematic fit estimation, random embeddings perform as well as pretrained embeddings, we explore what settings allow for this and examine where most of the learning is encoded: the word embeddings, the semantic role embeddings, or ``the network''. We find nuanced answers, depending on the task and its relation to the training objective. We examine these representation learning aspects in multi-task learning, where role prediction and role-filling are supervised tasks, while several thematic fit tasks are outside the models' direct supervision. We observe a non-monotonous relation between some tasks' quality score and the training data size. In order to better understand this observation, we analyze these results using easier, per-verb versions of these tasks.
Thematic fit bits: Annotation quality and quantity for event participant representation
May 13, 2021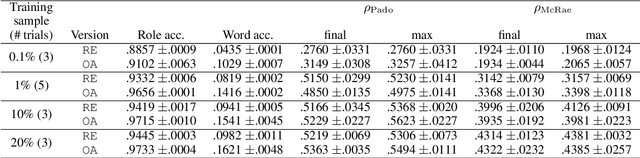
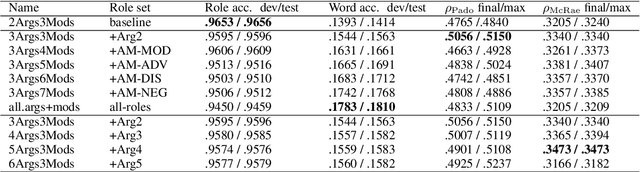
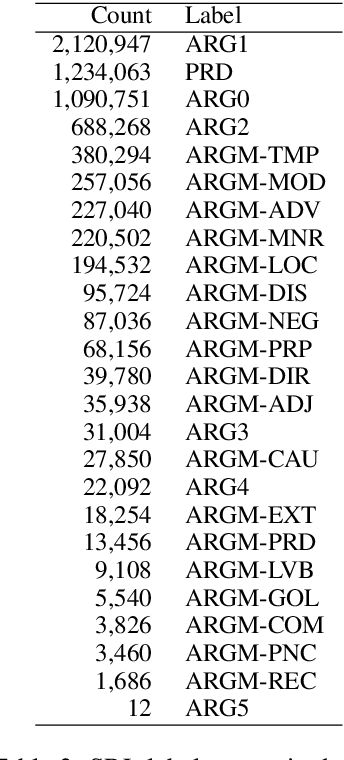

Modeling thematic fit (a verb--argument compositional semantics task) currently requires a very large burden of data. We take a high-performing neural approach to modeling verb--argument fit, previously trained on a linguistically machine-annotated large corpus, and replace corpus layers with output from higher-quality taggers. Contrary to popular beliefs that, in the deep learning era, more data is as effective as higher quality annotation, we discover that higher annotation quality dramatically reduces our data requirement while demonstrating better supervised predicate-argument classification. But in applying the model to a psycholinguistic task outside the training objective, we saw only small gains in one of two thematic fit estimation tasks, and none in the other. We replicate previous studies while modifying certain role representation details, and set a new state-of-the-art in event modeling, using a fraction of the data.