 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Autoregressive LLM Knowledge of Thematic Fit in Event Representation
Oct 19, 2024



The thematic fit estimation task measures the compatibility between a predicate (typically a verb), an argument (typically a noun phrase), and a specific semantic role assigned to the argument. Previous state-of-the-art work has focused on modeling thematic fit through distributional or neural models of event representation, trained in a supervised fashion with indirect labels. In this work, we assess whether pre-trained autoregressive LLMs possess consistent, expressible knowledge about thematic fit. We evaluate both closed and open state-of-the-art LLMs on several psycholinguistic datasets, along three axes: (1) Reasoning Form: multi-step logical reasoning (chain-of-thought prompting) vs. simple prompting. (2) Input Form: providing context (generated sentences) vs. raw tuples <predicate, argument, role>. (3) Output Form: categorical vs. numeric. Our results show that chain-of-thought reasoning is more effective on datasets with self-explanatory semantic role labels, especially Location. Generated sentences helped only in few settings, and lowered results in many others. Predefined categorical (compared to numeric) output raised GPT's results across the board with few exceptions, but lowered Llama's. We saw that semantically incoherent generated sentences, which the models lack the ability to consistently filter out, hurt reasoning and overall performance too. Our GPT-powered methods set new state-of-the-art on all tested datasets.
Multi-Task Learning for Joint Semantic Role and Proto-Role Labeling
Oct 13, 2022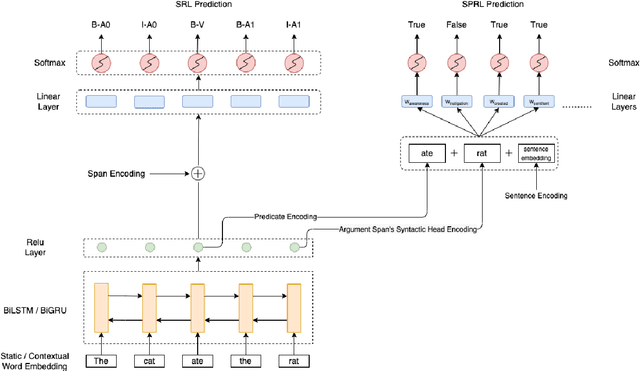
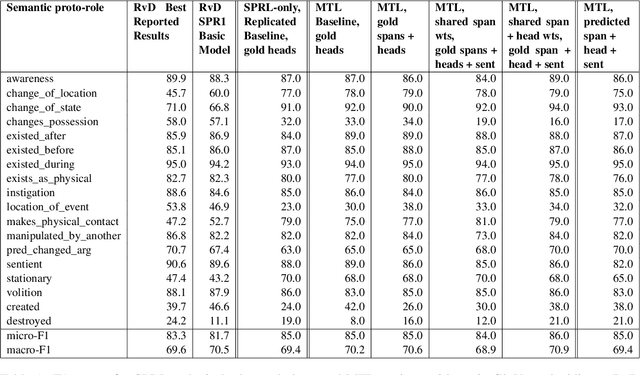
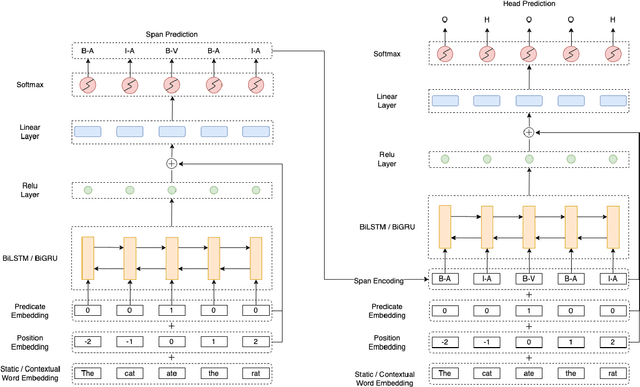
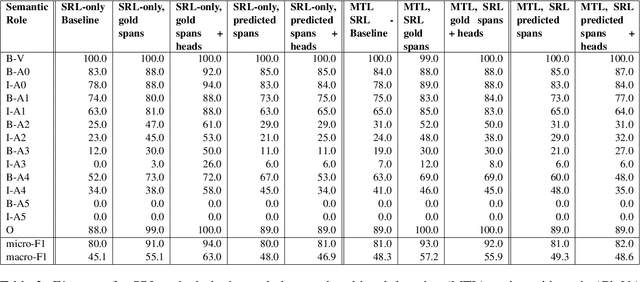
We put forward an end-to-end multi-step machine learning model which jointly labels semantic roles and the proto-roles of Dowty (1991), given a sentence and the predicates therein. Our best architecture first learns argument spans followed by learning the argument's syntactic heads. This information is shared with the next steps for predicting the semantic roles and proto-roles. We also experiment with transfer learning from argument and head prediction to role and proto-role labeling. We compare using static and contextual embeddings for words, arguments, and sentences. Unlike previous work, our model does not require pre-training or fine-tuning on additional tasks, beyond using off-the-shelf (static or contextual) embeddings and supervision. It also does not require argument spans, their semantic roles, and/or their gold syntactic heads as additional input, because it learns to predict all these during training. Our multi-task learning model raises the state-of-the-art predictions for most proto-roles.
Where's the Learning in Representation Learning for Compositional Semantics and the Case of Thematic Fit
Aug 09, 2022

