 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere's the Learning in Representation Learning for Compositional Semantics and the Case of Thematic Fit
Paper and Code


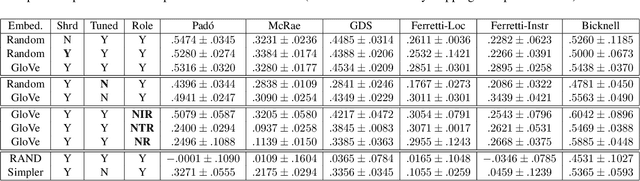
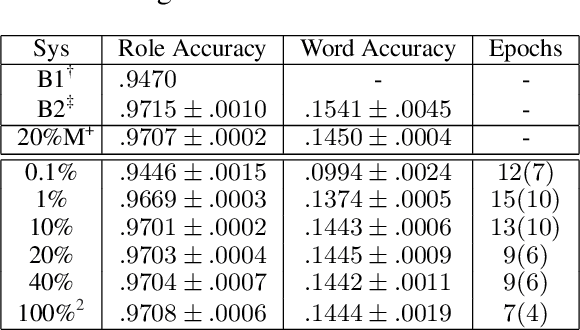
Observing that for certain NLP tasks, such as semantic role prediction or thematic fit estimation, random embeddings perform as well as pretrained embeddings, we explore what settings allow for this and examine where most of the learning is encoded: the word embeddings, the semantic role embeddings, or ``the network''. We find nuanced answers, depending on the task and its relation to the training objective. We examine these representation learning aspects in multi-task learning, where role prediction and role-filling are supervised tasks, while several thematic fit tasks are outside the models' direct supervision. We observe a non-monotonous relation between some tasks' quality score and the training data size. In order to better understand this observation, we analyze these results using easier, per-verb versions of these tasks.