 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Joint Semantic Role and Proto-Role Labeling
Oct 13, 2022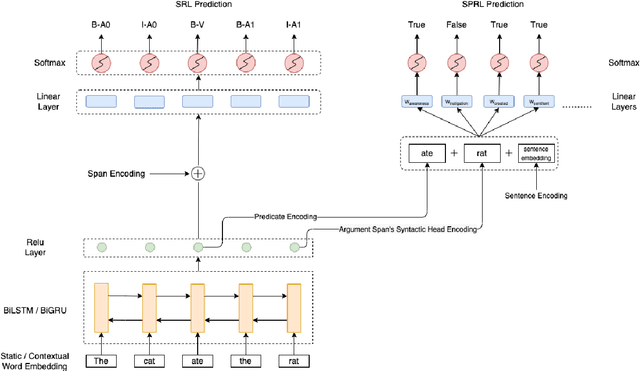
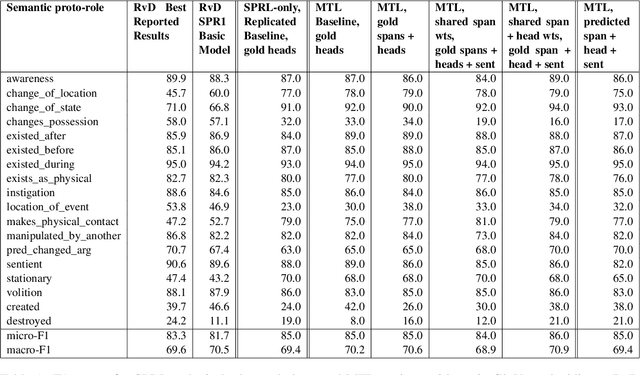
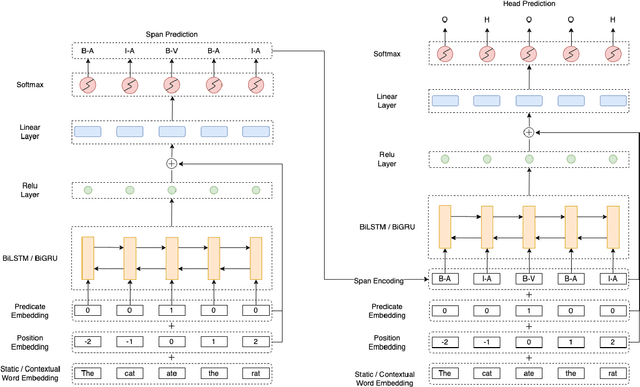
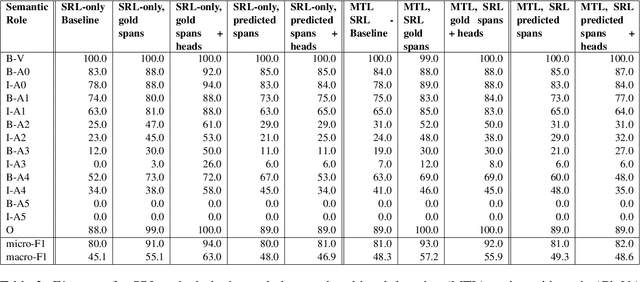
We put forward an end-to-end multi-step machine learning model which jointly labels semantic roles and the proto-roles of Dowty (1991), given a sentence and the predicates therein. Our best architecture first learns argument spans followed by learning the argument's syntactic heads. This information is shared with the next steps for predicting the semantic roles and proto-roles. We also experiment with transfer learning from argument and head prediction to role and proto-role labeling. We compare using static and contextual embeddings for words, arguments, and sentences. Unlike previous work, our model does not require pre-training or fine-tuning on additional tasks, beyond using off-the-shelf (static or contextual) embeddings and supervision. It also does not require argument spans, their semantic roles, and/or their gold syntactic heads as additional input, because it learns to predict all these during training. Our multi-task learning model raises the state-of-the-art predictions for most proto-roles.