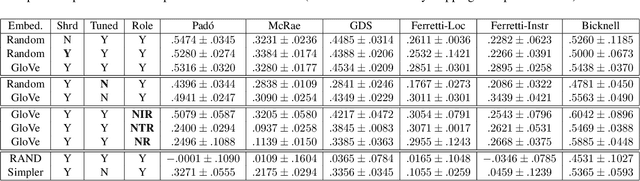
Observing that for certain NLP tasks, such as semantic role prediction or thematic fit estimation, random embeddings perform as well as pretrained embeddings, we explore what settings allow for this and examine where most of the learning is encoded: the word embeddings, the semantic role embeddings, or ``the network''. We find nuanced answers, depending on the task and its relation to the training objective. We examine these representation learning aspects in multi-task learning, where role prediction and role-filling are supervised tasks, while several thematic fit tasks are outside the models' direct supervision. We observe a non-monotonous relation between some tasks' quality score and the training data size. In order to better understand this observation, we analyze these results using easier, per-verb versions of these tasks.
Thematic fit bits: Annotation quality and quantity for event participant representation
May 13, 2021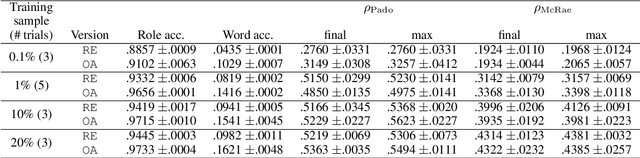
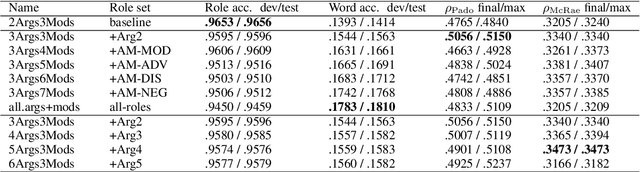
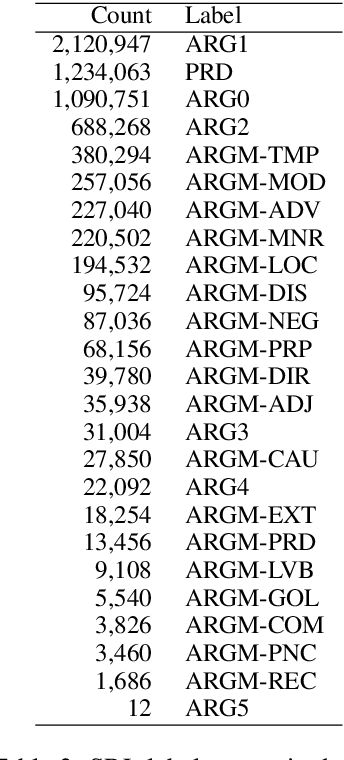

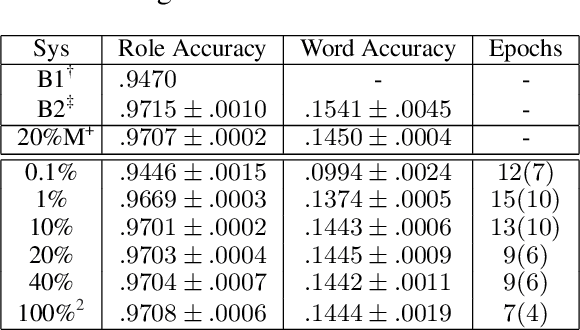
Modeling thematic fit (a verb--argument compositional semantics task) currently requires a very large burden of data. We take a high-performing neural approach to modeling verb--argument fit, previously trained on a linguistically machine-annotated large corpus, and replace corpus layers with output from higher-quality taggers. Contrary to popular beliefs that, in the deep learning era, more data is as effective as higher quality annotation, we discover that higher annotation quality dramatically reduces our data requirement while demonstrating better supervised predicate-argument classification. But in applying the model to a psycholinguistic task outside the training objective, we saw only small gains in one of two thematic fit estimation tasks, and none in the other. We replicate previous studies while modifying certain role representation details, and set a new state-of-the-art in event modeling, using a fraction of the data.