 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARWI: Arabic Write and Improve
Apr 16, 2025Although Arabic is spoken by over 400 million people, advanced Arabic writing assistance tools remain limited. To address this gap, we present ARWI, a new writing assistant that helps learners improve essay writing in Modern Standard Arabic. ARWI is the first publicly available Arabic writing assistant to include a prompt database for different proficiency levels, an Arabic text editor, state-of-the-art grammatical error detection and correction, and automated essay scoring aligned with the Common European Framework of Reference standards for language attainment. Moreover, ARWI can be used to gather a growing auto-annotated corpus, facilitating further research on Arabic grammar correction and essay scoring, as well as profiling patterns of errors made by native speakers and non-native learners. A preliminary user study shows that ARWI provides actionable feedback, helping learners identify grammatical gaps, assess language proficiency, and guide improvement.
Commonsense Reasoning in Arab Culture
Feb 18, 2025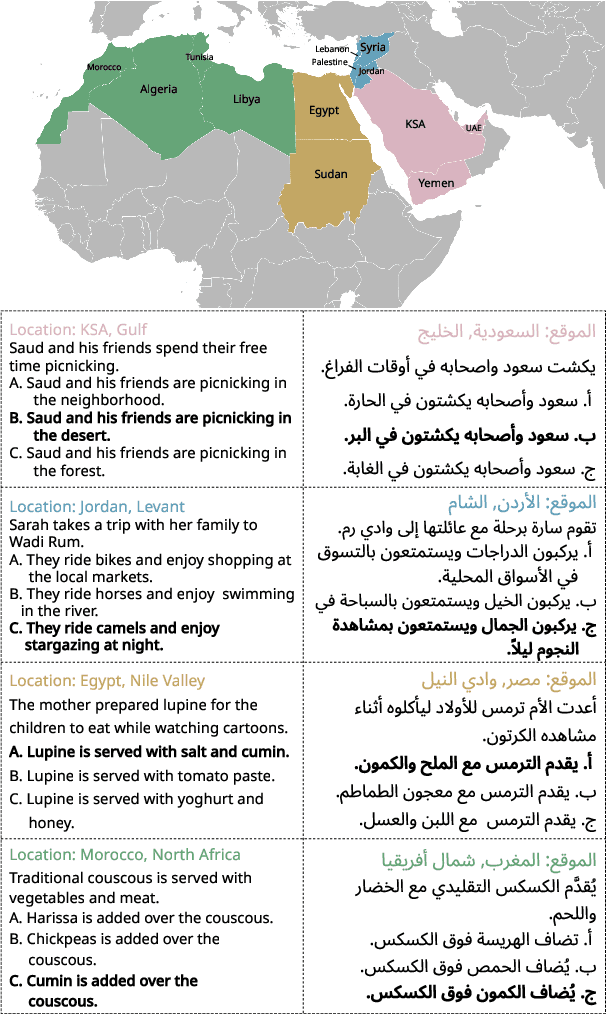

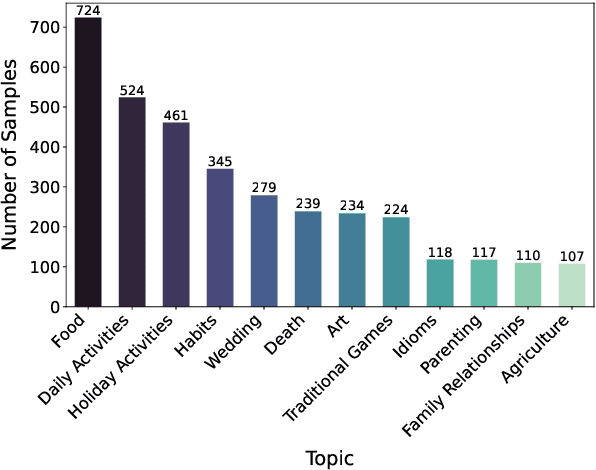
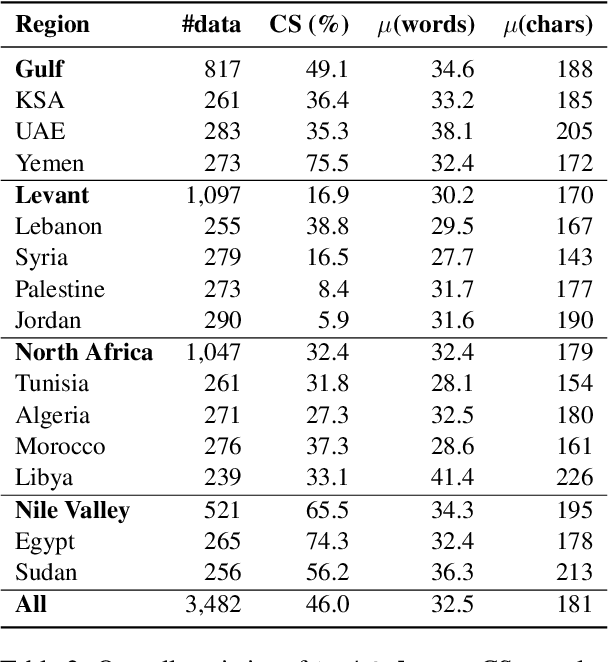
Despite progress in Arabic large language models, such as Jais and AceGPT, their evaluation on commonsense reasoning has largely relied on machine-translated datasets, which lack cultural depth and may introduce Anglocentric biases. Commonsense reasoning is shaped by geographical and cultural contexts, and existing English datasets fail to capture the diversity of the Arab world. To address this, we introduce \datasetname, a commonsense reasoning dataset in Modern Standard Arabic (MSA), covering cultures of 13 countries across the Gulf, Levant, North Africa, and the Nile Valley. The dataset was built from scratch by engaging native speakers to write and validate culturally relevant questions for their respective countries. \datasetname spans 12 daily life domains with 54 fine-grained subtopics, reflecting various aspects of social norms, traditions, and everyday experiences. Zero-shot evaluations show that open-weight language models with up to 32B parameters struggle to comprehend diverse Arab cultures, with performance varying across regions. These findings highlight the need for more culturally aware models and datasets tailored to the Arabic-speaking world.
GRDD: A Dataset for Greek Dialectal NLP
Aug 01, 2023In this paper, we present a dataset for the computational study of a number of Modern Greek dialects. It consists of raw text data from four dialects of Modern Greek, Cretan, Pontic, Northern Greek and Cypriot Greek. The dataset is of considerable size, albeit imbalanced, and presents the first attempt to create large scale dialectal resources of this type for Modern Greek dialects. We then use the dataset to perform dialect idefntification. We experiment with traditional ML algorithms, as well as simple DL architectures. The results show very good performance on the task, potentially revealing that the dialects in question have distinct enough characteristics allowing even simple ML models to perform well on the task. Error analysis is performed for the top performing algorithms showing that in a number of cases the errors are due to insufficient dataset cleaning.