 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Data Corruption Affect Natural Language Understanding Models? A Study on GLUE datasets
Paper and Code
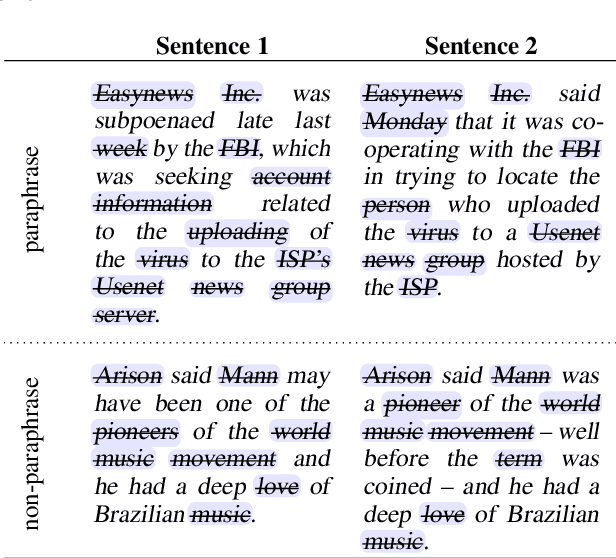
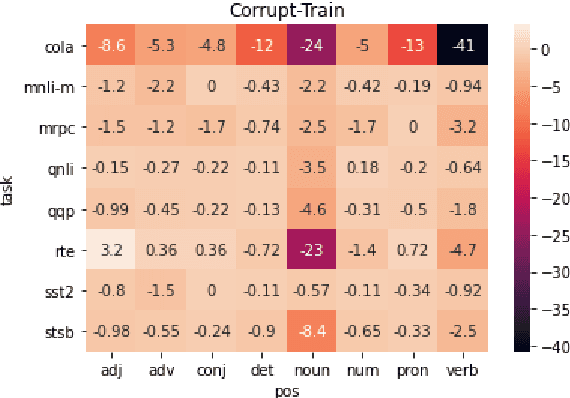

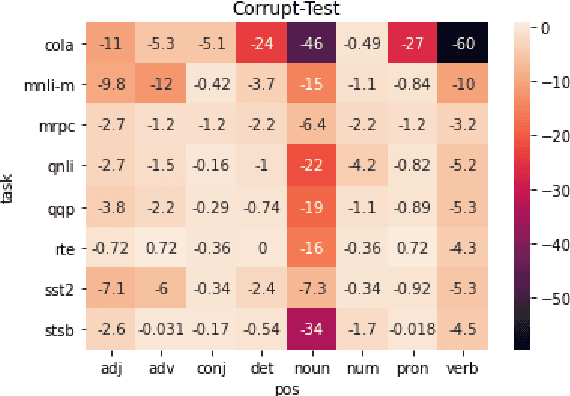
A central question in natural language understanding (NLU) research is whether high performance demonstrates the models' strong reasoning capabilities. We present an extensive series of controlled experiments where pre-trained language models are exposed to data that have undergone specific corruption transformations. The transformations involve removing instances of specific word classes and often lead to non-sensical sentences. Our results show that performance remains high for most GLUE tasks when the models are fine-tuned or tested on corrupted data, suggesting that the models leverage other cues for prediction even in non-sensical contexts. Our proposed data transformations can be used as a diagnostic tool for assessing the extent to which a specific dataset constitutes a proper testbed for evaluating models' language understanding capabilities.